SpecKV 讓推測解碼自動調 gamma
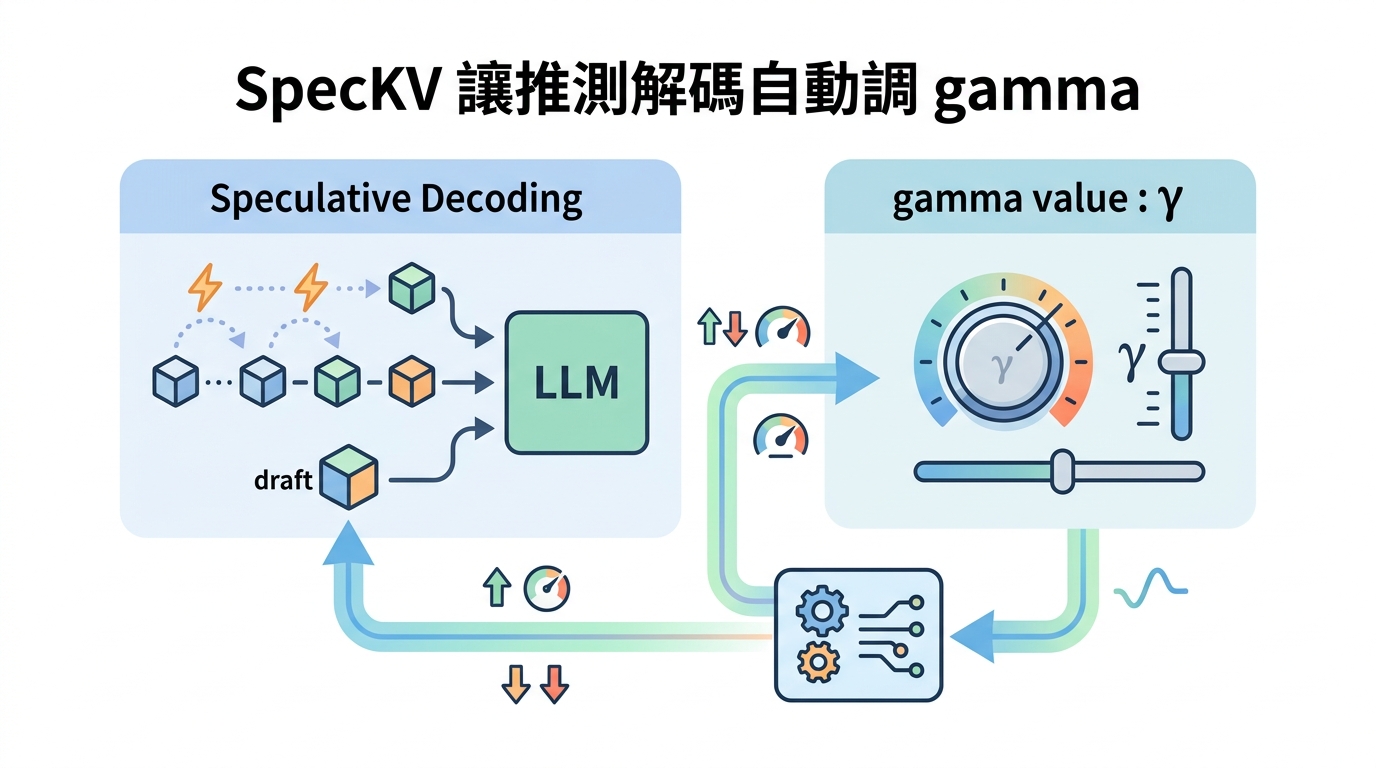
SpecKV 把推測解碼的 token 預算改成逐步自動調整,利用 draft 模型訊號在不同壓縮設定下挑出更合適的 gamma。

SpecKV 用 draft 模型訊號,逐步調整推測解碼的 token 預算。
SpecKV: Adaptive Speculative Decoding with Compression-Aware Gamma Selection 這篇論文在處理一個很實際的 LLM 推論問題:推測解碼裡的 speculation length,也就是 gamma,要一次讓 draft model 提幾個 token,再交給大模型驗證。多數系統會把 gamma 固定住,常見預設是 4,但作者認為這個值不該一體適用,因為它會隨任務類型、目標模型的壓縮程度而變。
這件事會直接影響速度。gamma 太小,draft model 的成果吃不滿,吞吐量可能沒拉上來;gamma 太大,又可能讓一堆 token 被驗證模型打回票,反而浪費計算。SpecKV 想做的,就是不要把 gamma 當成固定常數,而是讓它在每一步都能根據當下狀態自動選得更合理。
這篇論文想解的痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
推測解碼本來就是加速 LLM 推論的常見技巧:小的 draft model 先吐候選 token,大的 target model 再檢查哪些可以保留。問題在於,這個「一次先猜幾個 token」的數字,並不是隨便填一個就好。它會改變 draft work 和 verification work 之間的平衡,而這個平衡又會跟模型、任務、壓縮方式一起變動。

作者的核心觀察很直接:現有系統幾乎都在用固定 gamma,但最佳值其實不穩定。論文指出,最適合的 gamma 會因任務類型不同而變,也會因 target model 的壓縮程度不同而變。換句話說,在某個部署場景裡表現好的設定,換到另一個場景不一定還好用。
對開發者來說,這是很典型的「看起來只是調參,實際上會卡吞吐」問題。你可能已經在用 speculative decoding,但如果 gamma 是寫死的,就很可能是在為平均情況做最佳化,而不是為你真實的流量或模型格式做最佳化。
SpecKV 到底怎麼運作
SpecKV 被描述成一個輕量級的 adaptive controller。它不是一開始就把 gamma 設好後一路沿用,而是會在每個 speculation step 根據 draft model 自己提供的訊號來選 gamma。
論文寫到,這個 controller 會使用一個小型 MLP,訓練時餵入 step-level signals,包括 draft entropy 和 draft confidence。這些訊號被拿來預測 acceptance 行為,進一步去最大化每一步能產出的預期 token 數。也就是說,它不是只看「接受率高不高」,而是看「每一步到底能產出多少有用結果」。
為了建立這個 controller,作者先做了 profiling,涵蓋 4 類任務、4 種 speculation length,以及 3 種壓縮層級:FP16、INT8、NF4。最後累積出 5,112 筆 step-level records,裡面包含每一步的 acceptance rate、draft entropy 和 draft confidence。這讓 gamma 的選擇變成資料驅動,而不是人工拍腦袋的 heuristic。
另一個重點是,這個方法明確把壓縮納入考量。論文沒有把 compression 當成實作細節帶過,而是把它視為會改變最佳 gamma 的因素。這個角度很實務,因為真實系統裡壓縮常常會影響 acceptance dynamics,但靜態調參通常看不到這件事。
論文實際證明了什麼
摘要裡提到,draft model 的 confidence 和 entropy 對 acceptance rate 有明顯預測力,相關係數大約是 0.56。這個數字足以支持把這些訊號拿來當 controller 的輸入,但論文沒有說它們是完美預測器,也沒有把它們包裝成萬能特徵。
最主要的結果是,SpecKV 相對固定 gamma=4 的 baseline 有 56.0% 的提升。論文也說,這個控制器的額外開銷是每次決策 0.34 ms,而且不到 step time 的 0.5%。統計上,這個改善被 paired bootstrap test 證明是顯著的,p < 0.001。
不過,摘要沒有公開完整 benchmark 細節。你如果想看每個 workload 的 latency 分解、不同任務各自提升多少,摘要裡沒有給。它能清楚傳達的,是方向很明確:自適應 gamma 真的能打贏固定預設,而且控制器本身看起來夠輕,具備實作可能性。
- Profiling 資料:5,112 筆 step-level records
- 任務類別:4 類
- 測試的 speculation lengths:4 種
- 壓縮層級:FP16、INT8、NF4
- 控制器額外開銷:0.34 ms / decision
對開發者有什麼影響
如果你在做 LLM 服務,gamma 不是單純的研究參數。它會影響 latency、throughput,也會影響 draft model 的工作能不能被有效攤提到已接受的 token 上。固定值雖然簡單,但當模型、壓縮方式或工作負載改變時,這種簡單也可能代表你把效能上限鎖住了。
SpecKV 提供的是一個實務上的折衷:保留 speculative decoding,但讓 gamma 依照系統當下的訊號動態調整。這個設計吸引人的地方在於,它不需要換一套新的 decoding algorithm,也不需要更大的 draft model。它比較像是加在現有推論管線上的一層控制器。
論文也提到作者釋出 profiling data、trained models 和 notebooks。對實作團隊來說,這代表它不只是概念論文,而是有可重現、可改造的材料。至少從摘要看起來,這件事比較接近工程可落地的調參方法,而不是只停留在理論層。
限制與還沒回答的問題
摘要雖然給出不錯的結果,但也留下幾個關鍵問題。它沒有交代 MLP 的具體架構細節,也沒有說 draft model 和 target model 的大小,更沒有列出各任務的細部收益。對於想直接評估可移植性的讀者來說,這些資訊還不夠完整。
另一個問題是泛化能力。控制器是根據 profiling 資料訓練出來的,但摘要沒有說它能不能穩定套到未見過的設定。若你的部署環境和 5,112 筆記錄所涵蓋的場景不一樣,效果是否還能維持,摘要沒有給答案。
操作層面的成本也還要看實際系統。即使 0.34 ms 的額外開銷看起來不高,真正的成本仍會取決於控制器跑在哪裡、多久呼叫一次、以及 inference stack 能不能順利拿到 draft model 的訊號。這些都是要進 production 才會碰到的細節。
但論文的訊息很清楚:gamma 不該被當成一個放諸四海皆準的常數。只要你的系統有用 speculative decoding,尤其還混了 FP16、INT8、NF4 這類壓縮格式,就值得重新檢查預設值,而不是假設常見設定一定最優。
總結來說,SpecKV 想做的是把推測解碼從「固定參數」拉向「即時反應」。這個改動看起來不大,但對推論效率可能有實際意義。至少從這份摘要來看,它不是在改寫整個解碼流程,而是在現有流程上,把最容易被忽略的那個數字,變成會自己調整的數字。