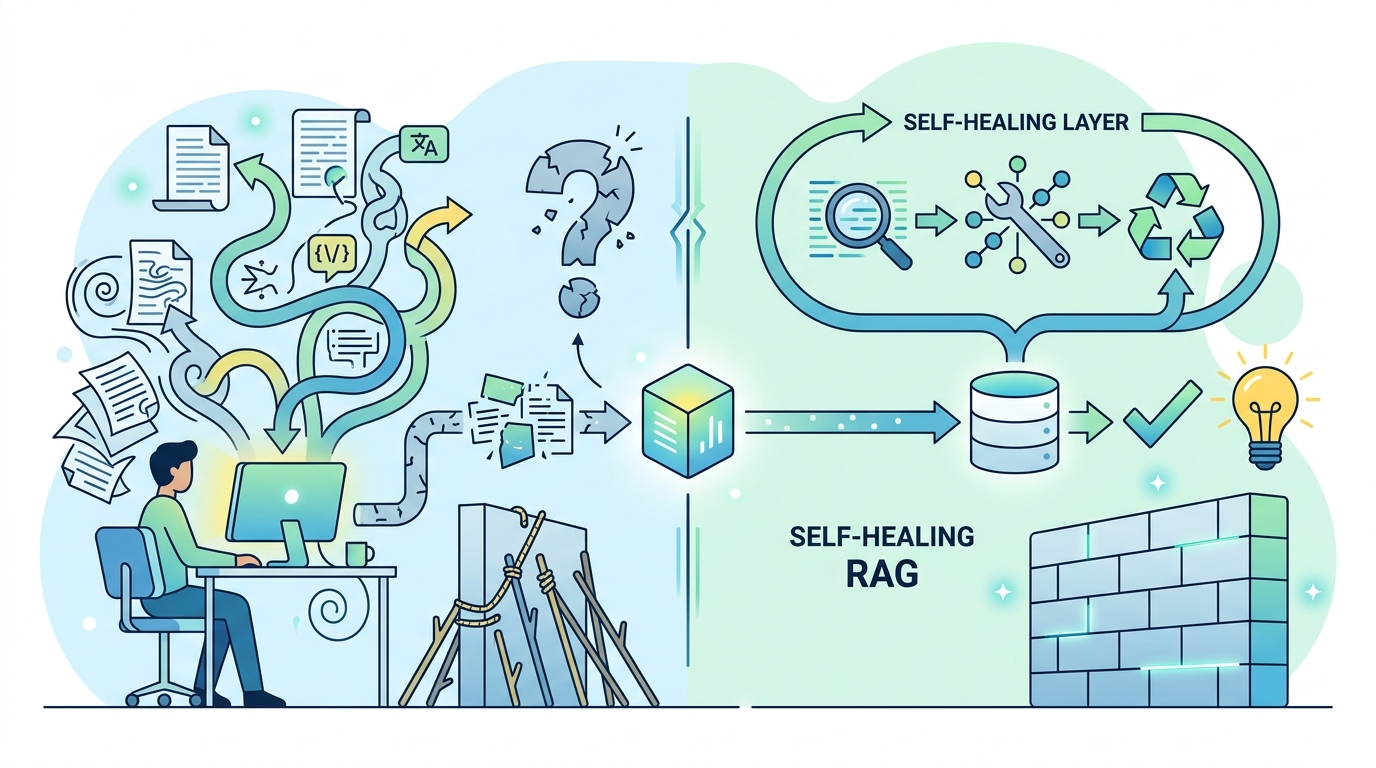
為什麼 RAG 需要自癒層,而不只是更好的提示詞
RAG 應被視為會失敗的系統,真正該補的是即時自癒層,而不是繼續迷信提示詞調校。

RAG 系統需要即時自癒層,因為檢索到正確資料,模型仍然可能產生錯誤答案。
我明確站在「RAG 需要自癒層,不是只靠 prompt」這一邊。原因很簡單:檢索到正確來源,不代表生成出的答案就會遵守來源;真正危險的失敗不是缺少上下文,而是錯用上下文。實作上,這種缺口必須在答案送出前就被偵測、評分與修復,而不是把希望押在提示詞調得更漂亮。作者也用 70 組測試去覆蓋反覆出現的失敗模式,這不是理論想像,而是 production-like 場景裡的實際問題。
第一個論點:檢索正確,不等於答案正確
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
很多團隊仍把 RAG 想成「只要找到對的文件就算成功」。這是錯的。模型可以看見正確 chunk,卻仍然給出不同數字、不同政策結論,甚至相反判斷。這種失敗比單純幻覺更糟,因為系統看起來很有根據,使用者更容易相信錯誤答案。
文章裡最有力的例子就是:retriever 已經找到了正確文件,LLM 卻照樣違背來源內容。這不是換一個 prompt 就會消失的小毛病,而是生成步驟本身的結構性弱點。若你的 production 系統只停在 retrieval 和 generation,你其實是在交付一個沒有最終完整性檢查的答案引擎。
第二個論點:該修的是答案邊界,不是語氣
這套方法最強的地方,在於它把檢查點放在答案輸出的邊界。系統先 retrieve(query),再 generate(query, chunks),接著由 detector.inspect(...)、QualityScore.compute(...)、healer.heal(...) 依序處理,最後才 accept 或 fallback。這個順序很重要,因為使用者看到的只有最終字串,不會看到系統內部曾經「看起來很 grounded」的過程。
它還有很務實的工程價值:檢查被放在一般 FastAPI request 內,不靠外部 API、不靠 embeddings model,也不靠 LLM judge。作者聲稱 spaCy 版本延遲低於 50ms,regex fallback 甚至低於 10ms。這種約束才叫可部署的安全層。若保護機制要多花幾秒,團隊通常會關掉;若只增加毫秒級成本,它才有機會長期開著。
第三個論點:簡單偵測,比空泛信心更適合 production
這套 detector 不追求學術上的花俏,而是直接抓具體失敗型態:數字矛盾、假引用、否定翻轉、答案漂移,以及看似自信但沒有依據的回覆。這是正確方向。production 裡的失敗通常長得很普通,代價卻很貴,所以防線也應該同樣直接。
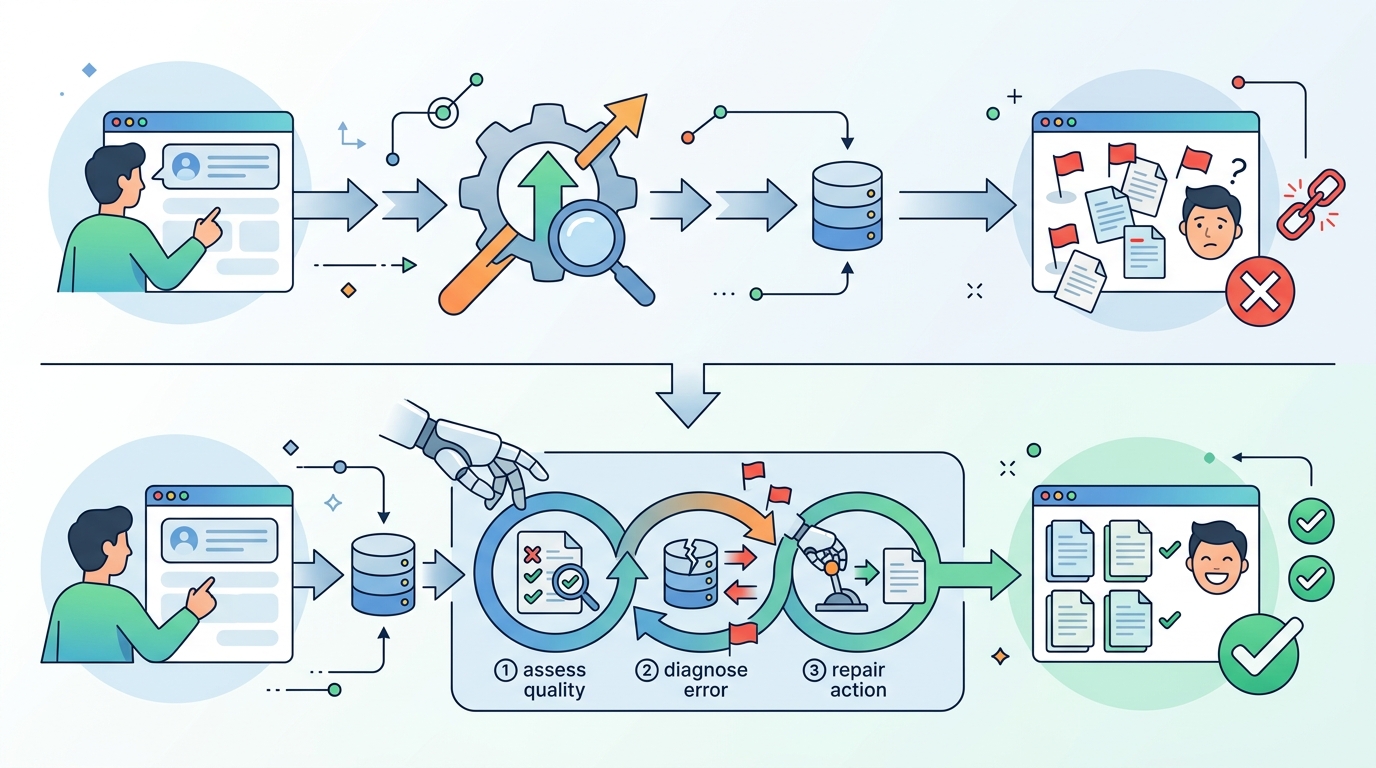
另一個例子是 confidence scorer。它用語言上的過度自信標記,例如 “definitely” 或 “guaranteed”,對比不確定標記如 “might” 或 “I think”。這雖然不是精密的 logprob,但足以抓出模型在裝懂。faithfulness scorer 也一樣務實,它檢查主張關鍵字是否出現在檢索上下文中。這不是哲學問題,而是一個很直接的門檻:答案有沒有可追溯支撐,有就是有,沒有就是沒有。
反方可能怎麼說
最強的反對意見是:自癒層會增加複雜度,而複雜度本身就會帶來新的失敗模式。偵測器若調得太敏感,會誤殺合理改寫;若太寬鬆,又會放過錯誤答案。還有一個合理擔憂是,這種機制會讓團隊滿足於「先補救」,反而不去修底層模型或檢索品質。
這個批評成立,但它不推翻自癒層的必要性,只是提高了實作標準。文章本身已經用明確的 failure assertions、分離 detection 與 repair、以及像 40% keyword overlap 這類門檻去控制風險。正確答案不是盲信 detector,而是把它當成 production infrastructure 來設計、壓測、監控,並在無法保證 grounded 時 fail closed。
你能做什麼
如果你是工程師,在 RAG 回應離開服務前加一個 final-answer gate,檢查矛盾、未支撐實體與過度自信語氣;如果你是 PM,把安全延遲當成搜尋延遲的一部分來規劃,因為快但錯的答案仍然是錯的;如果你是創辦人,別再把 RAG 賣成「檢索就會有信任」,真正的信任來自檢索、驗證、以及模型跑偏時的修復路徑。