13 步建出 Milvus RAG 堆疊
這篇操作指南教你用 Python、Docker、Milvus、LangChain 一步一步做出可查詢、可過濾、可延伸到正式環境的 RAG 堆疊。

這篇教你用 Python、Docker、Milvus 和 LangChain,從零建出可查詢、可過濾、可延伸到正式環境的 RAG 堆疊。
這篇給想把文件問答、知識庫檢索或內部搜尋系統做成可運作原型的開發者看。照著做完,你會拿到一套本機可跑的 Milvus 2.6 環境、一個含向量與中繼資料欄位的集合、可用的混合搜尋流程,以及能接到大語言模型的 RAG 鏈。
每一步都會附上可驗收的產出,讓你在建立、匯入、索引、查詢到串接生成之前先確認狀態,避免做到一半才發現版本不合或集合沒載入。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- Python 3.10、3.11 或 3.12
- Docker Engine 24.x 以上,並啟用 Compose V2
- 至少 8 GB 記憶體,建議 16 GB
- 至少 20 GB 可用磁碟空間
- Milvus 2.6.x 伺服器映像檔,文件可參考 Milvus 官方文件 與 milvus-io/milvus
- pymilvus 2.6.x
- sentence-transformers 穩定版
- LangChain 0.3 以上
- 若要用雲端大模型生成答案,請準備 OpenAI API Key
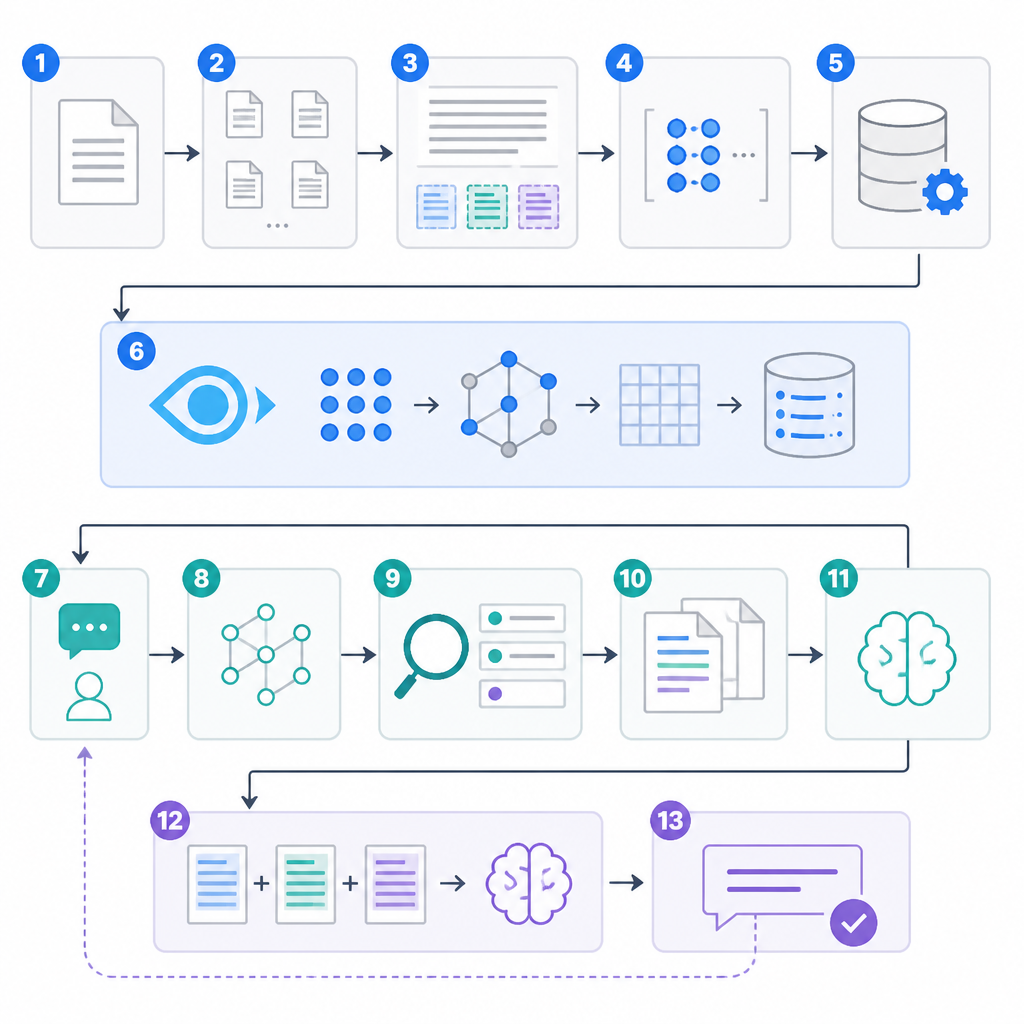
Step 1: 建立 Python 專案
目的:先做出獨立的工作目錄與虛擬環境,讓 Milvus、嵌入模型與編排工具都固定在同一套依賴裡。
先建立資料夾、啟用虛擬環境,再安裝連線、嵌入與 RAG 所需套件,避免後面發生套件版本互相衝突。
mkdir milvus-rag-tutorial
cd milvus-rag-tutorial
python3.11 -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip wheel
pip install pymilvus sentence-transformers langchain langchain-community langchain-openai tiktoken python-dotenv驗收:你應該看到 pymilvus 安裝完成,並且執行 python -c "import pymilvus; print(pymilvus.__version__)" 時回傳 2.6.x 版本字串。
Step 2: 啟動本機 Milvus 服務
目的:先把 Milvus、etcd 與 MinIO 一起拉起來,建立一個接近正式環境的本機測試站台。
建立 Docker Compose 設定檔,指定 Milvus 2.6.x 映像檔版本,接著用 Compose 啟動服務,讓之後的索引與查詢都打到同一個本機端點。
docker compose up -d
docker compose logs -f standalone | head -60驗收:你應該看到類似 Proxy successfully started, listen on: [::]:19530 的訊息,而且容器狀態保持健康。
Step 3: 驗證 Python 連線
目的:確認 Python 用戶端真的能連到 Milvus,並讀到伺服器版本。
建立一個最小連線程式,指向本機的 http://localhost:19530,並使用本機測試預設的 root token 進行連線。
from pymilvus import MilvusClient
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")
print(client.get_server_version())
print(client.list_collections())驗收:你應該看到 Milvus 伺服器版本,以及一個空的集合清單。
Step 4: 定義 RAG 集合結構
目的:建立能存放文件文字、向量與中繼資料的集合,讓後續可以做過濾與檢索。
先規劃 ID、chunk 文字、dense vector 與 source、title、tenant 之類欄位,再把 schema 固定下來,這樣之後從本機搬到正式環境時不必重做資料模型。
from pymilvus import MilvusClient
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")
client.create_collection(
collection_name="rag_docs",
dimension=768,
primary_field_name="id",
vector_field_name="embedding",
id_type="int64",
metric_type="COSINE",
)驗收:你應該能在集合清單中看到 rag_docs。
Step 5: 產生文件向量
目的:把原始文字轉成 Milvus 可以索引與搜尋的 dense vectors。
載入 sentence-transformers 模型,對每個 chunk 做嵌入,並且在匯入與查詢時都維持同一個模型,避免向量空間不一致。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
vectors = model.encode(["Milvus 是向量資料庫。", "RAG 會先檢索,再生成答案。"])驗收:你應該拿到與輸入字串數量相同的向量,而且每個向量維度都要和集合 schema 一致。
Step 6: 切塊並匯入文件庫
目的:把真實文件整理成可檢索的資料列,讓搜尋結果來自你自己的知識內容。
將文件切成有重疊的 chunk,補上來源與標題等中繼資料,產生向量後分批寫入集合,讓後續查詢可以直接命中內容。
rows = [
{"id": 1, "text": "...", "embedding": vectors[0], "source": "docs", "title": "簡介"}
]
client.insert(collection_name="rag_docs", data=rows)驗收:你應該看到 insert 回傳已插入的 ID,且集合筆數有增加。
Step 7: 建立並載入向量索引
目的:替 embedding 欄位建立 ANN 索引,讓搜尋速度足夠快。
先用 AUTOINDEX 走最簡單路徑,或在需要更細控制延遲與記憶體時改用 HNSW、IVF_FLAT 或 DISKANN。
client.create_index(
collection_name="rag_docs",
field_name="embedding",
index_params={"index_type": "AUTOINDEX", "metric_type": "COSINE"},
)
client.load_collection(collection_name="rag_docs")驗收:你應該看到集合已載入,且搜尋不再出現未載入集合的錯誤。
Step 8: 執行第一次語意搜尋
目的:確認檢索層能對自然語言問題回傳相關 chunk。
用同一個嵌入模型把查詢轉成向量,再對集合發出搜尋,接著檢視前幾筆結果與分數是否合理。
query_vec = model.encode(["Milvus 是拿來做什麼的?"])[0]
results = client.search(
collection_name="rag_docs",
data=[query_vec],
limit=5,
output_fields=["text", "title", "source"],
)驗收:你應該看到最相關的 chunk 排在前面,而且分數與你使用的 metric type 相符。
Step 9: 加入中繼資料過濾
目的:先縮小候選集合,再把更精準的內容送進生成階段。
使用 source、tenant、category 這類欄位過濾搜尋結果,能減少雜訊,也能讓多租戶或多文件來源的情境更穩定。
results = client.search(
collection_name="rag_docs",
data=[query_vec],
filter='source == "docs"',
limit=5,
output_fields=["text", "title", "source"],
)驗收:你應該只會拿到符合過濾條件的資料列,這表示中繼資料路徑已經正常工作。
Step 10: 串接 LangChain RAG 鏈
目的:把檢索結果接進提示詞與大模型,完成端到端問答。
把 Milvus 搜尋包成 retriever,將取回的 context 塞進 prompt,再交給你要用的 LLM 生成最終答案。
# 流程示意
# 問題 → Milvus 搜尋 → 取回前幾段 → 提示詞模板 → LLM 回答驗收:你應該能針對自己的文件內容提問,並得到有根據、能對應到檢索內容的答案。
Step 11: 加入 BM25 混合搜尋
目的:提升罕見詞、專有名詞與代碼字串的召回率。
把 dense vector 檢索與 sparse 檢索一起使用,讓語意搜尋與關鍵字搜尋互補,而不是互相取代。
# 先配置 sparse retrieval,再與 dense retrieval 合併
# 最後在生成前做 merge 或 rerank驗收:當你輸入罕見詞或精確名稱時,結果應該比只用 dense search 更準。
Step 12: 基準測試並調整索引
目的:依照延遲、記憶體與召回率目標,選出最適合的索引參數。
HNSW 適合低延遲記憶體搜尋,IVF_FLAT 適合折衷型表現,DISKANN 適合大型磁碟型集合,AUTOINDEX 則適合先快速起步。
驗收:調整後,你應該看到搜尋更快或記憶體更省,而且結果品質沒有明顯下降。
| 指標 | 基準/優化前 | 結果/優化後 |
|---|---|---|
| BM25 搜尋速度 | 以外部搜尋引擎作為基準 | Milvus 2.6 官方資料宣稱可快 400% |
| 向量記憶體占用 | FP32 向量 | 改用 FP16 或 BF16 後約減半 |
| 部署型態 | 僅能使用叢集式架構 | 可選 Lite、Standalone 或 Distributed |
Step 13: 加固並部署到正式環境
目的:把本機原型整理成可以長期運作的服務。
先更換預設 root token,再把查詢與寫入流量分開,接著備份 volume,最後在工作量增加時切換到 Helm 或受管部署。
# 正式上線檢查清單
# - 變更憑證
# - 建立資料卷快照
# - 監控查詢延遲
# - 測試還原流程驗收:你應該能重新啟動整套服務,重新連線,並且仍然查到相同的集合與筆數。
常見錯誤
- 用戶端與伺服器版本不一致:如果
pymilvus和 Milvus 次版本不同,請重新安裝對應版本後再做連線驗證。 - 集合尚未載入就查詢:如果匯入後搜尋失敗,先呼叫
load_collection再查一次,並確認載入狀態。 - 向量維度不相符:如果 insert 失敗,請確認嵌入模型輸出的維度與集合 schema 完全一致。
接下來可以看什麼
下一步可以把 reranking、多租戶分區、可觀測性與 Kubernetes 或 Zilliz Cloud 部署加進來,讓這套 RAG 堆疊從可跑的原型升級成可維運的系統。