為什麼 Latent Agents 證明多代理辯論應該內化
Latent Agents 證明,多代理辯論最有效的形態不是外掛一群代理,而是讓單一模型把辯論能力內化,才能同時降成本、降延遲、保留推理品質。

Latent Agents 證明,多代理辯論最有效的形態不是外掛一群代理,而是讓單一模型把辯論能力內化。
我支持 Latent Agents,因為它把多代理辯論從昂貴的編排技巧,變成一種更便宜、更快、也更容易部署的模型能力。
最關鍵的數字是,這種方法在維持推理準確率接近傳統多代理系統的同時,最多可減少 93% token。這不是小修小補,而是直接改變了辯論式推理在生產環境中的經濟模型。每多一輪 agent 對話,都意味著更多延遲、成本與基礎設施負擔。
第一個論點:內化比編排更省
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
傳統多代理辯論要讓多個模型公開互相質疑,確實能提升推理品質,但它也會把算力乘上去。三個或五個 agent 各自要 prompt、回覆、追問,系統花最多資源的地方往往不是思考,而是溝通。Latent Agents 把這筆稅拿掉,改成讓單一模型在內部承擔多個角色。

這個差異在受限場景尤其明顯。若要在即時助理、邊緣裝置或企業內部流程中跑推理,延遲預算通常很緊。你不需要一層協調器,也不需要訊息傳遞,更不需要為每次回答搭一個脆弱的迷你分散式系統。把辯論塞進模型內部,才是可持續的做法。
第二個論點:token 節省才是真突破
93% 的 token 降幅不是單純的 benchmark 亮點,而是部署層級的突破。token 成本決定一個功能能不能上線,決定新創公司能不能撐下去,也決定團隊能不能把推理系統長期維持在線上。若原本需要上千 token 的辯論任務,能壓到幾百 token,差別就是實驗室 demo 與可賣產品之間的距離。
以 GSM8K 這類數學推理任務來看,這個結果特別有說服力。數學題正是多代理辯論最常被拿來發揮的場景,因為一個 agent 可以先提出解法,另一個再來挑錯。Latent Agents 保留了這種交叉檢查的精神,但把它壓縮進單一模型流程,讓成本更低、等待更少,也更不吃 serving 基礎設施。
第三個論點:內化後才有可研究性
Latent Agents 不只是省錢技巧,它還揭露了大型語言模型如何組織推理。activation steering 的結果暗示,agent 式行為可以對應到模型內部不同子空間。換句話說,模型不是只吐出一條平面的答案流,而是可能在內部把「提出方案」與「驗證方案」分開處理。
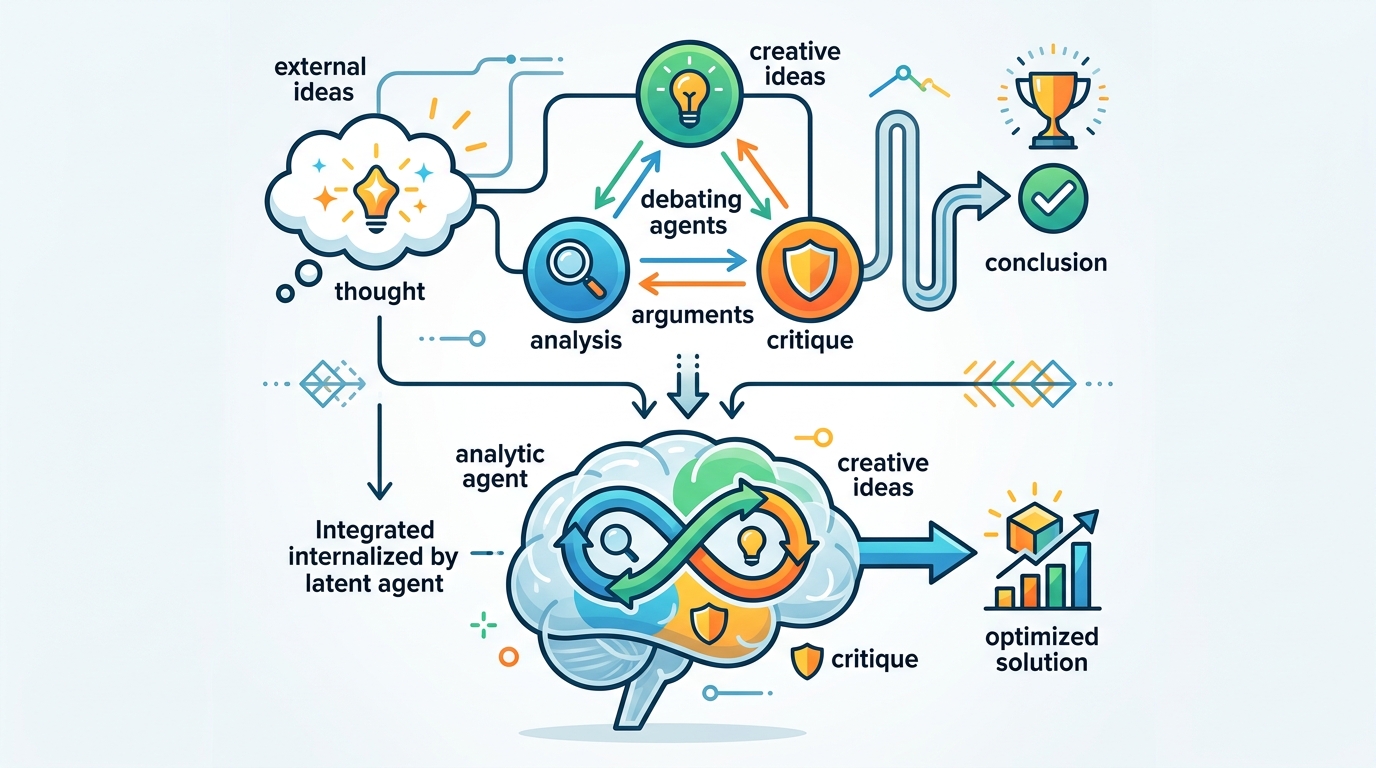
這對工程師很重要,因為它把辯論從外部協議變成內部機制,於是更能被觀察、調整與審計。如果這些子空間在更廣泛測試下仍然成立,研究者就多了一把可用的工具,能看出模型何時在做反例檢查、何時在接受提案、何時把兩者混在一起。比起期待三個 prompt 自動互相制衡,這是更可靠的基礎。
反方可能怎麼說
最強的反對意見是,外部代理更透明,也更靈活。若你想要一個專門做數學、一個專門做安全、一個專門做對抗批判,獨立 agent 很容易替換,也容易檢查。它們還保留明確的對話軌跡,對除錯有幫助,對需要可見分歧的任務也很實用。在特別複雜的問題上,內化可能會抹平原本應該被攤開的細節。
這個質疑是真的,也確實劃出了方法的邊界。但它推不翻結論。大多數生產系統不需要戲劇化的爭辯,它們需要的是可負擔、可預測、可長期運行的推理能力。當某個方法能在維持準確率的同時把 token 用量砍掉 93%,主張外部代理的人就必須證明,那些額外透明度真的值得那筆成本。對多數工作負載來說,答案是否定的。
你能做什麼
如果你是工程師,別再把多代理辯論當預設架構,改把它當成訓練目標。高頻推理任務優先用內化辯論,只有在真的需要可見角色分工時才保留外部代理,並且同時看 token、延遲與答案品質。如果你是 PM 或創辦人,應該推動把推理收斂成一次模型呼叫,而不是一串呼叫,因為最便宜的推理系統,就是使用者真的付得起、也願意一直用的系統。