Why MLOps Matters More Than DevOps for AI Systems
MLOps is the discipline that keeps trained models reliable after they leave the lab.
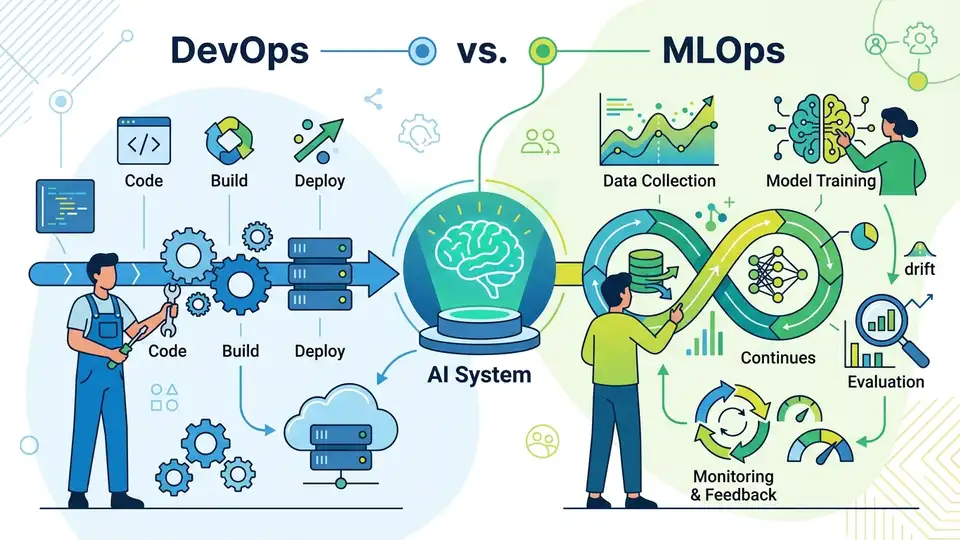
MLOps keeps trained models reproducible, monitored, and safe in production.
MLOps is worth adopting because trained models fail in ways ordinary software does not, and organizations that treat them like static code pay for it later in outages, drift, and wasted engineering time.
Models are not normal software
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
A deployed model is not just a binary with a new label. Its behavior depends on training data, feature preprocessing, random seeds, library versions, and the distribution of inputs it sees after launch. A web service can be rebuilt from source and behave the same way; a model can be retrained and still produce different results unless the entire pipeline is controlled. That is why the summary of MLOps as “DevOps for AI” is too shallow. DevOps solves delivery for code. MLOps solves lifecycle risk for artifacts that learn.
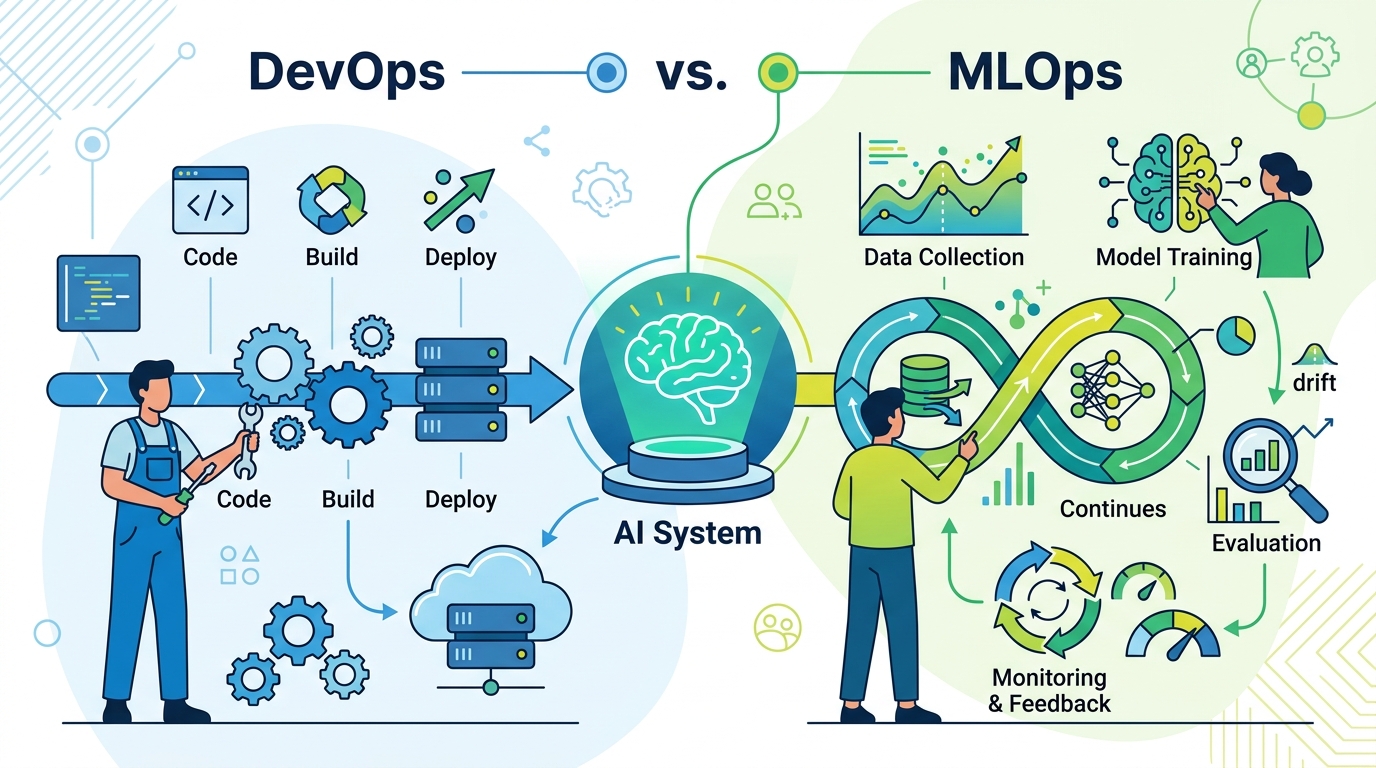
The article’s own examples make the point plainly: a model can look strong in development and then degrade quietly in production over months as input data shifts. That is not a rare edge case. It is the default failure mode when the business keeps changing but the model does not know it. If you only version the code and ignore the data, you are preserving the least important part of the system.
Manual ML operations waste real money
The business case is not abstract. TechnoLynx estimates that manual model deployment takes 2 to 4 hours of engineer time per release. If a model is retrained weekly, that becomes 100 to 200 hours per year for a single model, before you count debugging, monitoring, or rollback work. At ten models, that is roughly one to two full-time engineers spent moving artifacts around instead of improving the product. That is not process overhead. That is operational drag.
This is why organizations that delay MLOps until after they have a pile of models end up paying twice. First they pay with incident response when a model slips in quality. Then they pay again by retrofitting pipelines, registries, and monitoring under pressure. The article is right to say teams often adopt tooling too early or too late. The right time is not when the company has a machine learning strategy deck. It is when the first production model starts affecting revenue, risk, or customer experience.
Good MLOps is staged, not heroic
The four-stage maturity model in the source is the most practical part of the argument. Stage 1 is manual notebooks and SSH. Stage 2 automates training and versioning. Stage 3 automates deployment with quality gates. Stage 4 becomes self-managing, with the system deciding when to retrain and retire models. The important lesson is not the labels. It is the pacing. Jumping from Stage 1 to Stage 3 creates expensive infrastructure that teams cannot absorb.
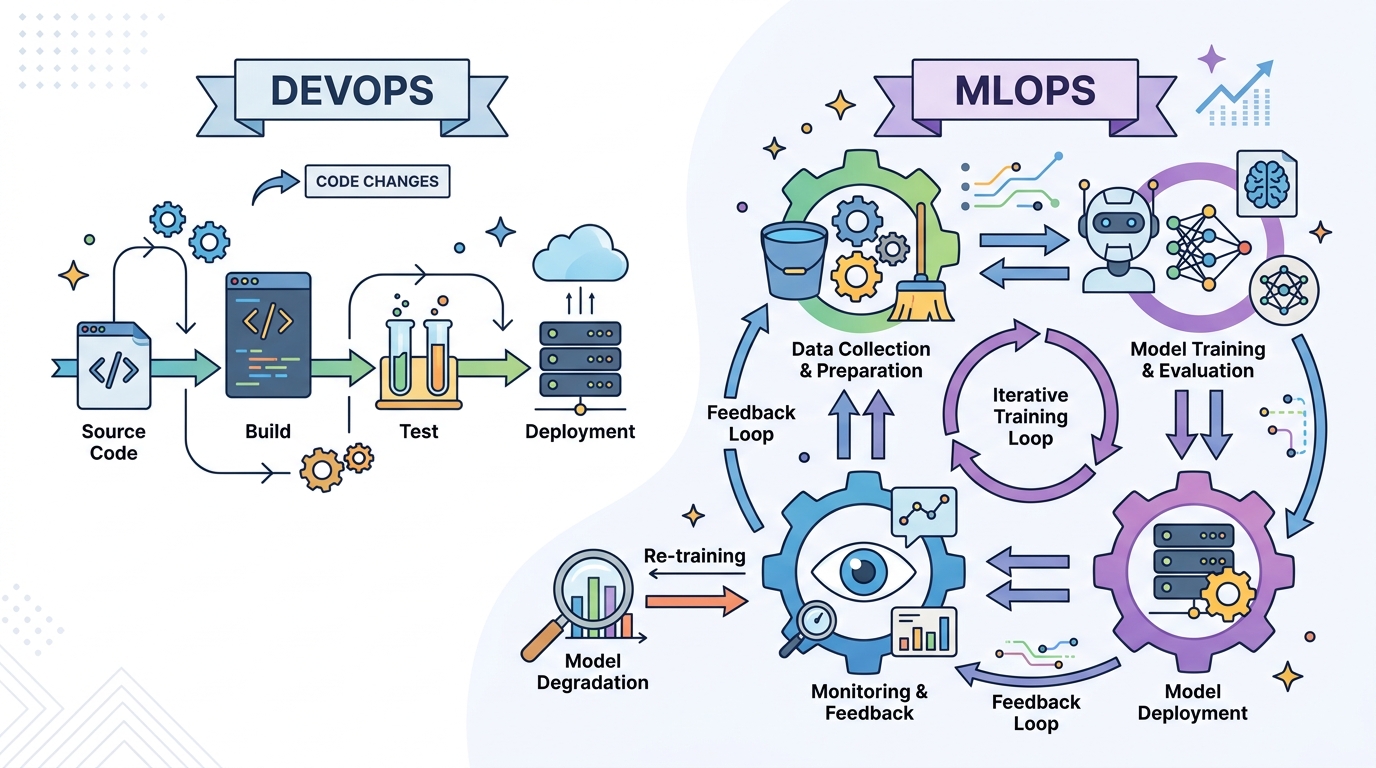
That staged approach matches how real organizations work. A small team with one or two models does not need a self-managing platform. A company with 20 models, changing data, and multiple stakeholders does. The article’s recommendation to advance one stage at a time is exactly right because maturity in MLOps is cumulative. You do not buy reliability in a single platform purchase. You earn it through repeatable training, deployment, and monitoring habits.
The counter-argument
The best objection is that MLOps can become premature bureaucracy. In a proof-of-concept phase, the team may have no production models, no retraining loop, and no meaningful monitoring need. In that setting, a registry, orchestration layer, and drift dashboard are just extra tools. They slow down experimentation and distract from the real job, which is proving whether the model is useful at all.
That objection is correct up to a point. MLOps is overhead when the model is static, the team is tiny, and the business impact is low. But that is not a reason to dismiss MLOps. It is a reason to apply it at the right moment and at the right depth. The article’s own threshold is clear: once a model is in production and matters to the business, the cost of not having reproducibility, rollback, and monitoring exceeds the cost of the tooling. At that point, avoiding MLOps is not lean. It is negligence.
What to do with this
If you are an engineer, stop treating model delivery like a one-off handoff. Build reproducible training, store model lineage, pin environments, and add monitoring before the first incident forces your hand. If you are a PM or founder, ask a simpler question: how much does a bad model cost per week, and how many hours are you wasting to keep it alive? If the answer is material, fund MLOps as product infrastructure, not optional process. Start with the smallest set of controls that makes the model observable and reversible, then mature one stage at a time.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production