怎麼做 n8n 進階 RAG
這篇教你在 n8n 裡做一條可上線的進階 RAG 流程,包含切塊、混合檢索、重排序與壓縮。

這篇教你在 n8n 裡做一條可上線的進階 RAG 流程,包含切塊、混合檢索、重排序與壓縮。
這篇給想把基本 RAG 升級成可除錯、可擴充工作流的開發者。照做完,你會得到一份可直接落地到 n8n 的流程藍圖,能分開處理擷取、檢索、重排序、壓縮與生成。
你也會知道每一種進階技巧要解哪一類失敗,像是召回不足、上下文太吵、答案幻覺或引用不穩,方便你逐段驗證與替換。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- n8n 帳號或自架 n8n 實例
- n8n 官方文件
- n8n GitHub repo
- Node 20+
- 一組 LLM 供應商 API key
- 向量資料庫,例如 Postgres + pgvector、Pinecone 或 Qdrant
- 可索引文件,最好帶有 author、topic、timestamp 等 metadata
- 可選:reranking 模型或 API
Step 1: 標記 RAG 失敗點
這一步的產出是「失敗點對照表」,讓你先決定要修的是召回、幻覺、噪音、領域知識不足,還是答案重複。不同問題對應不同技術,避免一開始就把所有複雜度塞進同一條流程。
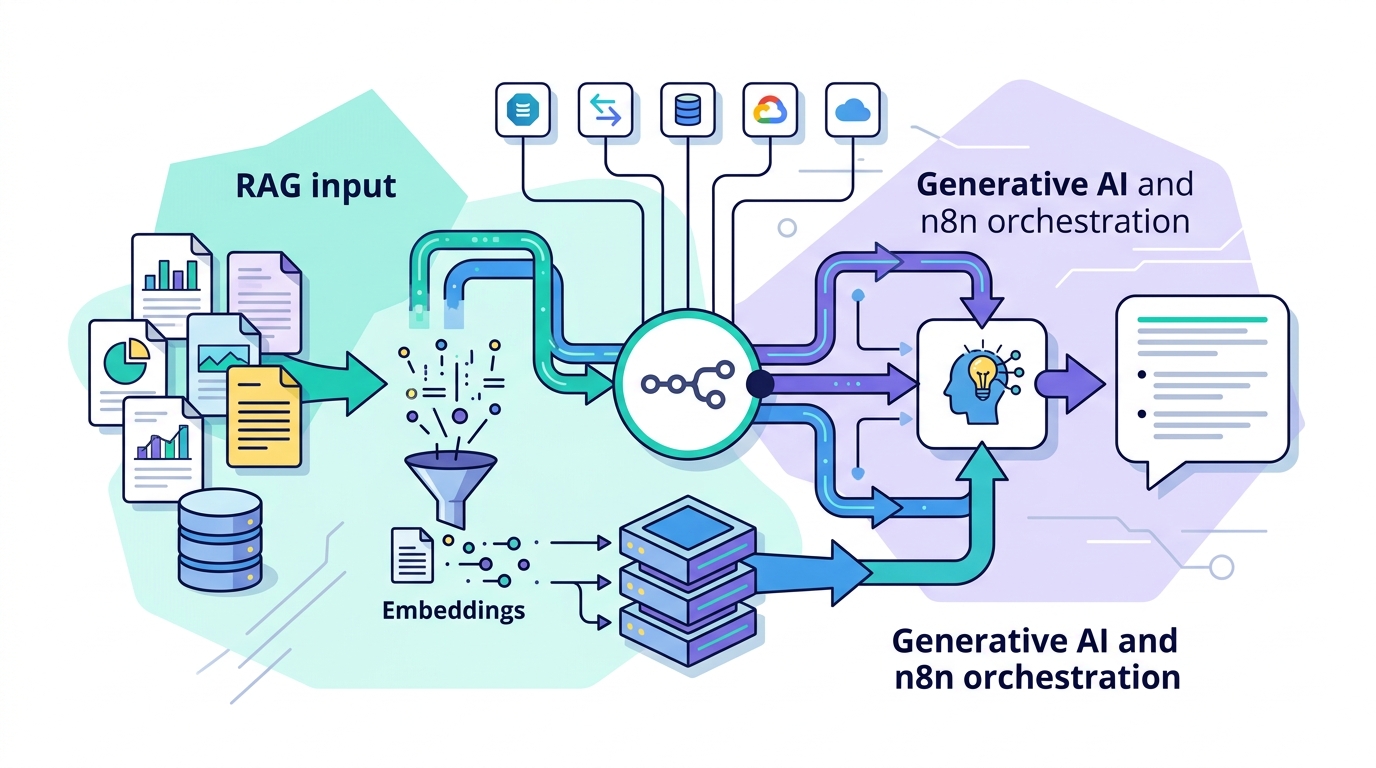
把流程拆成 ingestion、chunking、embedding、retrieval、reranking、compression、generation 七段,並在 n8n 中各自對應一個節點。這樣後面每次調整,都能只看單一節點的效果。
驗收:你應該看到一份「問題 → 對策」清單,且每個問題都能對應到一個具名節點。
Step 2: 清理並切分原始文件
這一步的產出是「乾淨切塊檔」,讓模型更容易取回真正有用的內容。先移除重複段落、模板文字與低價值區塊,再依標題、段落、句子切塊,並保留適當 overlap 以維持語意連續。
// 前處理切塊範例
// 1. 正規化文字
// 2. 依標題、段落、句子切分
// 3. 加入 overlap
// 4. 附上 metadata
const chunk = {
text: cleanedText,
metadata: {
author: 'team',
topic: 'RAG',
timestamp: '2026-05-07'
}
};驗收:你應該看到更小的 chunk,而且同一份文件在重跑時會產生一致的切邊結果。
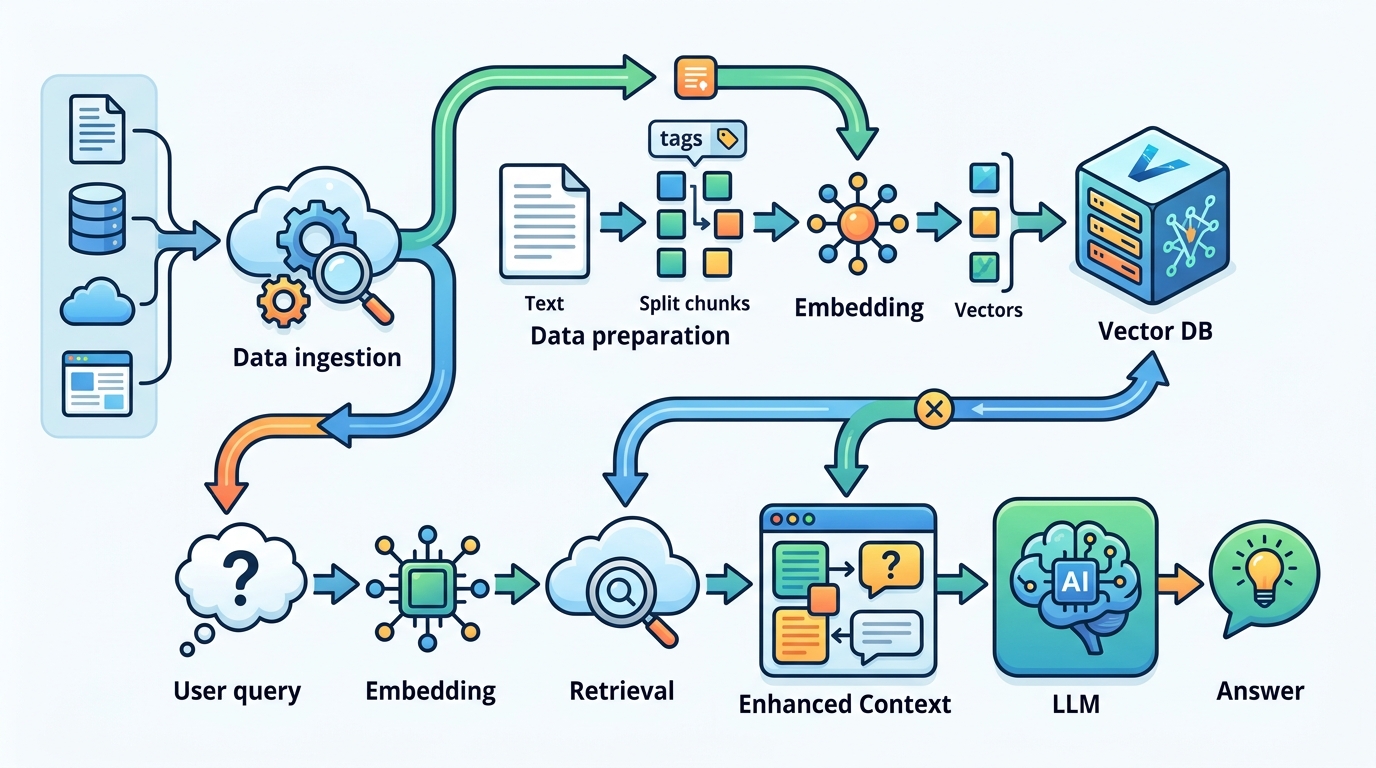
Step 3: 建立帶 metadata 的向量索引
這一步的產出是「可過濾的向量記錄」,讓搜尋不只看語意,也能看來源與情境。先為每個 chunk 產生 embedding,再把 source、document type、recency、topic 等 metadata 一起寫入索引。
在 n8n 裡,建議把 ingestion 與 query path 分開。這樣當你要重新切塊或重建 embedding 時,不會影響線上查詢流程。
驗收:你應該看到每筆向量資料同時包含 embedding 與 metadata,並且至少能用一個 metadata key 做過濾。
Step 4: 串接稠密與稀疏搜尋
這一步的產出是「混合檢索候選集」,讓系統同時處理語意匹配與精確字詞匹配。稠密搜尋負責語意相近,稀疏搜尋負責關鍵字與技術名詞,兩者合併後再交給下一階段判斷。
在 n8n 中,把它做成兩條檢索分支,再用 merge 節點合併結果。這能讓你保留更多候選證據,避免只靠單一路徑漏掉重要內容。
驗收:你應該看到來自兩種搜尋方式的結果,而且合併後的清單會包含單一路徑容易漏掉的項目。
Step 5: 加入 reranking 與壓縮
這一步的產出是「精簡上下文包」,把最相關的證據排到前面。先把候選 chunks 丟給 reranker,讓專門模型按 query relevance 重新排序,再做 contextual compression,刪掉低價值文字。
這一段很重要,因為檢索結果再好也可能太長。壓縮能降低 prompt 大小、減少雜訊,還能把成本壓下來,同時保留能支撐答案的核心來源。
驗收:你應該看到前幾個 chunk 更貼近查詢意圖,而且最終 prompt 明顯比原始檢索輸出短。
Step 6: 驗證來源再生成
這一步的產出是「可追溯回答路徑」,讓每個主張都能對回來源。加入 citation 與 source verification,先檢查引用是否真的支撐回答;若不支撐,就丟回檢索或直接移除。
如果問題很複雜,可以再加 multi-stage retrieval 或 multi-hop retrieval,讓流程分層蒐證,再把多份文件的證據串起來後生成答案。這對跨文件問題特別有用。
驗收:你應該看到每個引用都能連到 source chunk,且未被支持的主張會在送出前被標記。
| 指標 | 基準/優化前 | 結果/優化後 |
|---|---|---|
| Prompt 大小 | 原始檢索上下文 | 壓縮後上下文 |
| 檢索品質 | 單一稠密搜尋 | 混合檢索加 reranking |
| 回答可靠性 | 沒有來源檢查 | 引用與來源驗證 |
| 流程可維護性 | 單體式 RAG 流程 | 可視化節點式工作流 |
常見錯誤
- 所有文件都用同一種 chunk size。修法:改用 recursive 或 hierarchical chunking,並在語意斷點加 overlap。
- 只做 dense embeddings。修法:補上 sparse keyword search,讓精確術語與專有名詞也能命中。
- 把太多原始上下文直接送進 LLM。修法:在生成前加入 reranking 與 contextual compression。
接下來可以看什麼
等這條流程穩定後,可以再往 agentic routing 與 multimodal retrieval 延伸,讓系統能動態選工具,也能處理圖片、音訊與影片。下一步最值得做的是把每個版本的回答品質量化,這樣你就能在不失去可視性的前提下持續調參。