AdaCodec 用預測碼壓縮影片 token
AdaCodec 用預測式視覺碼只編碼難預測畫面與幀間變化,讓影片 MLLM 在更少 token 下維持表現,還能降低首 token 延遲。
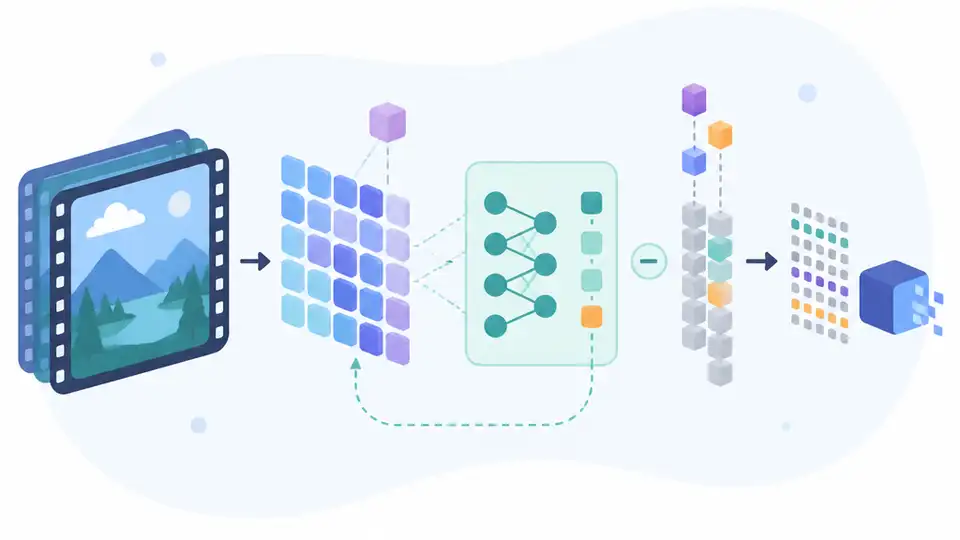
AdaCodec 只編碼難預測的畫面與幀間變化,讓影片 MLLM 用更少 token 還能維持表現。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:32k tokens 對比 224k baseline
- 突破點:預測式視覺碼
影片模型一直有個老問題:重複資訊太多。相鄰幀常常只是背景、物件位置或局部動作在變,但很多系統還是把每一幀都當成新的 RGB 圖像來編碼。結果就是 token 花得快,推理也變重。
AdaCodec: A Predictive Visual Code for Video MLLMs 想處理的就是這種浪費。它不是把每一幀都完整送進模型,而是先判斷這一幀能不能從前文預測出來。能預測的,就只傳幀間變化;難預測的,才送 reference frame。
這篇在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這篇論文鎖定的是影片 MLLM 的輸入效率問題。現在常見做法,是把抽樣出的每一幀都獨立編成視覺 token。這樣做很直觀,但也很粗暴,因為影片本來就有很強的時間冗餘。
對開發者來說,冗餘不是抽象名詞,而是直接反映在成本上。token 預算更高、推理更慢、能塞進上下文的影片也更少。當影片內容越長,這個問題越明顯。
作者的觀點很直接:影片的輸入方式應該跟影片本身的結構一致。也就是說,不要每次都重新描述整張圖,而是優先描述「這一幀相對前文改了什麼」。
AdaCodec 的做法是什麼
AdaCodec 可以理解成一種預測式視覺碼。它的核心不是壓縮單張圖,而是壓縮影片序列中的可預測部分。
具體來說,AdaCodec 會在 conditional predictive cost 高的時候,才使用完整 reference frame。若場景其實很好預測,就改用幀間變化來表示,包含 motion 和 prediction residual,並把這些資訊包成更精簡的 P-tokens。
白話一點,它不是在重建每一幀,而是在問:下一幀到底新增了什麼。這個思路跟傳統「每幀都是獨立圖片」的管線很不一樣,因為它把編碼重心從內容本身,轉到內容之間的差異。
這種設計對系統工程很有吸引力。只要模型能保留足夠的影片資訊,卻少吃很多重複 token,就有機會同時換到更長上下文、更低延遲,或更低推理成本。
論文實際證明了什麼
摘要提到,作者在 11 個 benchmark 上做了評估。它的比較對象是 Qwen3-VL-8B 的 per-frame RGB baseline,而且是在 matched visual-token budget 下比較,也就是盡量把 token 條件拉齊。
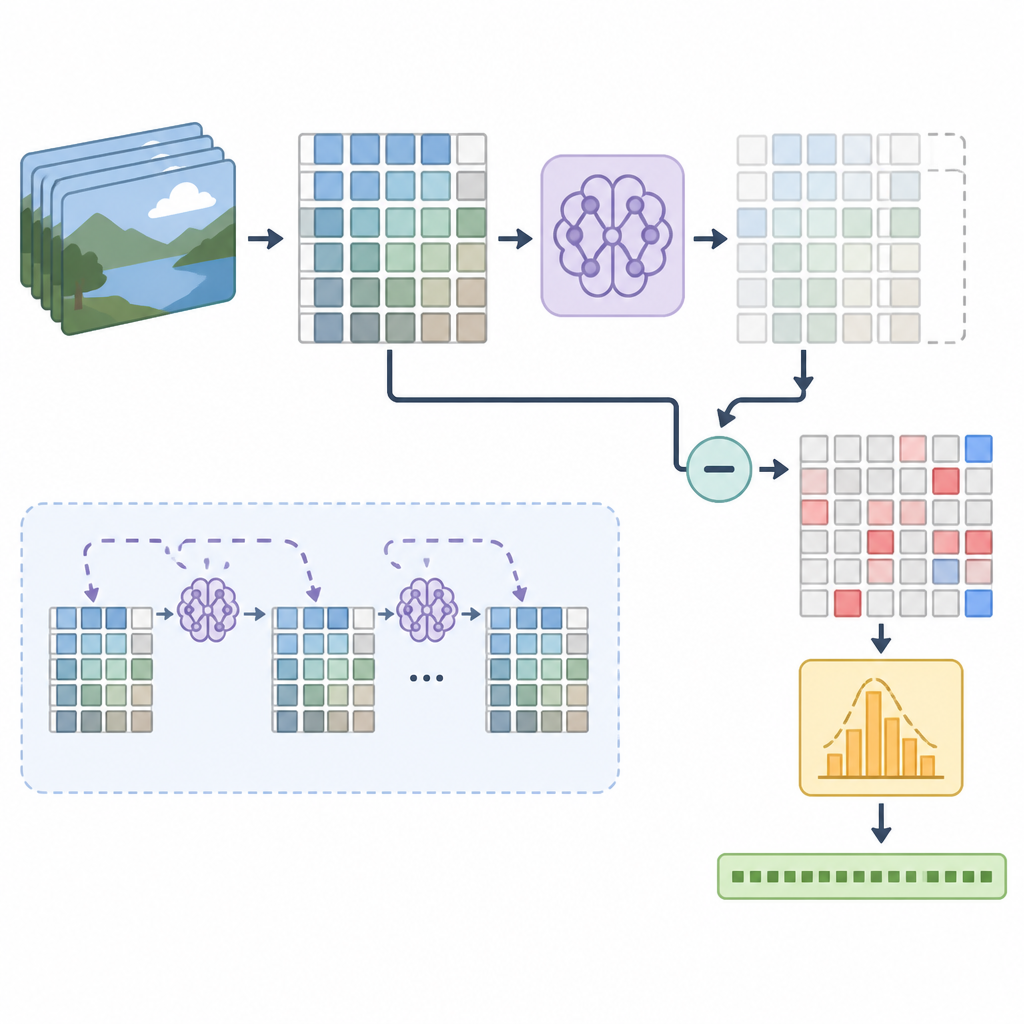
最醒目的數字是 token 效率。摘要寫到,即使只有 one-seventh 的 budget,AdaCodec 用 32k tokens 仍然能在所有 long-video benchmarks 上超過 224k baseline。這代表它不是只靠多吃 token 換分數,而是真的把冗餘壓掉了。
在五個 general-video benchmarks 上,摘要說 AdaCodec 提升了平均分數,同時把 time-to-first-token 從 9.26 秒降到 1.62 秒。這個差距很實際,因為對互動式產品來說,使用者最先感受到的常常不是最終分數,而是模型多久開始回應。
不過,摘要沒有公開完整 benchmark 表格,所以看不到每個任務的細部分數差,也沒有把 11 個 benchmark 的完整清單與設定全部列出來。就摘要能確認的範圍來看,AdaCodec 的訊號很明確:更少 token、更低延遲,而且表現沒有跟著掉下去。
這對開發者代表什麼
如果你在做影片問答、會議摘要、監控分析,或任何要吃影片的 MLLM 產品,token 效率都不是小事。它會直接影響你能處理多長的影片、一次能塞多少上下文,以及每次請求的成本。
AdaCodec 提供的是一種更務實的輸入層設計。它不是一味擴大模型,而是重新定義影片該怎麼進模型。對重複性高的影片資料來說,這種 predictive coding 比 per-frame RGB encoding 更貼近資料本身的樣子。
這也提醒一件事:有時候性能提升不一定只靠更大的模型,還可能來自更聰明的資料介面。AdaCodec 的重點就在這裡。它是在輸入端做優化,但摘要聲稱這個改動已經能同時帶來分數與延遲上的改善。
還有哪些限制要注意
摘要雖然給了方向,但還沒有把細節講滿。它沒有說 predictive cost 具體怎麼算,也沒有交代 P-tokens 的內部形成方式。
另外,摘要也沒有說 AdaCodec 是否需要特殊訓練資料,是否能直接跨模型家族使用,或是在快速切鏡、鏡頭晃動、嚴重遮擋這些情境下會不會變得不穩定。這些都是真正在產品裡會遇到的狀況。
所以現在比較適合的解讀,不是「影片 MLLM 已經被解決」,而是「這篇提出了一條更省 token 的路」。從摘要看,它至少在幾類 benchmark 上證明了這條路可行。
總結
AdaCodec 把影片理解重新包裝成一個預測問題:能預測的內容就少傳,真的變動了再補上。摘要顯示,這個做法能在較低 token 預算下維持甚至提升表現,還能明顯縮短首 token 延遲。
對開發者來說,這個方向的價值很直接。如果後續完整論文與實作細節能站得住腳,預測式視覺碼有機會讓影片 MLLM 變得更便宜、更快,也更容易擴到長影片場景。
- 它把影片冗餘從輸入端先壓掉。
- 它用 reference frame 搭配 P-tokens 表示變化。
- 它在摘要中同時給出效率與延遲改善訊號。