AI Agent 工作流怎麼運作
AI Agent 不是靠一句提示詞就能跑。真正好用的系統靠的是「收集上下文、執行動作、驗證結果、重試」的工作流。

AI Agent 常被講得很神。講白了,它比較像流水線。真正能用的系統,靠的是 4 步:收集上下文、執行動作、驗證結果、再重試。
這個循環比模型大小更重要。你給 200k token,也不代表會做對。讀錯檔案、跳過驗證,一樣會翻車。
說真的,Agent 不是一段 prompt。它是系統。這篇我用 AI Builder Hub 的工作流觀點,拆給你看。你如果用 OpenAI、Anthropic,或 LangChain,重點都一樣:流程有沒有辦法自己抓錯、縮小範圍、把事情做完。
Agent loop 才是核心
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
最實用的說法很簡單。可靠的 Agent 會先拿對資料,再動手,接著驗證,最後根據結果修正。這聽起來很基本,但很多團隊就是卡在這裡。做了一個能聊天、能呼叫工具的介面,就以為自己做出 Agent。
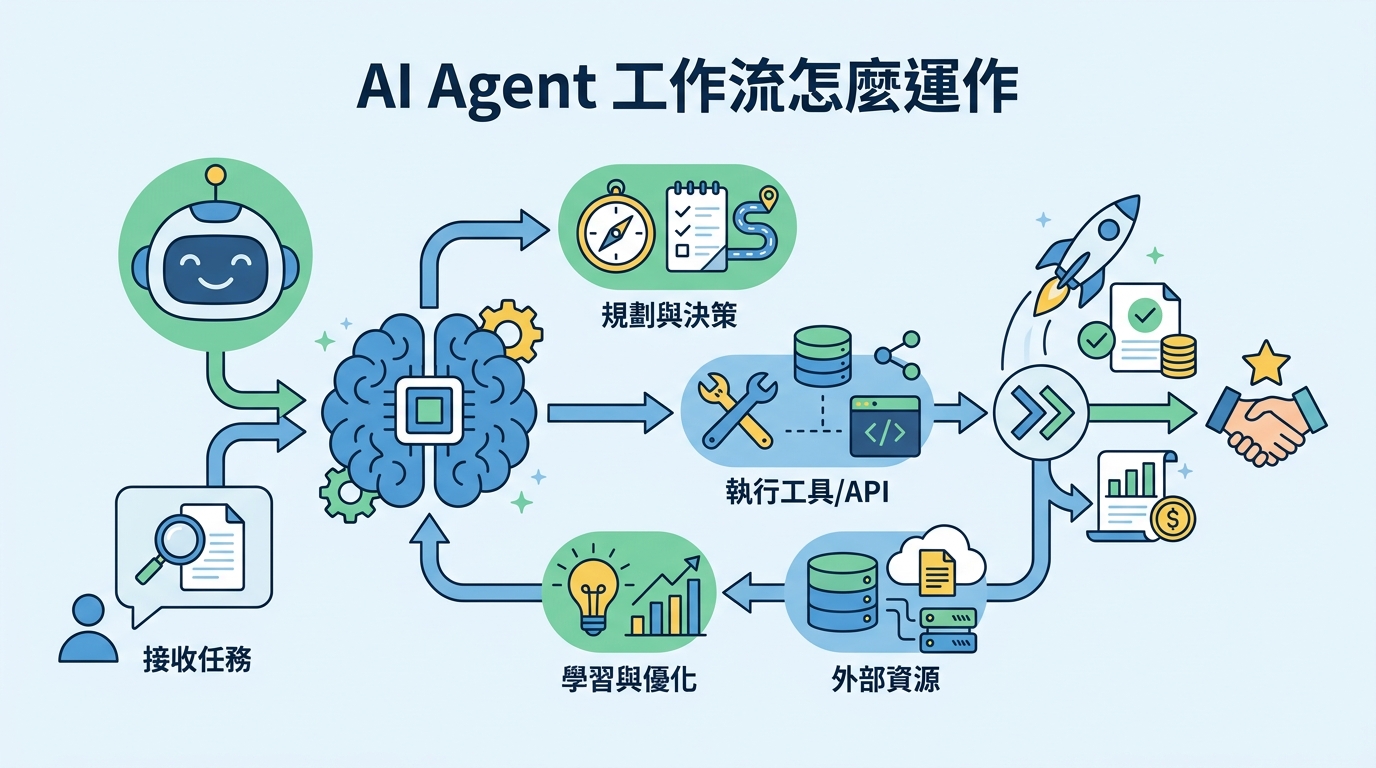
實際工作沒那麼浪漫。寫程式的 Agent,要先看檔案,再改檔案。研究型 Agent,要先讀資料,再下結論。客服型 Agent,要先查政策,再回覆。少了這個循環,模型講話再順,也可能是在亂猜。
我覺得這裡最容易被忽略的,是順序。先找上下文,再做動作。不是反過來。很多失敗案例都不是模型不夠強,而是流程一開始就拿錯資訊。
- 先找上下文:檔案、log、文件、歷史訊息都算。
- 再做動作:要真的用工具,不是只講建議。
- 接著驗證:測試、schema、lint、人工檢查都行。
- 最後重試:失敗後縮小範圍,再跑一次。
這也是為什麼,很多 Agent 反而在「限制自由」後變穩。工具少一點,邊界清楚一點,檢查嚴一點,常常比把所有規則塞進超長 prompt 更有用。
還有一個現實問題。每多跑一輪,就多吃 token 和時間。重點不是不要迭代,而是每一輪都要更精準。這才是工程,不是許願。
上下文工程,比大 prompt 更重要
很多人愛吹 context window。可是一個大視窗,不代表會用得好。Agent 拿到整個 codebase,卻只需要 3 個檔案,這種做法很浪費。注意力被雜訊吃掉,最後還是漏掉真正的 bug。
這也是現在 production 系統的做法。團隊會用搜尋、檢索、檔案掃描,把真正需要的資料撈出來。像 grep、vector search、文件查詢、前一步的歷史紀錄,都是常見做法。目標不是拿最多內容。目標是拿最相關的內容。
這裡可以直接對照 Claude Code 這類工具。它們真正有價值的地方,不是單純能讀很多 token,而是能幫你把問題縮小。你給它 500 個檔案,它不一定更準。你給它 3 個關鍵檔案,通常反而更快。
“The future of AI is not about replacing human intelligence, but about augmenting human capabilities.” — Fei-Fei Li
Fei-Fei Li 這句話放在這裡很貼切。好的 Agent,不是一直猜。它會先問對問題,再用對資料。這比幻想模型自己腦補全部上下文,實際多了。
如果你在做程式碼助手、文件助手、資料分析助手,這個差別超大。上下文抓得準,模型就像有方向感。上下文抓不準,再強的 LLM 也會像在迷路。
驗證,才是 Agent 值不值得信任的地方
很多人做 Agent,最常跳過的就是驗證。模型先生出一段看起來很漂亮的答案,大家就信了。這習慣很危險。講得順,不代表做得對。
驗證可以有很多種。程式碼可以跑測試。API 回應可以對 schema。UI 可以比對截圖。高風險操作,可以走人工審核。重點不是找一種萬能檢查,而是讓系統有回饋,而不是只有信仰。
這裡我很喜歡把 Agent 當成軟體流程看。不是一個回答機器,而是一個會失敗、會檢查、會修正、會再試一次的系統。這種東西才接近可上線。
- 規則檢查:格式、欄位、命名先擋掉。
- Lint:語法和風格錯誤先抓出來。
- 測試:回歸問題最容易在這裡現形。
- 人工審核:高風險決策別全交給模型。
如果你已經在用 Pydantic、Python unittest,或 GitHub Actions,你其實已經有一半的 Agent 骨架了。差的只是把這些檢查,接進 Agent 自己的迴圈裡。
我也想吐槽一下。很多團隊嘴上說要做可靠 Agent,結果驗證只有「看起來像對的」。這種做法在 demo 可以,進 production 就很容易爆。
子 Agent 不是萬靈丹
子 Agent 這件事,常被講得太神。其實它只是分工工具。當任務可以拆成幾個界線清楚的小工作時,子 Agent 才有價值。不是每個任務都需要一堆小代理人。
想像一個 orchestrator Agent。它把工作丟給不同子 Agent。A 去找資料。B 查安全問題。C 看效能。最後 orchestrator 收回結果,再決定下一步。這種方式適合範圍大、子任務窄的工作。
但代價也很明顯。Agent 越多,協調成本越高。token 用量會上升。不同子 Agent 也可能給出互相衝突的答案。所以子 Agent 不是越多越好,而是要剛好切得動。
- 搜尋工作:適合平行蒐集來源。
- 程式碼審查:可分安全、效能、風格三路看。
- 研究整理:先分開讀,再統一寫摘要。
- 方案比較:讓不同子 Agent 各自評估。
這種架構最實際的地方,是它很像真實開發流程。不是一個模型包山包海,而是有人負責協調,有人負責查證,有人負責執行。說白了,就是把大型任務拆開。
如果你用 Claude、GPT-4o,或透過 LangGraph 做流程編排,重點不是「能不能多開幾個 Agent」。重點是哪些工作真的值得獨立出去。
這件事背後的產業脈絡
Agent 熱潮會一直出現,原因很簡單。大家都想把重複工作交給軟體。尤其是客服、資料整理、程式碼維護、內部知識查詢,這些場景都很適合做成流程。
但產業裡真正落地的案例,幾乎都不是靠單一大 prompt。它們靠的是資料管線、權限控管、工具串接、驗證機制。也就是說,Agent 成功的關鍵,常常不是模型本身,而是周邊工程。
這也是為什麼,很多 AI 專案最後會回到傳統軟體工程。你還是得處理 log、錯誤、權限、版本控制、測試環境。模型只是新零件,不是整台機器。
再看成本面也很現實。每一次呼叫 API 都有費用。每一次重試都要算 token。每一次工具調用都可能卡在延遲。Agent 不是越聰明越好,而是越少浪費越好。
所以我會說,真正成熟的 Agent 團隊,會把注意力放在三件事:上下文怎麼取、動作怎麼做、結果怎麼驗。這三件事做好,模型才有機會發揮。
結論:先把一個流程做穩
如果你現在要做 Agent,我的建議很直接。先挑一個任務。把它拆成上下文、動作、驗證、重試四步。不要一開始就想做全能助手。那通常只是把複雜度往後延。
我自己的判斷是,接下來大家會更在意「完成率」而不是「聰明度」。Agent 能不能一次做對,或第二次修對,會比它講話多漂亮更重要。這才是能不能上線的差別。
所以你可以問自己一個很實際的問題:你手上第一個能被做成 loop 的工作是什麼?如果你能替它加上一個明確檢查點,你就已經比很多只會聊天的 Agent 走得更遠了。