長序列4D重建的彈性記憶法
FSM 用彈性 test-time training 穩住長序列 4D 重建的記憶更新,降低遺忘與記憶瓶頸,讓多 chunk 推論更可行。
長序列 3D/4D 重建一直有個老問題:模型越是在推論時自我更新,就越容易忘掉前面看過的內容,或是對眼前這一小段過度擬合。這篇論文提出的 Fast Spatial Memory for Long 4D Sequences,就是要把這個張力處理得更穩一點,讓 test-time training 不只快,還能在長觀測序列裡維持可用性。
對做 spatial AI、機器人、embodied perception,或任何需要從長串視角建立場景表示的人來說,問題從來不只是準不準。更麻煩的是,模型能不能一路適應下去,卻不把記憶吃爆,也不因為更新太自由而把前面學到的東西沖掉。這篇工作的重點,就是把 test-time training 從常見的單一大 chunk,往更適合長序列的多 chunk 適應推進。
這篇論文在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
論文先從 Large Chunk Test-Time Training,也就是 LaCT 出發。LaCT 在長上下文 3D 重建上表現不錯,但它的 inference-time 更新太「全塑性」了,會碰上 catastrophic forgetting 和 overfitting。白話說,就是模型可能很會記住最新看到的片段,卻把前面累積的資訊忘掉,或只學到很局部的捷徑。
因為這種不穩定性,LaCT 通常得用一個很大的 chunk,把整段輸入序列包在一起跑。這樣雖然比較保守,但也卡住了「真正長序列」的目標。你如果想讓模型處理更長的串流,就會撞到 activation memory 的瓶頸。不是算力不夠而已,而是中間狀態根本留不住。
作者把這個問題看成一個落差:test-time training 在理論上可以持續適應,但在實際長序列管線裡,卻很容易變得脆弱。這篇論文想改善的不只是準確率,而是整個適應過程本身的穩定性。
方法怎麼運作
核心方法叫做 Elastic Test-Time Training,概念上借鑑 elastic weight consolidation。它不是讓 fast weights 在推論時完全自由漂移,而是用一個 Fisher-weighted 的 elastic prior,把更新拉回一個維持中的 anchor state 附近。
用白話講,模型還是會在 test time 自我更新,但這些更新不會放飛自我。系統會用一個參考點把它拉住,避免它跑太遠。這個 anchor 也不是永遠固定,而是會隨著過去的 fast weights 做 exponential moving average。這讓模型可以在穩定性和可塑性之間找平衡。
這件事之所以重要,是因為長序列不是單純把同樣的東西重複看很多次。新的視角可能帶來新資訊,但也可能讓模型陷入局部模式,開始過度擬合最近看到的片段。elastic prior 的目的,就是讓更新保持有用,但不要把前面已經學到的資訊洗掉。
在這個更新框架之上,論文再引入 Fast Spatial Memory,簡稱 FSM。FSM 被定位成一個高效率、可擴展的 4D reconstruction 模型。它學的是 spatiotemporal representation,輸入是長觀測序列,輸出則能 render novel view-time combinations。這種能力對動態場景特別重要,因為你處理的不是靜態物體,而是會隨時間變化的空間內容。
作者還提到,FSM 是先在大規模整理過的 3D 與 4D 資料上 pre-train,讓它能抓到複雜空間環境的動態與語意。這表示它不是只靠推論時的更新在撐場,而是先有一個能理解空間與時間結構的基底,再去做更穩定的 test-time adaptation。
論文實際證明了什麼
摘要說作者做了 extensive experiments,整體結論是 FSM 可以在長序列上做快速適應,並且用更小的 chunk 仍然維持高品質的 3D/4D reconstruction。摘要也明確提到,它能減輕 camera-interpolation shortcut,也就是模型比較不會走那條看起來容易、但泛化性比較差的捷徑,去渲染 novel view-time combinations。
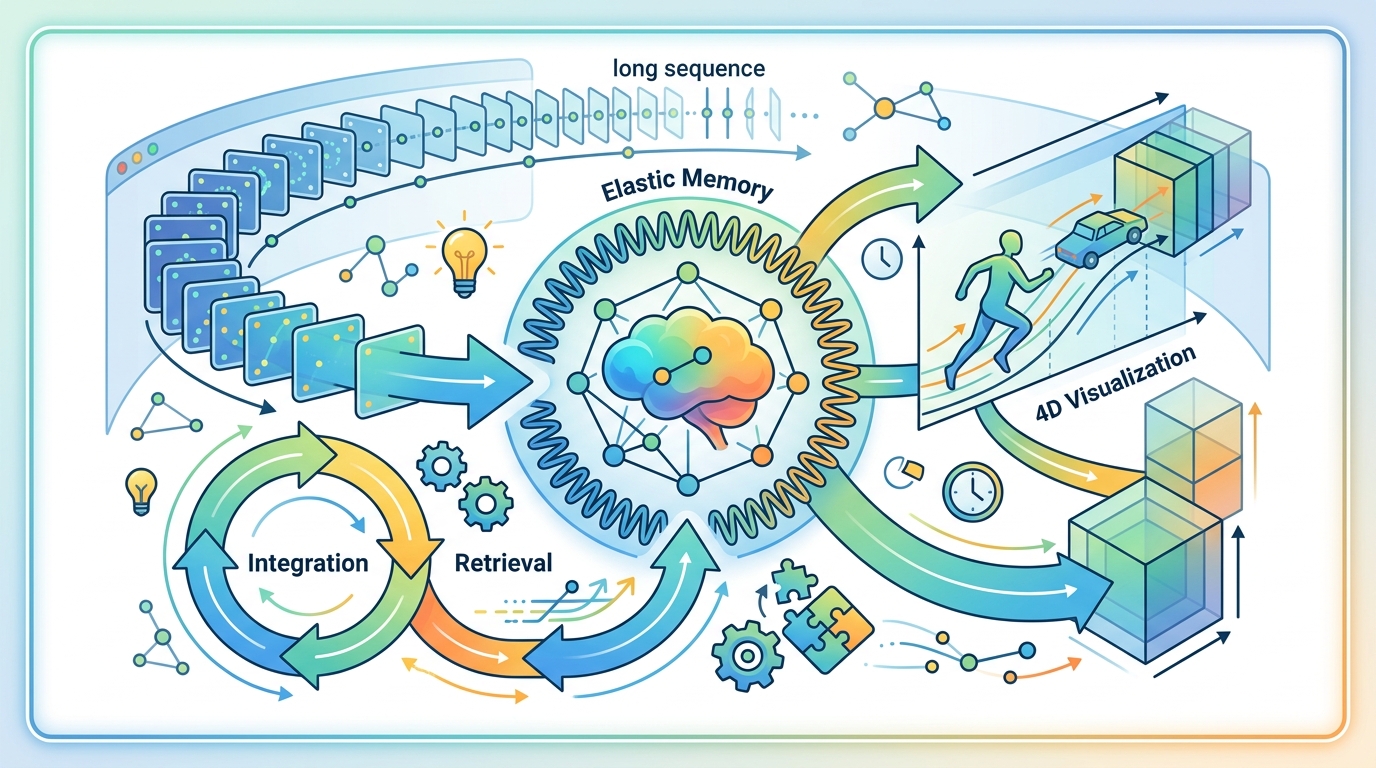
這個訊號很重要。因為在這類任務裡,模型有時候不是學會真正的時空結構,而是學會某種投機的插值方式。論文宣稱 FSM 可以降低這種 shortcut,代表它在表示學習上比較扎實,不只是把相鄰視角湊一湊而已。
不過,這份 raw 資料沒有公開完整 benchmark 細節。摘要裡沒有具體數字、沒有 dataset 名稱、也沒有比較表。所以我們可以說它主張有不錯的實驗結果,但不能替它補上量化表現。若你要評估是否導入,還是得回頭看完整論文的實驗設計、ablation 和 runtime 測試。
- LaCT 在長上下文 3D 重建上表現強,但容易忘記早期資訊。
- Elastic Test-Time Training 用 Fisher-weighted prior 來穩住推論時的更新。
- anchor state 會以 exponential moving average 的方式持續演化。
- FSM 把這套機制用在高效率的 4D reconstruction。
- 摘要主張它能用更小 chunk 做長序列適應,並減少 camera-interpolation shortcut。
對開發者有什麼影響
如果你在做會跟環境長時間互動的系統,這篇最值得看的地方,不是單純的重建任務,而是它處理 training / inference 的方式。很多 spatial model 在短序列或整段上下文一次吃完時表現不錯,但只要你想把序列拉長、壓低記憶體,或做線上適應,原本那套就開始卡住。
這篇論文提供的一個設計觀念是:test-time adaptation 不能只追求更自由,還要加上正則化。換句話說,模型如果會在推論時改自己,就得有機制避免它把先前狀態整個毀掉。elastic anchor 就是一個具體做法。對工程實作來說,這種思路很實用,因為它直接對準「更新太多會壞掉」這個問題。
它也暗示了一種更可落地的 long-context spatial model 路線。不是硬拚一個超大 chunk,把所有東西一次塞進去才叫安全;而是讓模型能跨 chunk 持續適應,同時降低 activation-memory 成本。對記憶體才是瓶頸的系統來說,這比單純再加大模型更有現實意義。
還有哪些限制與未解問題
摘要雖然方向清楚,但也留下不少空白。首先,我們看不到 benchmark 數字、延遲、記憶體節省幅度,也看不到 FSM 跟哪些 baseline 比、差多少。其次,沒有失敗案例,也沒有 chunk size 的敏感度分析,更不知道這方法在不同場景類型上是否同樣穩定。
另一個問題是實作複雜度。Elastic Test-Time Training 需要 Fisher-weighted prior 和持續維護的 anchor state,概念上看起來不算笨重,但實際成本要看 implementation 細節。開發者會想知道它會不會拖慢 throughput、需不需要額外 bookkeeping、以及在雜訊多或觀測稀疏時表現會不會掉得很快。
所以,這篇論文最重要的價值,可能不是某個驚人的單點數字,而是它把「長序列空間模型」的可用性問題講得很清楚:如果你想讓 test-time learning 真正擴到更長的序列,就不能只放大上下文,還得控制更新的可塑性。這篇工作的主張,就是提供一種能兼顧適應、記憶與效率的做法。
總結來說,FSM 比較像是一個系統層面的修補方案,而不是單純追 benchmark 的新招。對做 spatial memory、embodied perception stack,或長時序場景重建管線的工程師來說,這類思路值得持續追蹤。它提醒我們:真正難的地方,常常不是模型會不會學,而是它能不能在學的同時,不把自己以前學過的東西弄丟。