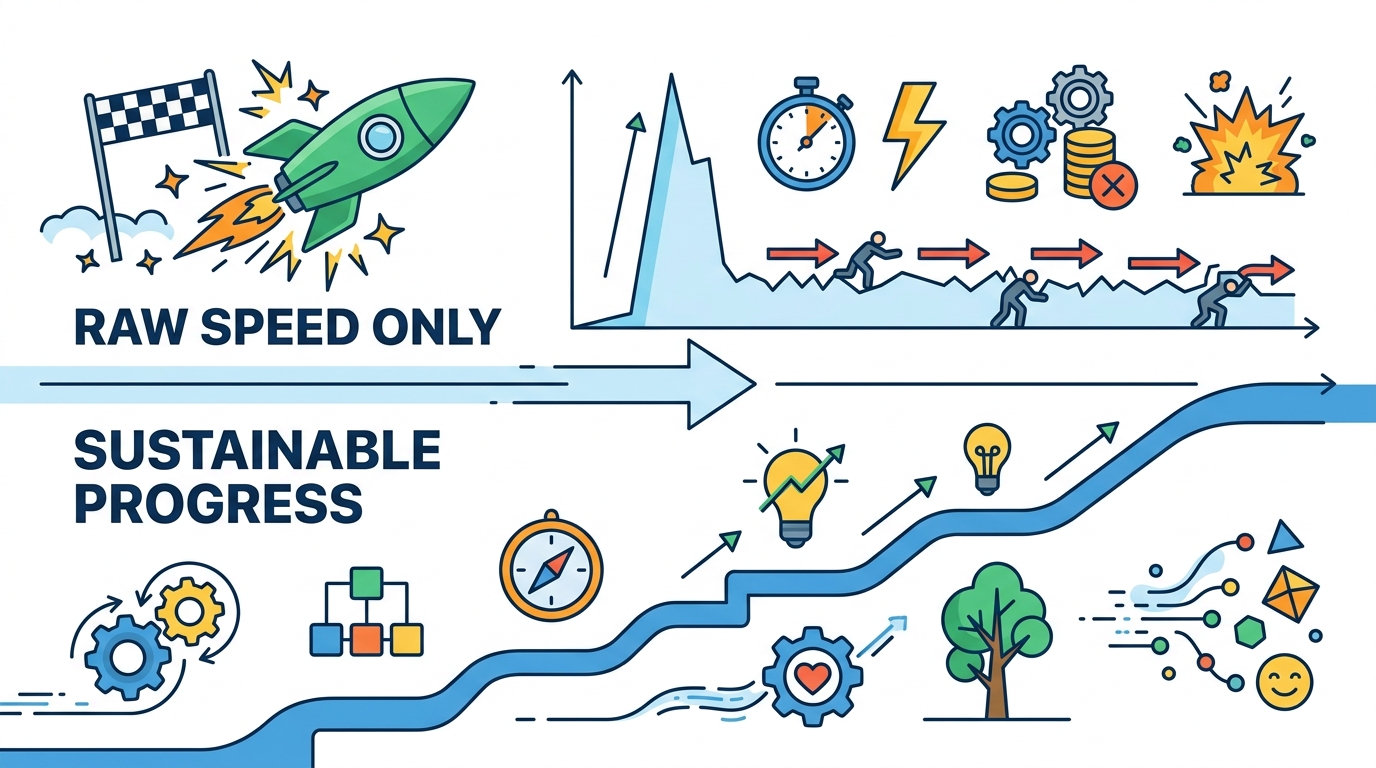
為什麼 Qdrant 的向量搜尋進展比原始速度更重要
Qdrant 的 GPU 建索引、跨可用區叢集與稽核紀錄,真正提升的是企業向量搜尋的可部署性,而不只是跑分。

Qdrant 的 GPU 建索引、跨可用區叢集與稽核紀錄,真正提升的是企業向量搜尋的可部署性,而不只是跑分。
我認為 Qdrant 這波更新的價值,不在於「更快」本身,而在於它把向量搜尋從展示型功能推進成真正可上線的基礎設施。GPU 建索引、三區可用性與稽核紀錄,對應的是企業 AI 最現實的三個問題:能不能跟上資料量、能不能撐住故障、能不能通過治理審查。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
速度不是炫技指標,而是部署成本。Qdrant 宣稱在專用 GPU 上,索引建立速度最高可快 4 倍,這件事直接影響 RAG 管線、批次匯入與索引重建的等待時間。當 embedding 是分批進來、資料又頻繁更新時,慢的不是查詢,而是整個系統從資料進來到可被檢索的時間。

這也是為什麼 GPU 用在建索引比只拿來做推論更有意義。向量資料庫本質上是在建圖,圖結構的生成與重排本來就吃算力。若一個平台能把重建時間從小時壓到更短的窗口,產品團隊就能更快迭代,資料團隊也能更頻繁刷新知識庫。對企業來說,這不是「快一點」,而是「能不能跟業務節奏對齊」。
第二個論點
企業真正買單的不是平均延遲,而是故障時還能不能運作。Qdrant 的三區複寫設計,重點在於讀寫可在剩餘可用區繼續進行,且不需要人工切換。這比一般「高可用」口號更接近真實需求,因為一旦服務中斷,AI 應用常見的不是優雅降級,而是整條檢索鏈路停擺。
稽核紀錄則是另一個更常被低估的門檻。若每一次查詢、寫入、刪除、集合變更與快照操作都能留下結構化 JSON,並記錄使用者、API key、時間戳與允許或拒絕結果,合規與資安團隊就有能力回答「誰在什麼時候做了什麼」。對處理客戶資料、內部知識或代理式工作流的系統來說,沒有這條軌跡,向量搜尋就很難被視為可治理的企業元件。
反方可能怎麼說
最強的反對意見很直接:這些都只是營運層補強,沒有解決 AI 系統的核心問題。索引更快,不代表 embedding 更好;多區複寫,不代表檢索設計正確;稽核紀錄,也不會讓 agent 少犯錯。從這個角度看,Qdrant 只是把一個仍在成熟中的品類,包裝得更像企業產品。
這個批評有道理,因為向量資料庫不會替你修正資料品質,也不會替你定義評估指標。但它忽略了一件事:企業採用不是先證明理論完美,而是先通過安全、穩定與治理門檻。只要一項能力能把審查卡點移除,它就不是裝飾,而是成交條件。
所以我不接受「這些改進只是表面功夫」的說法。Qdrant 並沒有宣稱自己解決模型品質,它做的是更務實的事:降低 ops、資安與法遵團隊說不的機率。對企業 AI 而言,這種改變往往比單純再快 10 毫秒更重要。
你能做什麼
如果你是工程師,別再只拿檢索準確率和延遲做選型,請把批次重建時間、可用區故障行為與稽核匯出能力一起納入測試。如果你是 PM 或創辦人,請把這些能力視為上線門檻而不是加分項。真正能贏下企業 AI 的平台,不是跑分最好看,而是能讓資安團隊放心、讓 SRE 團隊少救火、讓法遵團隊在需要時立刻交代清楚。