MLOps 是什麼?ML 團隊怎麼上線模型
MLOps 把模型訓練、測試、部署和監控變成可重複流程。這篇用 AWS 的視角,拆解它怎麼運作、為何重要,以及和 DevOps 的差別。
機器學習最常翻車的地方,真的很固定。Notebook 跑得漂亮,上線後卻開始亂飄。AWS 也直接把 MLOps 當成解法,因為模型不會靜止。資料會變,特徵會漂,程式也會改。
講白了,模型不是一次做完就結束。它比較像軟體。要版本控管,要測試,要部署,也要監控和回滾。你如果做過 CI/CD,就會懂這件事只是往資料和模型再延伸一層。
MLOps 到底在做什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
MLOps 是 machine learning operations。意思很直白,就是把機器學習開發和維運接起來。目標不是把模型做出來而已。目標是讓整個流程可以重複跑,而且結果可追。

AWS MLOps 的說法很實際。它不只是工具堆疊。它也是團隊協作方式。資料科學家、工程師、產品人員,要共用同一套流程。這樣模型才不會卡在交接地獄。
你可能會想問,為什麼這麼麻煩。原因很簡單。一般 Web app 壞掉,多半是程式碼問題。ML 系統不是。資料、特徵、訓練參數、推論服務,全都會互相影響。少一個環節,就可能整條鏈炸掉。
- 模型開發通常要做很多次實驗。
- 程式、資料、參數都要版本化。
- 上線後要盯資料漂移和準確率。
- 手動交接會拖慢發布,也難追問題。
為什麼現在更需要 MLOps
傳統 ML 流程看起來很順。收資料、清資料、做特徵、訓練、驗證、上線。問題是,真實世界根本不照這張圖走。資料來源會換,schema 會變,模型也會因為市場行為改變而失準。
沒有 MLOps 的團隊,通常會陷入客製化苦工。有人手動搬 artifact。有人在不同機器重跑訓練。有人說「我本機可以啊」。這種流程一多,重現性就很差。你根本很難知道是哪一步出問題。
再加上現在很多場景都要管合規、權限、偏誤和審計。手動流程會很快失控。MLOps 的價值,就是把模型、資料、程式放進同一個發布節奏。這樣你才回答得出來:這個模型用哪份資料訓練?哪版程式產生?為什麼今天分數掉了?
- 發布速度更穩,不用每次都重來。
- 不同環境的實驗結果更一致。
- 重複工作可以自動化,省人力。
- 模型異常時,比較好追根究底。
MLOps 最重要的四件事
一套像樣的 MLOps,通常離不開四個核心:版本控管、自動化、持續流程、治理。這些詞很像簡報廢話,但落地後差很多。差別就在於,你能不能真的把模型管起來。
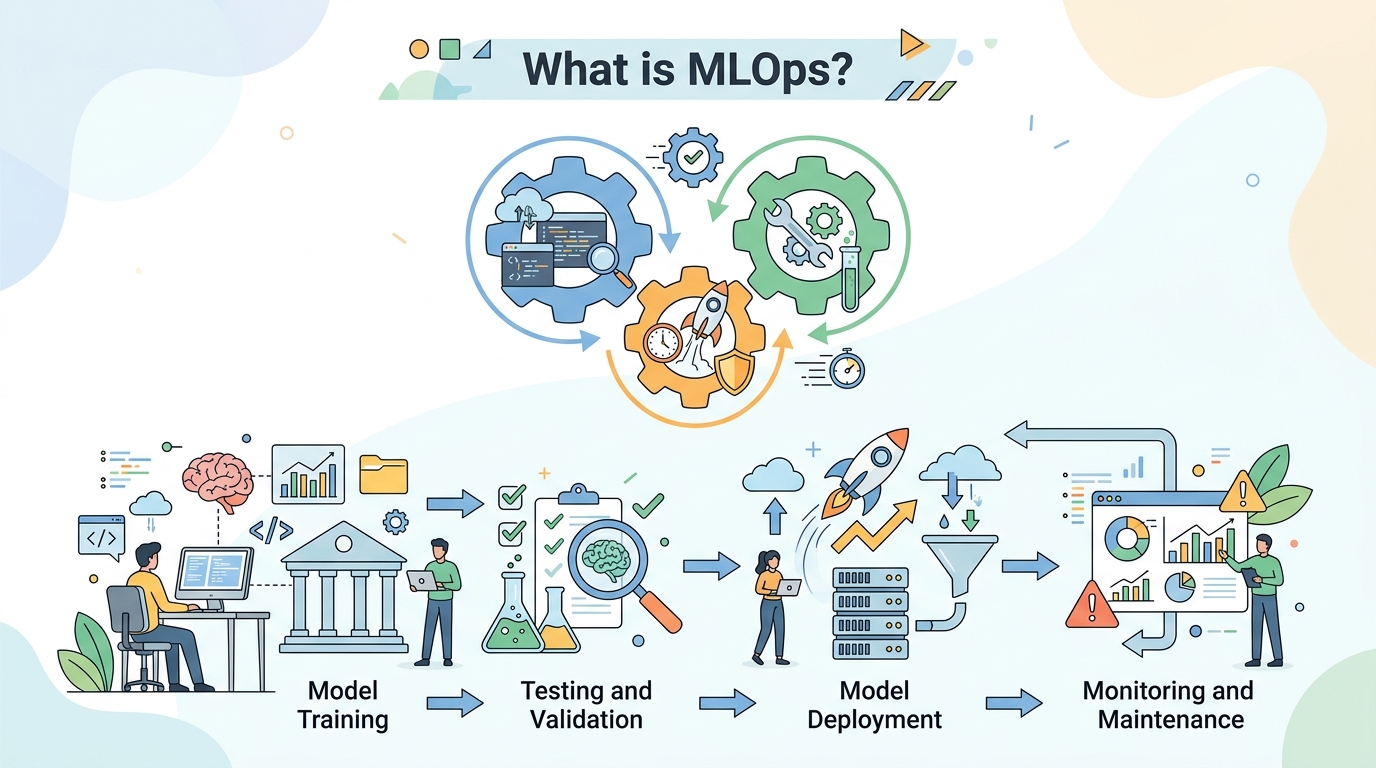
第一個是版本控管。你要能追程式、資料轉換、訓練設定。第二個是自動化。資料匯入、前處理、訓練、驗證、部署,都要能自動跑。第三個是持續流程,像是 CI、CD、CT 和監控。第四個是治理,包含權限、審核、文件和偏誤檢查。
“The practice of machine learning operations (MLOps) is to bring together the development and operations of machine learning systems.” — Google Cloud
這句話很到位。MLOps 的重點,就是把建模和運行之間的洞補起來。兩邊如果分太開,問題會越積越多。你今天改一點,明天壞一塊,最後沒人敢動。
AWS 也強調,測試不能只看程式。ML pipeline 還要測資料品質、模型行為、部署相容性。Infrastructure as code 也很重要。因為你要能在 dev、staging、prod 重建同樣環境。這件事很土,但很有用。
MLOps 跟 DevOps 差在哪
DevOps 和 MLOps 很像親戚,但不是同一件事。DevOps 主要解決軟體怎麼穩定交付。MLOps 則多了一層:資料和模型會漂移。這一層才是麻煩所在。
在 DevOps 裡,常見問題是 code quality、部署安全、服務穩定。在 MLOps 裡,除了這些,還多了訓練資料、feature 一致性、再訓練時機。模型可能沒改程式,表現卻變差。這種事在 ML 世界超常見。
講白了,可以這樣比:
- DevOps:主要管程式碼的測試與發布。
- MLOps:程式、資料、模型一起管。
- DevOps:回滾多半是退回舊版程式。
- MLOps:回滾可能要退程式、模型、特徵定義。
- DevOps:品質看服務行為和穩定性。
- MLOps:還要看準確率、漂移、資料分布。
所以很多團隊會用 model registry、pipeline orchestrator、feature store。這些東西不是炫技。它們是為了讓實驗可比、版本可追、上線可管。像 Amazon SageMaker、MLflow、Kubeflow Pipelines,都是常見選項。
AWS 想讓團隊怎麼做
AWS 把 MLOps 成熟度分成幾個階段。Level 0 比較手工。資料科學家負責訓練。工程師負責部署。Level 1 開始有持續訓練。Level 2 則有 orchestration、model registry 和更完整的 pipeline。
這種分法很實際。因為不是每個團隊一開始就要全套。小團隊可以先把訓練程式版本化,再把部署自動化。之後再補監控和再訓練。大公司就不同,常常一開始就要面對多模型、多團隊、多環境。
我自己的看法很直接。別把模型當一次性檔案。把它當會變動的軟體。你如果答不出模型用哪份資料、誰訓練、何時該重訓,那你還沒真的進入 MLOps。說難聽點,你只是把 notebook 搬到伺服器而已。
接下來 12 個月,我猜會有更多台灣團隊先補 pipeline,再談更大的模型。因為真正卡住的,常常不是演算法,而是流程。你如果現在還靠 Excel 交接和人工重跑,先把流程整理好,會比換更大的 LLM 有效得多。
背景:為什麼 ML 比一般軟體更難管
一般軟體的問題,很多都能靠測試和版本控管解決。ML 不一樣。資料分布會變。使用者行為會變。商業規則也會變。模型今天表現很好,不代表下週還行。
這也是為什麼很多公司一開始玩 ML 很嗨,後來卻卡住。模型 demo 很漂亮,真上線就開始掉分。不是團隊不會寫 code。是他們沒把資料、訓練、推論、監控串成一條線。MLOps 就是在補這條線。
如果你是台灣的軟體團隊,這件事其實很熟。你們早就懂 API、CI/CD、Docker、Kubernetes。MLOps 只是把這套思維往資料和模型延伸。差別在於,你現在要多盯一個變數:模型行為會不會悄悄變壞。
結尾:先把流程做對
如果你現在要開始做 MLOps,我會建議先做三件事。第一,幫模型和資料做版本控管。第二,把訓練和部署自動化。第三,先設最基本的監控。這三件事做完,團隊就會少很多鬼打牆。
下一步很簡單。先問自己一句:我們現在能不能在 10 分鐘內,重建一個上週的模型版本?如果答案是否定的,先別急著追更大的模型。先把流程補起來,才是真的能上線。