Claude Code压缩机制:长对话如何省上下文
Claude Code用多层压缩处理长对话上下文,避免200K到1M token被文件、Shell输出和编辑记录吃光。
Claude Code 的长会话压缩问题,听起来像个小细节,实际却决定了它能不能在真实项目里干活。一次代码读取、一段 Shell 输出、几轮编辑建议叠在一起,很容易把上下文窗口吃到只剩边角料,尤其是在 200K 甚至 1M token 这种大窗口里,管理方式本身就变成了产品能力。
这篇文章要讲的,不是“Claude Code 很强”这种空话,而是它怎么把长对话里的信息压成更短、更可用的形式。对开发者来说,这件事非常现实:你想要的是模型记得项目目标、当前改动和关键约束,而不是把昨天终端里刷过的 800 行日志一字不差地背下来。
为什么上下文会先爆掉
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
在 Anthropic 的 Claude Code 文档 里,工具调用、文件读取和终端输出都会进入对话历史。只要任务持续时间够长,模型就会不断累积“看过什么、做过什么、下一步要什么”这些记录。
问题在于,代码助手的上下文增长速度比聊天机器人快得多。一个中型仓库里,单次检索几十个文件、跑几次测试、贴几段错误栈,就能把 token 消耗推到很高的位置。到了这个阶段,如果没有压缩机制,模型会开始忘掉早期目标,或者把注意力浪费在无关细节上。
Claude Code 的压缩设计,本质上是在回答一个工程问题:哪些内容必须原样保留,哪些内容可以改写成摘要,哪些内容应该直接丢掉。这个判断如果做得不好,助手就会在长任务里变得迟钝,甚至开始重复劳动。
- 文件读取会带来大段原始代码
- Shell 输出会带来测试日志和报错堆栈
- 编辑历史会带来多轮补丁和回滚记录
- 任务目标会被大量中间细节稀释
Claude Code 的多层压缩思路
Claude Code 的核心做法不是单次“总结一下”这么简单,而是分层处理上下文。短期内有用的内容保留原貌,已经完成但还可能相关的内容被压成更短的记忆,完全过时的信息则从活跃上下文里退出。
这种设计很像给模型做记账:当前任务、关键文件、未解决错误要放在最前面;已经确认无关的探索路径,就不值得继续占着位置。这样做的好处很直接,模型更容易围绕当前目标继续推理,而不是被一长串历史对话拖慢。
从工程角度看,这类压缩通常要处理两个矛盾:一边要尽量保留事实,一边要尽量少占 token。Claude Code 之所以值得讨论,是因为它面对的不是普通问答,而是“读代码、改代码、跑代码、再改代码”的闭环任务,压缩质量直接影响后续决策。
- 高优先级信息:当前任务目标、最近修改、未解决错误
- 中优先级信息:已确认的项目结构、关键 API、测试结果
- 低优先级信息:重复日志、已否定的假设、旧版本尝试
- 退出活跃区的信息:与当前工作无关的探索记录
这和上下文窗口数字到底什么关系
Anthropic 公开提到过 Claude 系列模型支持很大的上下文窗口,而 Claude 3.5 Sonnet 也把长上下文能力推到了更实用的位置。窗口变大之后,问题没有消失,只是从“放不下”变成“放得下但放得乱”。
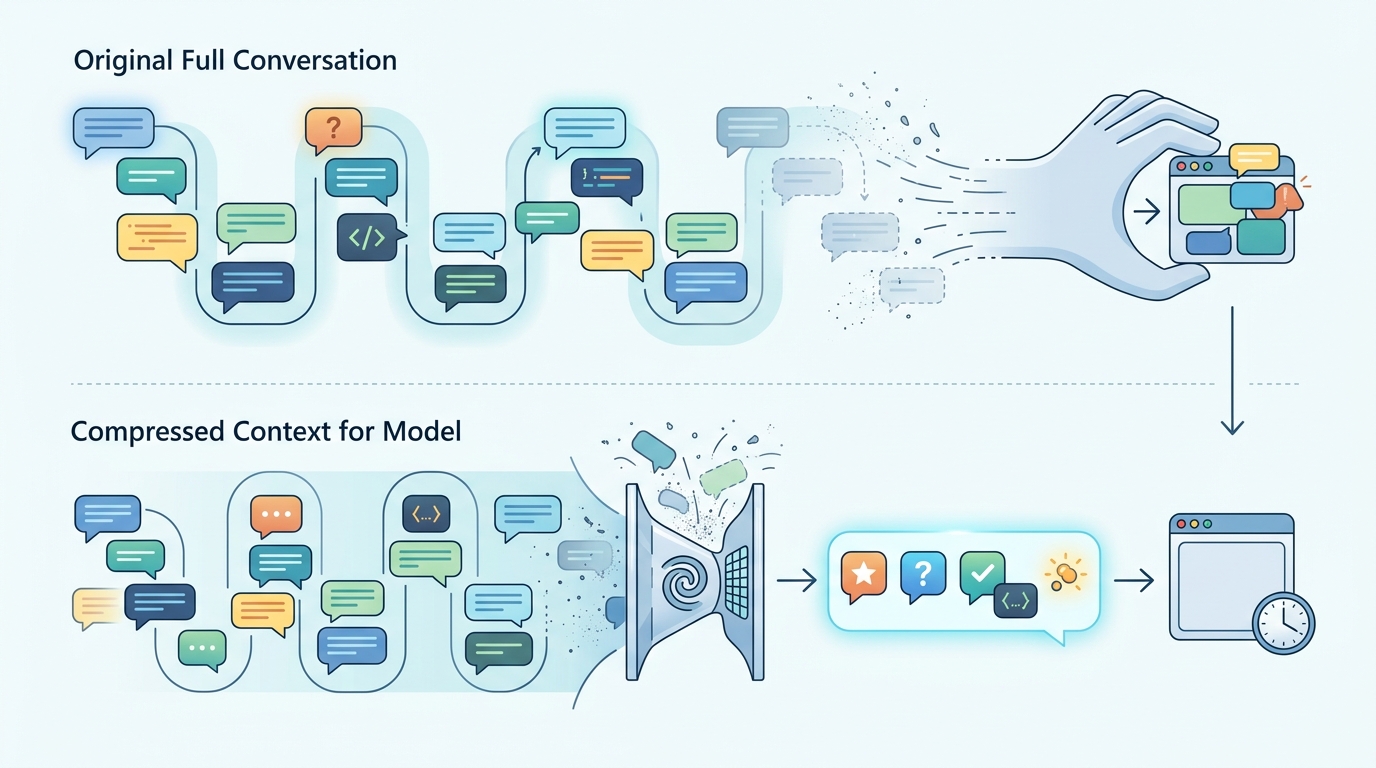
这也是为什么压缩机制比单纯堆 token 更重要。一个 200K token 的会话,如果前 150K 都是无效重复,剩下的 50K 再大也救不了你。反过来,如果压缩能把关键信息留住,模型在长任务末尾依然能记得最初的目标和最近的改动。
对比一些常见做法,Claude Code 的思路更偏向“持续整理”而不是“等快满了再一口气删”。这种差别很重要,因为代码任务往往不是线性的,开发者会在不同文件之间来回切换,模型也要跟着不断重排注意力。
- OpenAI GPT-4.1 也强调长上下文能力,但实现策略并不公开到压缩细节层面
- Google Gemini 系列同样支持大窗口,更考验上下文整理能力
- Claude 3.5 Sonnet 的大上下文让压缩策略更有实际价值
- Claude Code 把压缩嵌进了开发流程,而不是当成离线总结工具
真实开发场景里,压缩比你想得更重要
如果你用过任何 AI 编程工具,就知道真正消耗上下文的不是“问一句答一句”,而是连续执行:读一个模块、跑一次测试、修一个边界条件、再跑一次测试。这个循环一长,模型就会积累大量临时信息,其中很多对下一步没有价值。
Claude Code 的压缩机制,解决的就是这种高频切换场景。它让模型保留“项目正在做什么”这条主线,同时把那些已经验证过、已经失败过、已经不重要的片段压缩掉。对开发体验来说,这比单纯提升模型参数更贴近实际。
“We’ve trained our systems to be helpful, harmless, and honest.” — Dario Amodei, Anthropic
这句话来自 Anthropic 联合创始人兼 CEO Dario Amodei,它很适合放在这里,因为压缩机制本质上也在追求“诚实”的上下文:让模型记住真正重要的东西,而不是被噪音带偏。
从产品体验看,压缩做得好,用户会感觉模型“更稳”;压缩做得差,用户只会觉得它“突然失忆”。这也是为什么很多人讨论长上下文时只盯着窗口大小,却忽略了信息筛选本身。
开发者该怎么理解这套设计
如果把 Claude Code 当成一个会写代码的代理,它的压缩系统其实就是记忆管理。你可以把它理解为:工具调用负责行动,压缩负责记忆整理,模型推理负责决策。三者一起工作,助手才有机会在长项目里保持一致性。
这套思路对未来的 AI 编程工具很有参考价值。接下来真正拉开差距的,可能不是谁先把上下文窗口做大,而是谁能更聪明地决定“哪些内容该留下,哪些内容该缩短,哪些内容可以彻底清掉”。
对开发者来说,最实用的判断标准也很简单:当任务持续半小时以上,模型还能不能准确说出当前目标、最近改动和未解决问题。如果答案是能,那压缩就做对了;如果答案是否,那更大的窗口也只是更大的垃圾桶。
接下来值得观察的,是 Claude Code 会不会把这种压缩策略进一步开放给用户,或者让团队级工作流也能用上更细的记忆管理。对 AI 编程工具来说,这可能比再多几个 token 更能决定实际好不好用。
// Related Articles
- [TOOLS]
Why VidHub 会员互通不是“买一次全设备通用”
- [TOOLS]
Why Bun’s Zig-to-Rust experiment is the right move
- [TOOLS]
Why OpenAI API pricing is a product strategy, not a footnote
- [TOOLS]
Why Claude Code’s prompt design beats IDE copilots
- [TOOLS]
Why Databricks Model Serving is the right default for production infe…
- [TOOLS]
Why IBM’s Bob is the right kind of AI coding assistant