Why Latent Agents Proves Multi-Agent Debate Should Be Internalized
Latent Agents shows multi-agent debate works best when a single model internalizes it.

Latent Agents shows multi-agent debate works best when a single model internalizes it.
I back Latent Agents because it turns multi-agent debate from an expensive orchestration trick into a model capability that is cheaper, faster, and easier to deploy.
The headline number matters: the method reports up to 93% fewer tokens while keeping reasoning accuracy close to traditional multi-agent systems. That is not a cosmetic improvement. It changes the economics of using debate-style reasoning in production, where every extra round of agent chatter becomes latency, cost, and infrastructure overhead.
Internalization beats orchestration
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Traditional multi-agent debate asks several models to argue with one another in the open. That can improve reasoning, but it also multiplies compute. If three or five agents each need separate prompts, responses, and follow-up turns, the system spends most of its budget on communication rather than thinking. Latent Agents removes that tax by training one model to carry the roles inside its own activations.

The practical advantage is obvious in constrained environments. A model that can simulate debate internally is far easier to run on edge devices, in real-time assistants, and in enterprise workflows with strict latency budgets. You do not need a coordinator layer, message passing, or a brittle chain of agent prompts. You get the reasoning benefit without building a miniature distributed system around every answer.
The token savings are the real breakthrough
A 93% reduction in token usage is not just a benchmark win. It is a deployment win. Token cost is the hidden bill that decides whether a feature ships, whether a startup survives, and whether a team can afford to keep a reasoning system online at scale. If a debate-heavy task can move from thousands of tokens to hundreds, the difference is the gap between a lab demo and a product.
The GSM8K example makes the point concrete. Mathematical reasoning is exactly the kind of workload where multi-agent debate has been attractive, because one agent can propose a solution and another can challenge it. Latent Agents keeps that structure but compresses it into a single model pass. That means lower inference cost, less waiting, and less pressure on serving infrastructure, while preserving the core value of cross-checking answers.
Interpretability is the hidden upside
Latent Agents is more interesting than a cost-cutting trick because it exposes something about how large language models organize reasoning. The activation steering work suggests that agent-like behavior maps to different subspaces inside the model. In plain terms, the model is not just producing one flat answer stream. It appears to separate roles internally, with one region leaning toward deduction and another toward verification.
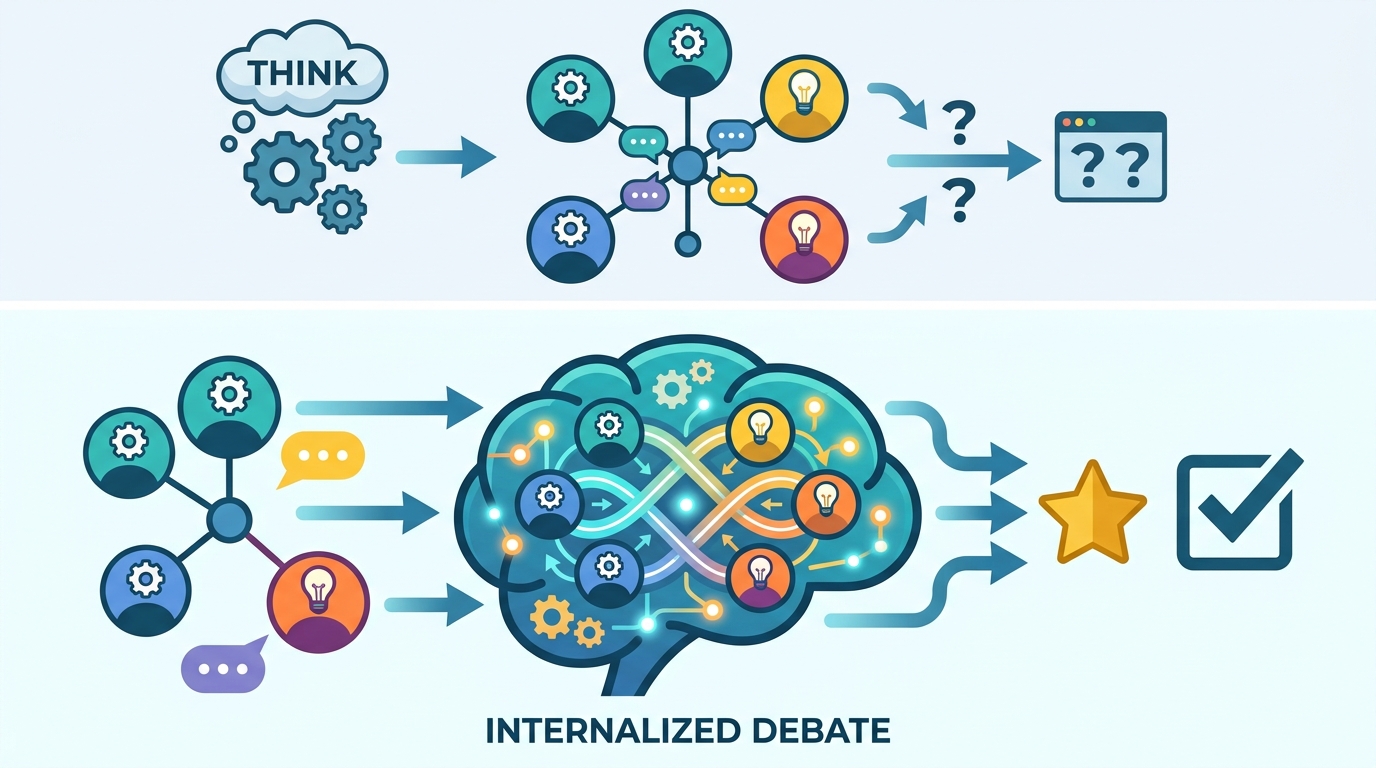
That matters for engineers because it turns debate from an external protocol into an internal mechanism that can be studied, tuned, and audited. If those subspaces hold up under broader testing, researchers gain a new handle on model behavior. They can inspect where a model is doing counterexample checking, where it is following a proposal, and where it is collapsing the distinction. That is a better foundation for reliable reasoning systems than hoping three prompts will keep each other honest.
The counter-argument
The strongest case against Latent Agents is that external agents are more transparent and more flexible. If you want a specialist for math, another for safety, and a third for adversarial critique, separate agents are easy to inspect and replace. They also preserve explicit dialogue traces, which can help with debugging and with tasks that benefit from visible disagreement. On especially complex problems, internalization can blur the fine-grained interactions that a real debate would surface.
That objection is real, and it defines the limit of the approach. But it does not overturn the result. Most production systems do not need theatrical argument; they need dependable reasoning at an affordable cost. When a method preserves accuracy while cutting token usage by 93%, the burden shifts to the external-agent camp to justify the overhead. For the majority of workloads, the extra transparency is not worth the compute bill.
What to do with this
If you are an engineer, stop treating multi-agent debate as the default architecture and start treating it as a training target. Use internalized debate for high-volume reasoning tasks, reserve external agents for cases that truly need visible role separation, and measure success in tokens, latency, and answer quality together. If you are a PM or founder, push for features that bundle reasoning into one model call instead of a swarm of calls, because the cheapest reasoning system is the one users can actually afford to use.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10