CUDA 架構怎麼跑:SM、核心、記憶體
CUDA GPU 把工作拆給 SM、數千個核心和分層記憶體。這篇用台灣開發者看得懂的方式,拆開它為何特別適合平行運算。
一張現代 GPU,常常塞進上千個 CUDA core。CPU 呢?主流桌機多半只有 8 到 16 顆強力核心。這個差距,直接決定了 CUDA 在平行工作上的表現。
講白了,CPU 像少數幾位大廚。GPU 像超大中央廚房。大家同時做同一個步驟,速度就拉開了。這也是 CUDA 讓人又愛又怕的地方。
你如果做矩陣運算、影像濾鏡、粒子模擬,或大型 AI 推論,GPU 很容易跑得很滿。你如果做很多分支判斷、流程依賴很重的工作,CPU 反而常常更順。重點不是誰比較猛,是工作型態有沒有對上硬體。
CUDA 硬體到底在幹嘛
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
CUDA 是 NVIDIA 的平行運算平台。它讓你把一般程式丟到 GPU 上跑。這套東西的核心,不是單執行緒低延遲,而是吞吐量。
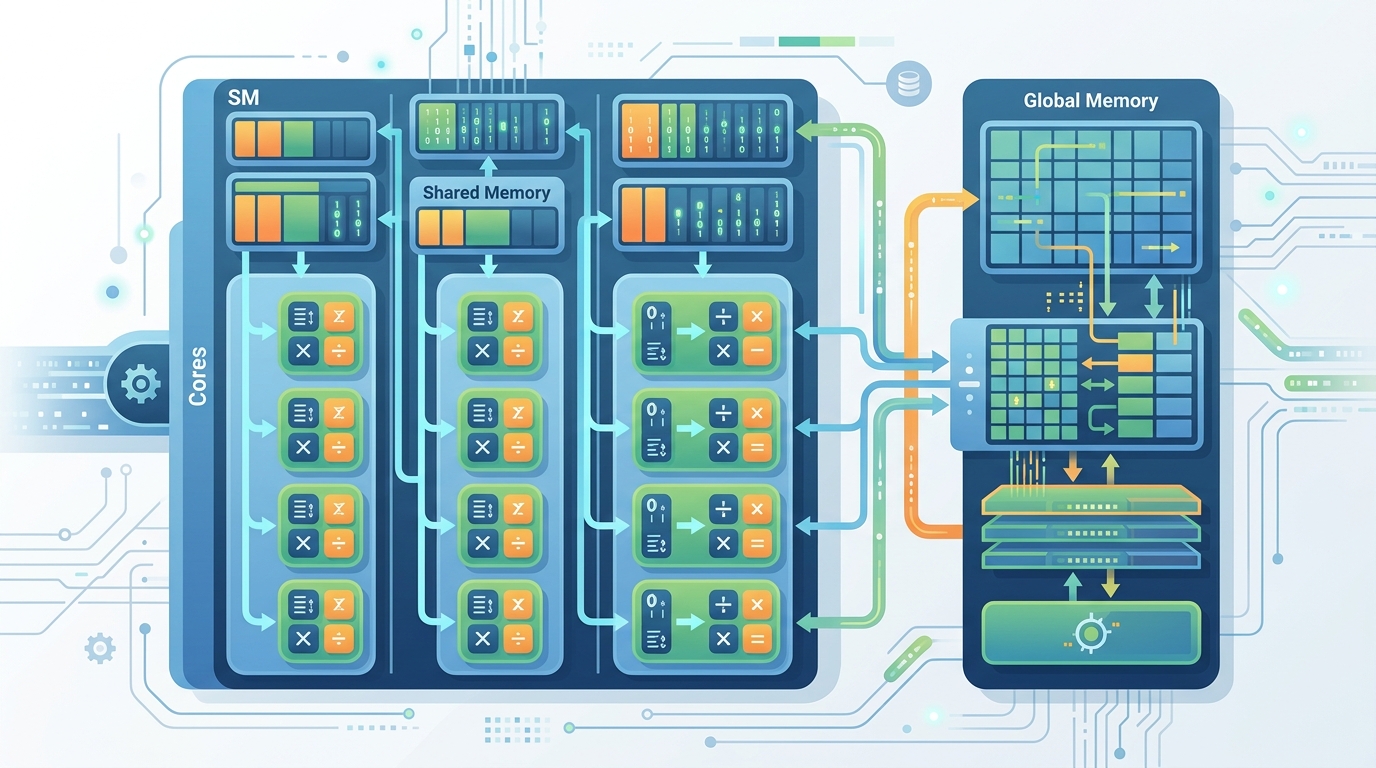
這個差異很重要。CPU 很會處理複雜控制流程。GPU 則很會處理大量重複算術。你可以把它想成兩種完全不同的工廠。前者精細,後者量大。
所以,CUDA 不是拿來亂加速的。它適合的是能切成很多小任務的工作。像是向量加總、影像卷積、深度學習 forward pass,這些都很吃平行度。
反過來說,如果你的程式有很多 if/else,而且每條路都不一樣,GPU 可能會閒著。那時候你會看到一個很尷尬的畫面:硬體很貴,卻沒吃飽。
- CPU 核心少,但單核能力強。
- GPU 核心多,擅長重複算術。
- CUDA 的速度來自平行,不是單執行緒。
- 記憶體存取常比算力更影響結果。
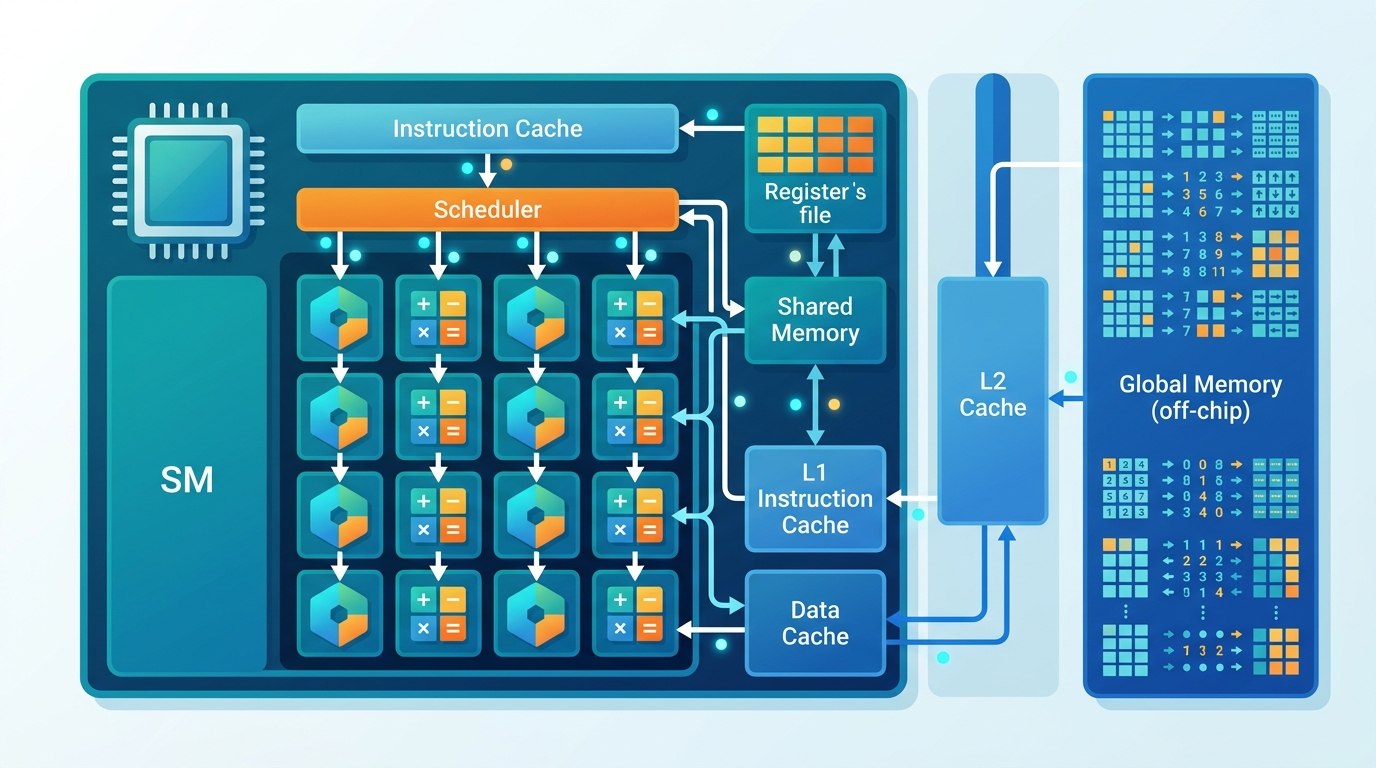
SM 才是真正的排程單位
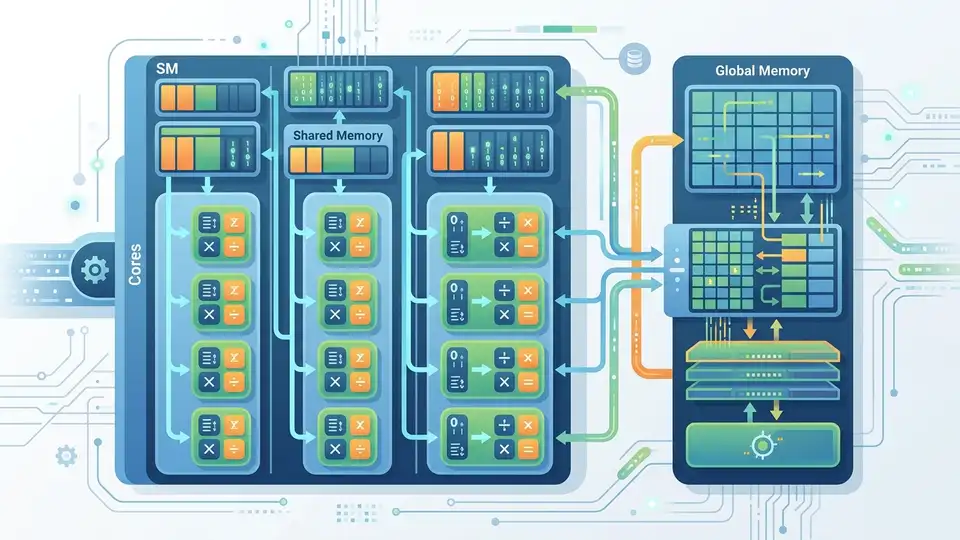
GPU 裡最重要的單位,不是你想像中的「核心數」。而是 Streaming Multiprocessor,也就是 SM。SM 負責排程、分派工作,也包住一組執行資源。
每個 SM 都有自己的排程器和局部資源。這代表 GPU 可以把很多 block 分散到不同 SM 上跑。外面看起來像一顆晶片,裡面其實像一群分工很細的工班。
這裡有個常被新手誤解的點。你不是真的在「直接控制每顆 core」。你是把 thread block 丟給 GPU,然後由 SM 去接手分配。這也是 CUDA 程式設計跟 CPU 程式設計差很多的原因。
“GPUs consist of many simple processing cores organized into streaming multiprocessors (SMs) or compute units, enabling massive parallelism.”
這句話來自電腦架構課程的說明。說得很白。SM 是讓大量平行工作變成可管理的基本單位。
如果你寫 kernel 時只想著「每個 thread 做一點事」,通常還不夠。你還得想 block 怎麼切、SM 會不會塞滿、occupancy 夠不夠高。這些才是 CUDA 的真功夫。
CUDA core 為什麼看起來很多
SM 裡面有很多 CUDA core。它們負責做實際算術。這些 core 不是縮小版 CPU。它們更像大量簡化版算術單元,專門跑重複操作。
所以你才會看到 GPU 核心數很誇張。高階 CPU 可能是 8 或 16 核。資料中心 GPU 卻能有數千個 CUDA core。這不是誰比較高級,而是設計目標不同。
CPU 核心追求的是單一工作快完成。GPU 核心追求的是很多工作一起完成。這也解釋了為什麼有些 AI 推論在 GPU 上快很多。因為它本來就是大量矩陣乘法。
但別把 core 數量當成全部。GPU core 多,不代表任何程式都會快。你如果資料切得很爛,thread 之間又互相卡住,core 再多也只是看起來很熱鬧。
- CPU 核心適合低延遲、複雜控制流程。
- CUDA core 適合高吞吐量、簡單重複運算。
- 分支太多,GPU 效率會掉。
- 資料形狀對了,GPU 才會真的發揮。
記憶體階層,才是 CUDA 的地雷區
很多人以為 CUDA 比的是算力。其實不然。很多時候,真正決定快慢的是記憶體怎麼走。你如果一直去慢的地方拿資料,再多核心都會等到發呆。
NVIDIA 的記憶體階層說明把 GPU 記憶體分成 registers、shared memory、global memory。Registers 最快,但每個 thread 能用很少。Shared memory 很快,而且同一個 SM 內可以共用。Global memory 容量大,但延遲也高。
這就是 CUDA 最麻煩的地方。你不只是在寫演算法。你還在管理資料流。很多 kernel 慢,不是因為算錯,而是因為資料一直在 global memory 來回跑。
所以實戰上有個很土但很有用的規則。暫存值放 registers。附近 threads 會重用的資料放 shared memory。大資料集才放 global memory。這種分層思維,會直接影響你的效能。
- Registers 最快,但容量很小。
- Shared memory 適合同一個 SM 內協作。
- Global memory 最大,但也最慢。
- 少碰 global memory,通常就少踩雷。
你如果做影像處理,常會看到 tile-based 的寫法。原因很簡單。先把一小塊資料搬進 shared memory,再讓很多 thread 重用。這比每個 thread 都去抓 global memory 好太多。
為什麼 GPU 能贏 CPU
CUDA 不是萬能。它只在特定情況下很強。條件通常有三個。第一,工作能切平行。第二,運算步驟很重複。第三,資料存取夠規律。
這也是為什麼 AI 訓練、科學模擬、影片編碼,常常愛用 GPU。這些工作有大量可重複的數學運算。CPU 當然也能做,但它更像是在用精密工具處理少量複雜任務。
你可以把差異看成兩種硬體哲學。CPU 重視每個核心的靈活度。GPU 重視大量核心一起動。前者像少數高手。後者像整隊工人。當工作量夠大時,後者會很有感。
- CPU:8 到 16 顆強核心很常見。
- GPU:數千個 CUDA core 很常見。
- CPU:適合分支多、流程複雜的程式。
- GPU:適合大批量、同質化的資料運算。
如果你想看更完整的程式模型,可以接著看 CUDA 官方文件。你一旦理解 thread、block、grid,很多硬體圖就不會再像天書。
也可以順手看一下競品。AMD ROCm 走的是 AMD 路線。Intel oneAPI 則想把 CPU、GPU、加速器一起管。只是老實說,CUDA 的工具鏈還是最成熟。
背景脈絡:CUDA 為什麼一直重要
CUDA 不是今天才冒出來。NVIDIA 很早就把 GPU 從圖形處理器,推向通用運算平台。這件事後來剛好接上深度學習的浪潮,結果大家現在幾乎都離不開 GPU。
尤其在 LLM 時代,訓練和推論都很吃矩陣運算。模型參數一大,CPU 就很容易卡住。GPU 的大量平行設計,剛好對上這種工作型態。說真的,這就是硬體和演算法剛好對味。
另一個現實是,NVIDIA 在軟體生態做得很深。從 cuDNN 到各種 profiler、compiler、library,整套工具讓開發者比較容易把 GPU 用滿。這也是它在 AI 領域站得很穩的原因。
但這不代表別人沒機會。AMD 和 Intel 都在補工具鏈。雲端服務商也在做自己的加速方案。只是就現階段來看,CUDA 還是很多團隊的第一選擇。
結尾:先看資料流,再看算力
如果你要把 CUDA 用好,我的建議很直接。先看你的資料怎麼流,再看你的算力夠不夠。很多人一開始只看 GPU 有幾個 core,結果寫出來的 kernel 還是慢。
接下來最值得問的問題不是「GPU 有多快」。而是「我的演算法能不能切成很多一樣的工作」。如果答案是可以,那 CUDA 很值得投入。反之,就別硬上,CPU 可能更省事。
我自己的判斷是,接下來幾年,懂 memory hierarchy 的人會更吃香。因為真正拉開差距的,常常不是 FLOPS,而是資料有沒有被你餵對地方。這點很現實,也很殘酷。