SpecKV tunes speculative decoding on the fly
SpecKV adapts speculative decoding’s token budget per step, using draft-model signals to beat fixed gamma across compression settings.
SpecKV adapts speculative decoding’s token budget per step using draft-model signals.
SpecKV: Adaptive Speculative Decoding with Compression-Aware Gamma Selection looks at a very practical problem in LLM inference: the “speculation length” gamma, or how many tokens a draft model proposes before the larger model verifies them. Most systems keep gamma fixed, usually at 4, but this paper argues that the best value changes depending on the task and the target model’s compression level.
That matters because speculative decoding only works well when the draft model proposes tokens the target model is likely to accept. If gamma is too small, you leave speed on the table. If it is too large, you waste work on rejected tokens. SpecKV is a lightweight controller that tries to pick a better gamma at each step instead of locking the system into one default.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Speculative decoding is already a common trick for speeding up LLM inference: a small draft model generates candidate tokens, and a larger target model checks them. The catch is that the number of tokens proposed in one shot is not a free choice. It changes the balance between draft-model work and verification work, and that balance shifts with the model and the workload.

The paper’s core observation is that nearly all existing systems use a fixed gamma, even though the best gamma is not stable. According to the authors, the optimal value varies across task types and also depends on how the target model has been compressed. In other words, the same setting that works well for one deployment can be suboptimal for another.
For engineers, this is the kind of tuning problem that can quietly cap throughput. You may already be using speculative decoding, but if gamma is hard-coded, you are likely optimizing for an average case that may not match your actual traffic or model format.
How SpecKV works in plain English
SpecKV is described as a lightweight adaptive controller. Instead of choosing gamma once and reusing it everywhere, it selects gamma per speculation step using signals that come from the draft model itself.
The paper says the controller uses a small MLP trained on step-level signals including draft entropy and draft confidence. Those signals are used to predict acceptance behavior and, in turn, to maximize the expected number of tokens per speculation step. That is the main optimization target: not just acceptance rate in isolation, but useful output per step.
To build the controller, the authors profiled speculative decoding across 4 task categories, 4 speculation lengths, and 3 compression levels: FP16, INT8, and NF4. That produced 5,112 step-level records with per-step acceptance rates, draft entropy, and draft confidence. The result is a data-driven selector rather than a hand-tuned heuristic.
One important detail is that the method is explicitly compression-aware. The paper does not treat compression as an implementation footnote; it treats it as a factor that changes which gamma is best. That is a useful framing for real systems, where compression can affect acceptance dynamics in ways that static tuning does not capture.
What the paper actually shows
The paper reports that draft model confidence and entropy are strong predictors of acceptance rate, with correlation around 0.56. That is enough to justify using those signals as inputs to a controller, though the paper does not claim they are perfect predictors.
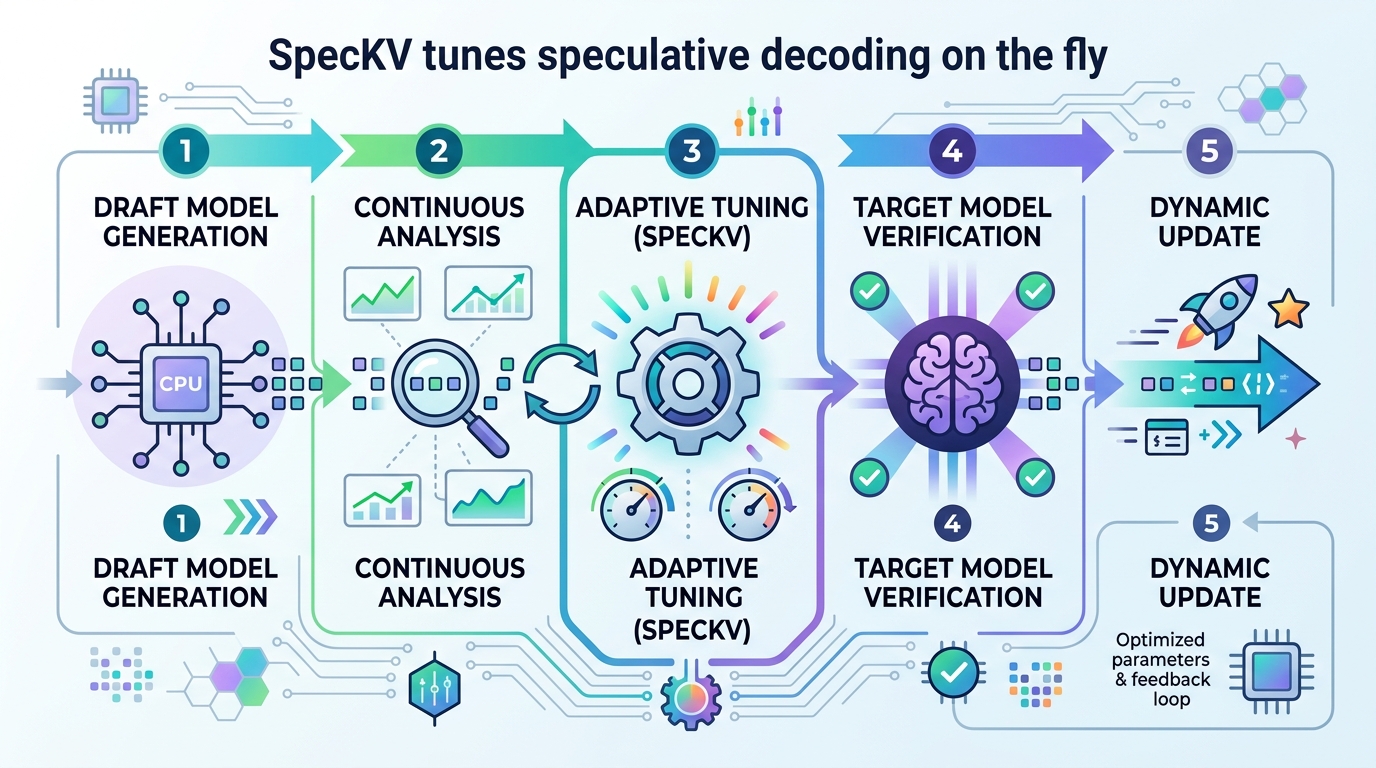
The headline result is a 56.0% improvement over the fixed-gamma=4 baseline. The paper also says the overhead is 0.34 ms per decision, which is less than 0.5% of step time. The improvement is reported as statistically significant, with p < 0.001 using a paired bootstrap test.
There are no benchmark tables or task-specific latency breakdowns in the abstract, so if you are looking for exact per-workload numbers, the abstract does not provide them. What it does provide is enough to show the direction of the effect: adaptive gamma selection can outperform a static default, and the controller appears cheap enough to be practical.
- Profiling data: 5,112 step-level records
- Task coverage: 4 task categories
- Speculation lengths tested: 4
- Compression levels tested: FP16, INT8, NF4
- Reported overhead: 0.34 ms per decision
Why developers should care
If you are shipping an LLM system, gamma is not just a research knob. It affects latency, throughput, and how much work the draft model can amortize across accepted tokens. A fixed value is simple, but simplicity can leave performance on the table when the model, compression scheme, or workload changes.
SpecKV suggests a practical middle ground: keep speculative decoding, but make gamma adaptive using signals the system already has access to. That is appealing because it does not require a new decoding algorithm or a larger draft model. It is a controller layered on top of the existing pipeline.
The open-source release matters too. The authors say they release the profiling data, trained models, and notebooks. For practitioners, that means the paper is not just a conceptual argument; it comes with artifacts that could help teams reproduce the approach or adapt it to their own inference stack.
Limits and open questions
The abstract gives a promising result, but it also leaves some important questions unanswered. We do not get the exact model architecture details for the MLP, the size of the draft and target models, or the per-task breakdown of gains. The abstract also does not tell us how well the controller generalizes beyond the profiled settings.
Another open question is operational complexity. Even with a small 0.34 ms overhead, the real cost will depend on where the controller runs, how often it is invoked, and whether the inference stack can easily expose the needed draft-model signals. Those details matter if you are trying to deploy this inside a production serving system.
Still, the paper makes a clear case that gamma should not be treated as a universal constant. If your deployment uses speculative decoding, and especially if you are mixing compression formats like FP16, INT8, or NF4, this is a reminder to revisit the default settings instead of assuming the common choice is the best one.
In short, SpecKV is about making speculative decoding less static and more responsive to what the model is actually doing at runtime. That is a small change in interface, but potentially a meaningful one for inference efficiency.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10