為什麼 Agentic RAG 比 Static RAG 更適合真實工作
Agentic RAG 在複雜、多步驟查詢上明顯優於 static RAG,但代價是更高成本與更嚴格的控制需求。
Agentic RAG 更適合真實工作中的複雜查詢,因為它能拆解問題、反覆檢索並自我檢查。
我站在 Agentic RAG 這邊:只要你的產品面向的是會問「混合型問題」的使用者,static RAG 就不夠用。現實中的查詢很少只是單一事實檢索,更多是跨來源比對、補查、驗證與整合。像「比較兩季營收變化,並找出 10-K 裡提到的風險因素」這種問題,至少包含三件事:找指標、鎖定時間區間、把證據對回原始文件。一次 embedding search 很難把這件事做對,Agentic RAG 才有機會把答案做完整。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
static RAG 的核心假設是「先找相近 chunk,再生成答案」,這對單點查詢有效,對多意圖問題卻常常失手。當使用者同時要求比較、解釋與引用來源時,單次檢索往往回來的是一個折衷結果,不是可執行的檢索計畫。結果就是上下文看似充足,實際上卻混雜、含糊,模型最後只能產出語氣很像真的、內容卻很薄的回答。
Agentic RAG 的優勢在於它把檢索變成流程,而不是前置動作。它可以先拆問題,再決定要查哪個資料庫、要不要改寫 query、要不要補抓缺漏證據。這種做法對分析師、客服、內部知識工作者特別重要,因為他們問的不是「某個字在哪裡」,而是「這些資料合起來代表什麼」。在真實工作裡,這個差異直接決定答案能不能用。
第二個論點
Agentic RAG 更值得採用的第二個原因,是它把「檢查」納入系統設計。static RAG 通常是把檢索結果直接交給生成器,即使檢索到的內容不完整、互相矛盾,流程也不會主動停下來。Agentic RAG 則可以先做 relevance check、gap detection,再決定是否重新檢索。這不是小修小補,而是把幻覺問題往前推到檢索階段處理,而不是等生成完才補救。
多跳檢索與 query reformulation 之所以重要,正是因為使用者不會永遠把問題問得漂亮,文件也不會剛好排成一條直線。像 RQ-RAG、RAG-Fusion 這類方法,本質上都是在提升召回與覆蓋率:先把問題拆開、平行改寫、再合併證據。這些技巧不是學術裝飾,而是對真實資料環境的直接回應。能先修正搜尋,再開始回答的系統,信任度一定高於只猜一次就定案的系統。
反方可能怎麼說
反對者的說法其實很合理:Agentic RAG 更慢、更貴,也更難維運。每多一次 tool call,就多一段延遲;每多一輪檢索,就多一筆 token 成本;每多一個 agent 決策,就多一個失敗點。對 FAQ bot、小型知識庫、單跳查詢來說,static RAG 通常已經夠用,而且部署簡單、行為可預期。
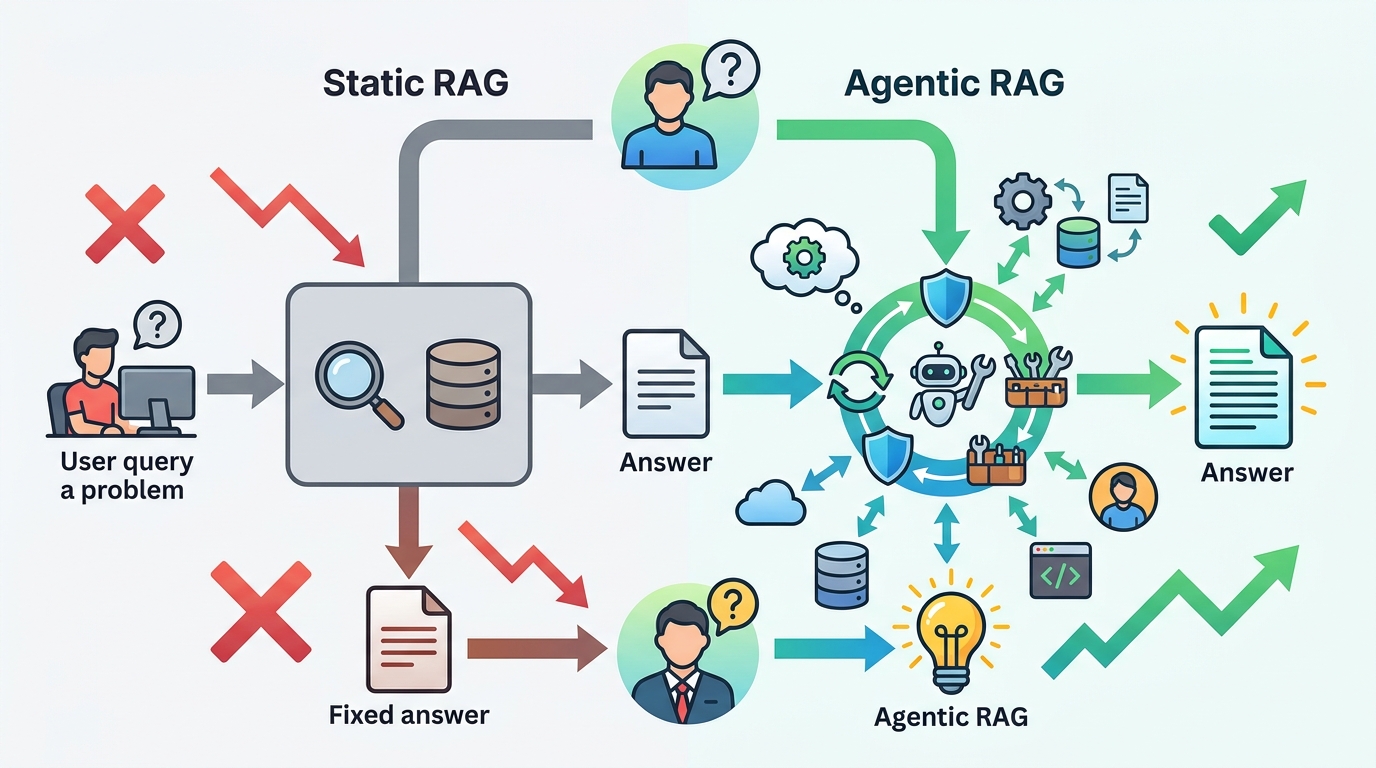
這個批評成立,但它只說明 Agentic RAG 不是萬用解,不代表它不值得用。真正的分界線在於查詢複雜度:如果你的產品只處理單一事實問題,static RAG 的確更划算;如果你的使用者需要跨來源整合、時序比對、證據核對,那麼 static RAG 不是省成本,而是在錯的地方省成本。
換句話說,Agentic RAG 的額外成本不是浪費,而是為了換取可驗證的答案品質。當系統必須面對現實世界裡的模糊問題、缺漏資料與相互衝突的證據時,少一次檢索不一定更快,反而可能更快地產出錯誤答案。這種情境下,便宜但不可靠的架構,最後往往比貴一點但能自我修正的架構更昂貴。
你能做什麼
如果你是工程師或 PM,先不要問「要不要上 agent」,而是先把查詢分層:單跳事實查詢用 static RAG,多來源整合、需要重試、需要驗證的部分再加 agent。把 latency、token 成本、retrieval accuracy 分開量測,不要只看總分數。若你是創辦人,產品策略也很直接:只有當你的使用情境本來就依賴證據、比對與推理時,Agentic RAG 才會變成競爭優勢;否則,別為了聽起來先進而付出不必要的複雜度。