Tag
CUDA
CUDA is NVIDIA’s parallel computing platform and programming model, centered on SMs, warps, shared memory, and latency hiding with HBM. It shapes performance in AI training, inference, scientific simulation, and other GPU-heavy workloads.
15 articles

cuDF turns pandas code into GPU runs
I break down cuDF’s GPU DataFrame stack and give you a copy-ready starter for pandas, Polars, and Dask on CUDA.

V100 raw GGUF vs prepacked weight cache
This compares raw GGUF Q4_K kernels and prepacked weight caches for V100 decode inference.

ROCm vs CUDA: GPU Computing Comparison
ROCm and CUDA trade lower cost and openness against broader support and faster performance.

cuda-oxide turns Rust into PTX kernels
I break down cuda-oxide’s Rust-to-CUDA flow and give you a copyable template for writing PTX kernels in Rust.

GPU programming is becoming a core software skill
GPU programming should move from niche graphics work to a standard software skill.

NVIDIA research turns GPU docs into a template
I break down NVIDIA’s research page into a practical template for finding GPU tools, projects, and docs fast.

Why llama.cpp’s release notes matter more than its model bragging
llama.cpp’s latest releases show that backend correctness drives real speed gains.

How to Reduce AI Model Serving Friction
Reduce AI model serving friction by tightening exports, inputs, versions, and deployment checks.
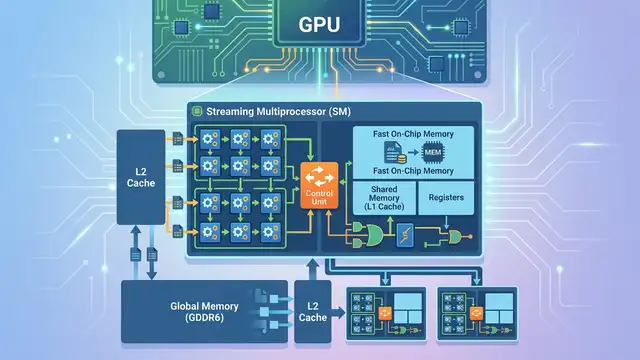
CUDA Architecture Explained: SMs, Cores, Memory
CUDA GPUs split work across SMs, thousands of cores, and layered memory. Here’s why that design beats CPUs on parallel tasks.

Nvidia’s MLPerf Gains Show Software Still Matters
Nvidia posted up to 2.77x MLPerf gains on GB300 NVL72, with software tricks like Dynamo and TensorRT-LLM doing heavy lifting.

NVIDIA Forum Debates a SU(7) CUDA Lattice Engine
A CUDA forum thread on Anchor4 SU(7) mixes lattice theory, shared memory tuning, and warp-level tricks for GPU synchronization.
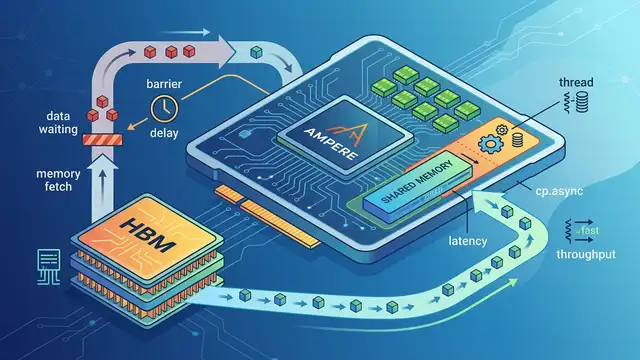
cp.async on Ampere: Hide HBM Latency on A100
Ampere’s cp.async moves data without stalling warps, cutting HBM waits from 450–600 cycles into overlapped compute on A100.

CUDA in 2025: Why GPUs Still Win
CUDA powers NVIDIA GPUs across AI, science, and simulation, with up to 10x weather-model speedups and deep learning gains in the thousands.

CUDA asinf() Gets More Accurate Without Slowing Down
A developer tuned asinf() for CUDA 12.8 and kept the 26-instruction baseline while improving accuracy, a rare win for GPU math.
NVIDIA GTC 2026: Key Highlights and Innovations
Explore the latest AI advancements from NVIDIA's GTC 2026, including new platforms, partnerships, and innovative AI applications.