LocateAnything 讓視覺定位更快
LocateAnything 用平行框解碼加速視覺語言定位,還強調能提升高 IoU 的定位品質。
LocateAnything 用平行框解碼加速視覺語言定位,還強調能提升高 IoU 的定位品質。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:超過 1.38 億筆訓練樣本
- 突破點:框與點一次解碼
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding 這篇在處理一個很實際的瓶頸:很多視覺語言模型做 grounding 或 detection 時,會把框座標拆成一串 token,再一個一個解出來。這種做法雖然直覺,卻常常讓推理變慢,也可能讓框的幾何關係變得不夠一致。
這篇論文想傳達的重點很直接:問題不一定只在模型大小或資料量,解碼方式本身也可能是限制速度與品質的關鍵。對需要精準指到圖中物體、區域或點位的應用來說,這個差異很重要。
它在修什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
摘要裡指出,現有方法常把 2D 框當成一串 1D 座標 token 來處理。這會帶來兩個問題。第一,框本來是耦合的幾何物件,但 token 化之後,模型學到的關係可能變得鬆散。第二,推理過程必須嚴格按順序產生每個座標,速度自然被拖慢。
這件事對開發者不是小事。Grounding 不只是分類對不對,還牽涉到輸出夠不夠準,能不能接到後續流程。像裁切、UI 自動化、機器人、標註工具,甚至任何要把「大概在這裡」變成可執行座標的系統,都會碰到這個問題。
所以這篇論文的切入點,不是單純把模型再做大,而是把輸出格式重新設計。它要解的,是「怎麼在不犧牲幾何感的前提下,把視覺定位做快一點」。
方法怎麼運作
LocateAnything 提出的是一個統一的生成式 grounding 與 detection 框架,核心叫做 Parallel Box Decoding,簡稱 PBD。簡單講,它不再把 bounding box 當成一串座標 token 依序吐出,而是把 bounding box 和 point 這類幾何元素當成原子單位,一次解碼。
這個設計同時解決兩件事。第一,因為模型看到的是完整的幾何單位,而不是鬆散 token 串,框內的幾何一致性會比較好。第二,因為不必逐個座標串行生成,推理就能吃到平行化的好處。
摘要把這件事描述成解碼層級的改動,而不是換一個新任務。也就是說,它不是在重新定義 grounding 要做什麼,而是在改變輸出怎麼產生,讓同樣的工作更有效率,也更貼近幾何結構。
這種思路對實作很有啟發性。很多時候,我們會把延遲歸咎於 backbone、參數量或訓練資料,但這篇提醒你:輸出頭怎麼設計,也可能是系統瓶頸。
它實際證明了什麼
摘要宣稱,PBD 同時提升了解碼吞吐量與定位準確度,而且在多個 benchmark 上,速度與高 IoU 定位品質都往前推進。這代表它不是只快一點而已,還試圖維持甚至改善精準度。
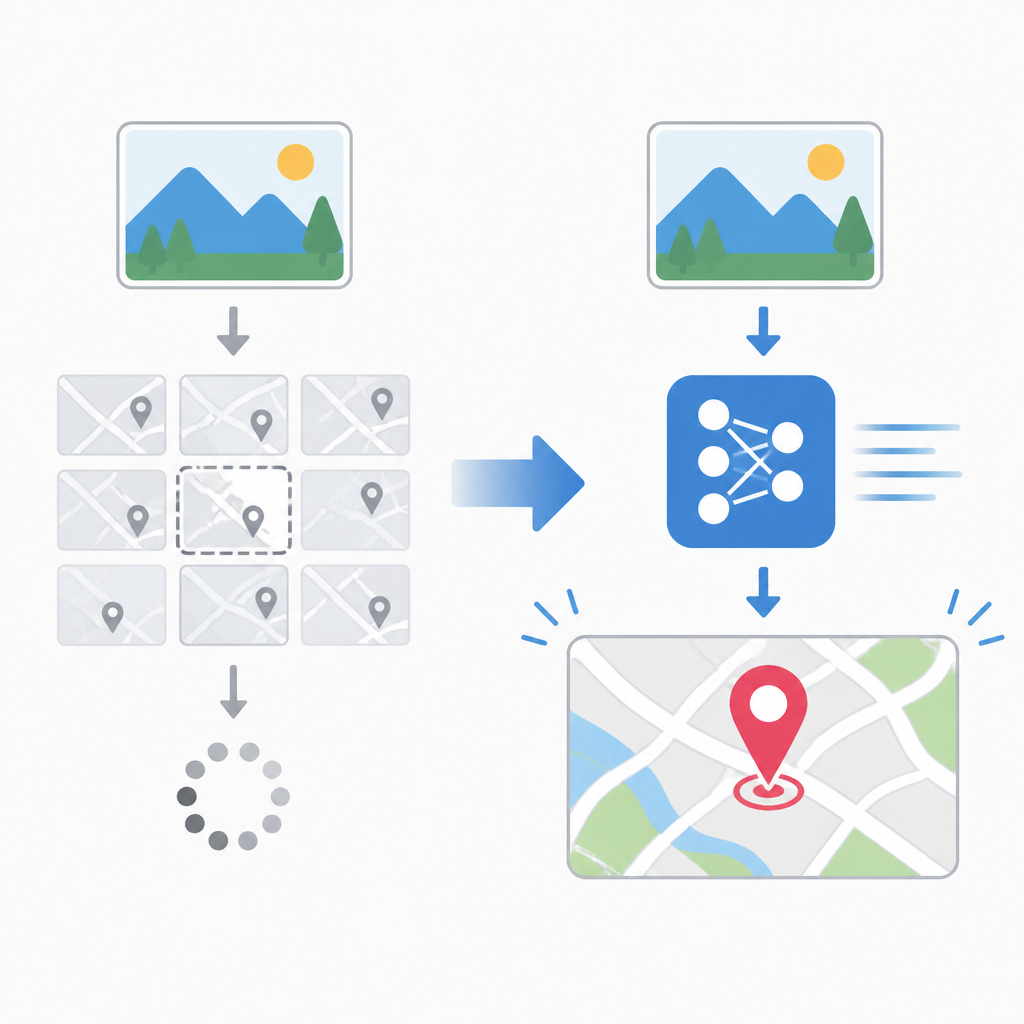
不過,來源有一個明確限制:摘要沒有公開完整 benchmark 細節。沒有看到具體資料集名稱、分數、吞吐量數字或對照表,所以只能確認它聲稱有改善,還不能從摘要判斷提升幅度有多大。
資料端也是這篇的一部分。作者另外建立了可擴展的資料引擎,整理出 LocateAnything-Data,規模超過 1.38 億筆訓練樣本。摘要說這份資料集強化了高精度定位所需的多樣性,表示作者把資料規模與資料多元性,視為跟解碼方式同等重要的支撐。
換句話說,這篇不是在說 PBD 單獨就能解決所有 grounding 問題。它比較像是一組組合拳:一邊改輸出格式,一邊用大規模資料補強訓練。
- 把框與點改成原子單位解碼。
- LocateAnything-Data 超過 1.38 億筆樣本。
- 摘要宣稱吞吐量與高 IoU 定位都提升,但沒給數字。
對開發者有什麼影響
如果你在做視覺語言系統,這篇最值得記住的一點是:輸出格式的重要性,可能不輸給模型架構。用座標 token 一個一個生成,實作上很方便,但也可能變成延遲瓶頸,還會引入不必要的幾何不一致。
PBD 的訊息很像工程上的提醒:有些效能提升,不一定要從更大的模型開始找,而是要回頭看你怎麼把空間資訊編碼成輸出。當輸出本來就是結構化物件時,把它當結構化物件來解,往往比硬拆成 token 更合理。
這對需要頻繁、快速 grounding 的產品特別有感。推理更快,端到端延遲就可能下降;高 IoU 定位更好,後續自動化流程就比較不容易被偏掉。即使摘要沒有給具體數字,方向仍然很清楚:這是在碰一個很實際的部署問題。
但限制也要講白。摘要沒有說 PBD 在小物體、擁擠場景,或座標精度特別敏感的情況下表現如何。它也沒有拆出來說,提升到底有多少來自解碼方法、多少來自 1.38 億筆資料。若你要把這方法搬進自己的 stack,這些細節都會影響判斷。
即便如此,這篇的核心觀點仍然很清楚:視覺語言定位不一定要在速度和精準之間二選一。LocateAnything 想證明的是,解碼策略本身就是可以優化的第一級元件。
總結
LocateAnything 提出一個很務實的替代方案:不要再把框座標當成長串 token 逐步吐出,而是把空間輸出平行解碼,維持幾何一致性,再用大規模資料撐起訓練。摘要聲稱這樣能同時改善速度與定位品質,但沒有公開完整 benchmark 數字。
對工程師來說,這篇的價值在於它把問題講得很具體。當一個 grounding 系統開始卡在延遲,或者定位精度不夠穩,答案未必只是換更大的模型。輸出怎麼設計,可能才是最值得動刀的地方。