Claude Code壓縮機制怎麼省上下文
Claude Code 用多層壓縮處理長對話上下文,避免 200K 到 1M token 被文件、Shell 輸出和編輯記錄吃光。

說真的,Claude Code 的重點不只是會寫程式。它更像一個會整理記憶的代理。當上下文一路堆到 200K 到 1M token,真正麻煩的不是放不下,而是放太亂。
你可能會想問,壓縮上下文有這麼重要嗎?有。一次讀檔、幾次 Shell 輸出、幾輪 patch,token 就像水龍頭漏水。漏到後面,模型還記得昨天的錯誤訊息,卻忘了你現在要修哪個 bug。
講白了,這篇不是在吹 Claude Code 多神。是要拆給你看,它怎麼把長對話裡的雜訊壓短,讓模型在真實專案裡還能幹活。
為什麼上下文會先爆掉
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
在 Anthropic 的 Claude Code 文件 裡,工具呼叫、檔案讀取和終端輸出都會進入對話歷史。這代表你每做一步,模型就多背一段記錄。時間一拉長,記憶就開始塞車。
問題在於,AI 編程助手的上下文成長速度,比一般聊天快很多。你讀一個中型 repo,可能就有數十個檔案。再跑幾次測試,貼幾段 stack trace,token 很快就衝上去。這時候,如果沒有整理機制,模型會開始抓錯重點。
更麻煩的是,程式開發不是單輪問答。它是連續決策。你今天改 A 檔,明天又回頭修 B 檔。模型如果只會照單全收,就很容易把舊嘗試、重複日誌、已否定假設一起帶著跑。
- 讀檔會帶來大量原始程式碼
- Shell 輸出會塞進測試日誌與錯誤堆疊
- 編輯歷史會留下多輪 patch 與回滾紀錄
- 任務目標會被中間細節稀釋
Claude Code 的多層壓縮思路
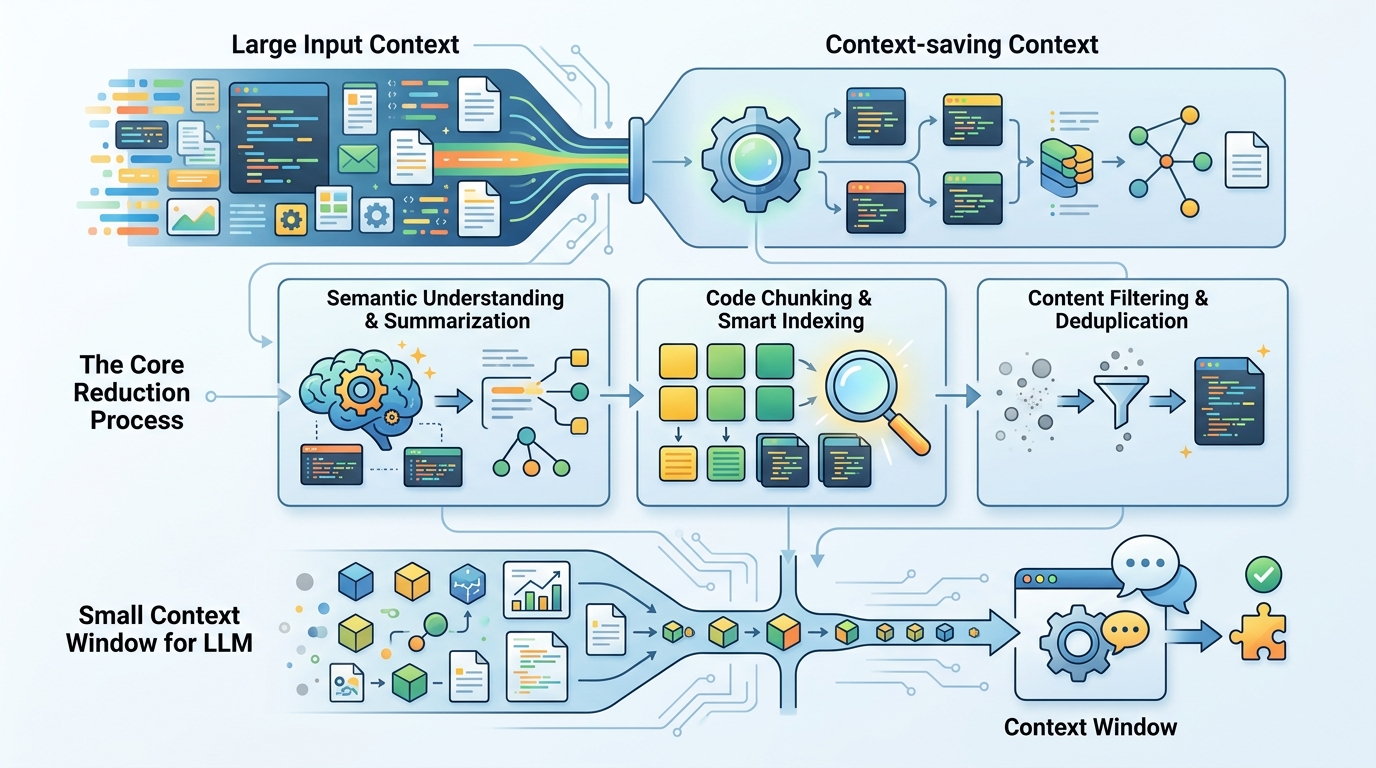
Claude Code 的做法,不是單純叫模型「幫我總結一下」。它比較像分層整理。還有用的內容先保留,已經過時但可能相關的內容會縮短,完全無關的東西就退出活躍上下文。
這種設計很像在幫專案做記帳。現在的任務、最近改動、未解錯誤,這些要放前面。已經驗證過的路徑,就不用一直占位。這樣模型比較不會被一長串歷史訊息拖著走。
我覺得這裡最有意思的地方,是它處理的是「持續工作」而不是「一次問答」。壓縮不是附加功能,而是整個代理流程的一部分。沒有這層整理,長任務很容易越跑越鈍。
- 高優先級:目前目標、最近修改、未解錯誤
- 中優先級:專案結構、關鍵 API、測試結果
- 低優先級:重複日誌、已否定假設、舊嘗試
- 退出活躍區:和當前工作無關的探索紀錄
這和上下文窗口數字到底什麼關係
Anthropic 早就把大上下文做上去了。Claude 3.5 Sonnet 的長上下文能力,也讓很多人開始把焦點放在「能塞多少」這件事上。可是,窗口大,不代表管理就會自動變好。
這裡有個很現實的差別。200K token 不是魔法。前面如果塞滿垃圾,後面再多空間也救不了你。反過來,如果壓縮能把關鍵資訊留住,模型在長任務尾端還是能記得最初目標。
這也是為什麼我覺得,長上下文的競爭,已經不是單看數字。更重要的是,誰能讓上下文保持乾淨。你可以把它想成桌面整理。桌子越大,不代表越好用。重點是東西要找得到。
- OpenAI GPT-4.1 也主打長上下文
- Google Gemini 系列同樣支援大窗口
- Claude 3.5 Sonnet 把長上下文變得更實用
- Claude Code 把壓縮直接塞進開發流程
真實開發場景裡,壓縮比你想得更重要
如果你用過 AI 編程工具,就知道真正吃上下文的,不是聊天本身,而是連續操作。讀一個模組、跑一次測試、修一個邊界條件、再跑一次。這種循環一長,模型記到的東西會爆量。
Claude Code 的壓縮機制,解的就是這種高頻切換。它要保留主線,例如專案正在做什麼、目前卡在哪裡、最近改了什麼。那些已經驗證過、已經失敗過、已經不重要的片段,就要縮掉。
這裡可以直接看一個真實人物的說法。
“We’ve trained our systems to be helpful, harmless, and honest.” — Dario Amodei這句話很適合放在這裡。因為壓縮機制追求的,也是上下文的「誠實」。不要讓模型被噪音騙走。
如果壓縮做得好,使用者會覺得模型很穩。壓縮做不好,使用者只會覺得它突然失憶。這差很多。很多人只盯著窗口大小,卻忽略了資訊篩選本身。
跟其他工具比,差在哪裡
市面上不少 AI 編程工具,都會做某種摘要或記憶整理。但做法差很多。有些是快滿了才砍一刀。有些是把整段對話濃縮成一小段備忘錄。Claude Code 比較像持續整理,而不是等到爆掉再急救。
這種差異在長任務裡很明顯。因為開發流程不是直線。你會在不同檔案間跳來跳去。模型也得跟著重排注意力。只靠一次性摘要,常常會把重要脈絡一起壓扁。
如果拿常見產品來比,差別大概是這樣:有的工具像記事本,有的像檔案櫃。Claude Code 想做的,是讓你在長專案裡還能找到對的那一頁。
開發者該怎麼理解這套設計
如果把 Claude Code 當成一個代理,它的壓縮系統就是記憶管理。工具呼叫負責行動,壓縮負責整理,推理負責判斷。三者一起跑,助手才有機會在長專案裡維持一致性。
這件事對台灣開發者很實際。你不一定天天碰 1M token,但你一定碰過長對話。比如修 bug 修到一半,模型開始忘記前面講過什麼。這時候,問題通常不是模型太笨,而是上下文太亂。
所以我會用很土炮的標準來看:任務跑超過半小時後,模型還能不能講出目前目標、最近改動、未解問題。如果可以,壓縮就有用。如果不行,再大的窗口也只是更大的垃圾桶。
產業脈絡也很清楚。現在大家都在比模型分數,但真正落地時,開發體驗常常輸在上下文管理。誰能把長對話整理好,誰就更接近實用。這點比單看 benchmark 更真實。
接下來要看什麼
我接下來會盯兩件事。第一,Claude Code 會不會把壓縮策略做得更透明。第二,團隊協作場景能不能共享更好的記憶結構。這兩件事都比再多幾個 token 更接地氣。
如果你現在就在用 AI 編程工具,建議你下次跑長任務時,刻意觀察它有沒有記住主線。不是看它會不會講漂亮話。是看它能不能在第 20 輪對話後,還知道你到底要修哪個地方。
說白了,長上下文不是比誰家倉庫比較大。是比誰比較會收納。這才是 Claude Code 壓縮機制真正值得看的地方。