為什麼 Walrus 把 AI 記憶放上區塊鏈是對的
Walrus 的方向是對的:AI 記憶應該可驗證、可攜帶,而不是綁死在單一供應商的快取裡。

Walrus 的方向是對的:AI 記憶應該可驗證、可攜帶,而不是綁死在單一供應商的快取裡。
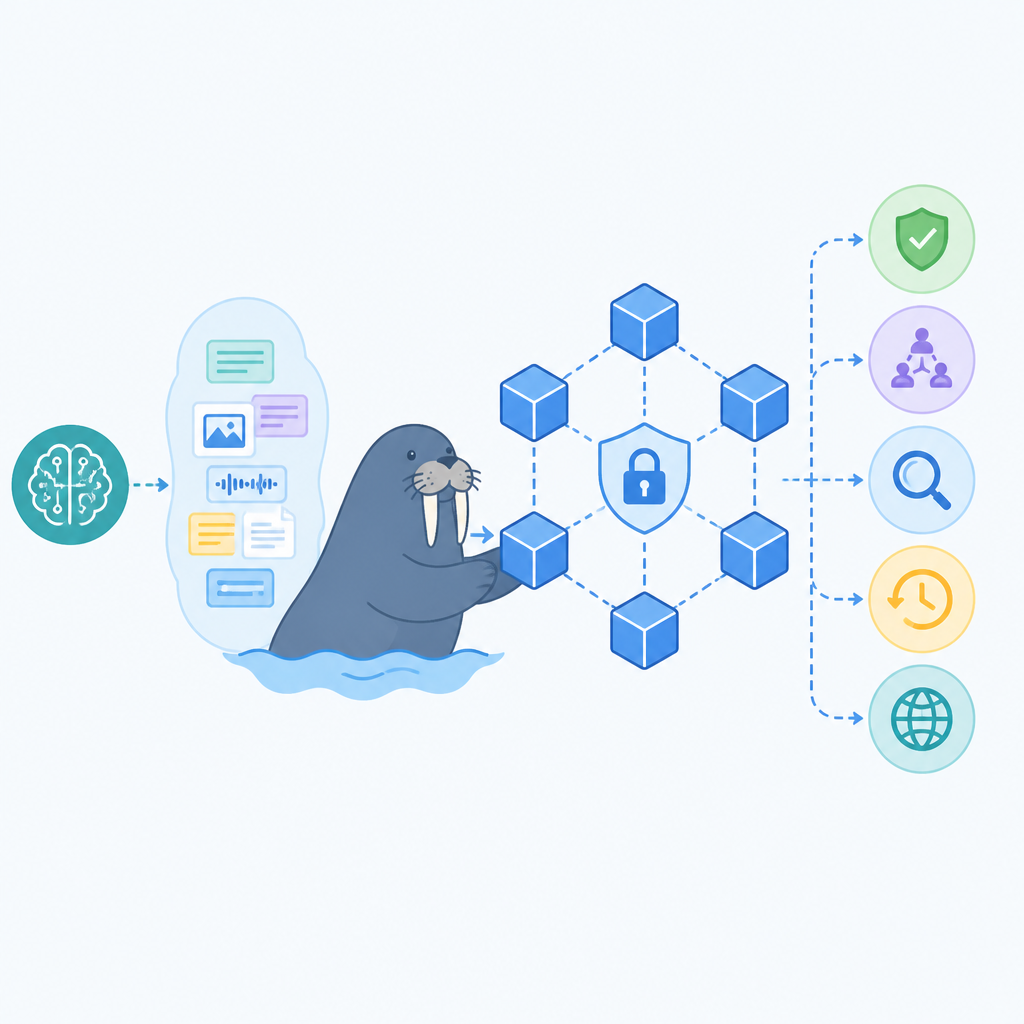
Walrus 的 MemWal SDK 之所以值得認真看待,不是因為它把「區塊鏈」包裝得新潮,而是因為它正面回答了一個現實問題:AI agent 真正有價值的那一刻,是記憶可以跨模型、跨產品、跨供應商延續下去。
現在多數 agent 記憶都很脆弱:不是塞在產品資料庫裡,就是綁在向量資料庫或某個雲端服務上。這對 demo 足夠,對長期運作的系統卻很危險。Walrus 把記憶視為一層可加密、可搜尋、可授權的基礎設施,讓使用者決定誰能讀、誰能寫、誰能分享,而不是把控制權交給當下那個模型供應商。
第一個論點:沒有可攜性,就不算真正的記憶
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
AI 記憶最重要的不是「記住」,而是「搬得走」。一個客服 agent 也許在某家模型服務上學會了客戶偏好,但只要換框架、換模型、換供應商,這些偏好就可能全部失效。Walrus 主張記憶應該能跨模型與平台移動,這不是錦上添花,而是記憶能否成為資產的分水嶺。

企業最熟悉的痛點就是遷移成本。很多團隊先把工作流做在某個 assistant 上,等到要換供應商時才發現,對話紀錄、偏好設定、任務歷史根本無法乾淨搬家。結果不是資料丟失,就是重做一遍。MemWal 把記憶放成資料層,而不是某個 app 的副作用,這才符合 agent 應該跨產品、跨週期存在的現實。
第二個論點:可驗證性是 agent 記憶的信任層
AI 系統最麻煩的地方,不是明顯報錯,而是悄悄記錯、漏記、改記卻沒人知道。當記憶會影響權限、流程、甚至後續自動操作時,使用者需要的不只是「有存到」,還要能確認「存了什麼、何時被改、誰能讀」。Walrus 強調加密與可驗證資料層,正是因為 agent 記憶已經不是一般便利資料,而是決策依據。
這一點在協作型與受監管場景特別重要。中央化資料庫可以很安全,但它終究由單一營運者控制,信任邊界也在同一個管理域裡。Walrus 與 Sui 想做的是把擁有權與存取控制下沉到網路層,讓使用者直接決定記憶的讀寫與分享權限。對醫療、金融、企業內部知識助理這類需要稽核軌跡的場景,這不是理論優勢,而是實務需求。
反方可能怎麼說
最強的反對意見很簡單:大多數團隊根本不需要區塊鏈記憶。用一般資料庫、向量資料庫,再加一層權限控管,就能做出可用的筆記 bot、銷售 copilot 或個人助理原型。這樣做更快、延遲更低、維運更單純,對早期產品來說通常也更合理。
另一個合理質疑是複雜度。開發者不想同時處理加密、語意檢索、存取控制與鏈上或去中心化儲存,除非收益非常明確。如果 MemWal 只是增加一層抽象,卻沒有讓產品更好用、更可遷移、更可稽核,那團隊自然會忽略它。這個批評成立,Walrus 也不該假裝每個 agent 一出生就需要這套架構。
但這個限制不推翻論點,只是劃出適用範圍。MemWal 不是給一次性 demo 的,它是給會活下來的 agent:會跨產品、跨團隊、跨供應商,還會碰到真實使用者資料與權限邊界。當記憶不再是 app data,而是 user data,標準就變了。這時候,能搬、能驗證、能授權,不是高級功能,而是底線。
你能做什麼
如果你是工程師,請把記憶從模型本體拆出來,當成獨立資料層設計,並且一開始就把可攜性、加密與權限列為需求,而不是事後補丁。如果你是 PM,不要只寫「要記住使用者」,而要定義記什麼、誰擁有、怎麼稽核、換供應商時怎麼搬。如果你是創辦人,選能撐過第一次模型遷移的基礎設施,因為 AI 堆疊變動速度一定比產品路線圖快,而搬不走的記憶,遲早會變成第一天就埋下的技術債。