MLOps Explained: How ML Teams Ship Models
MLOps turns model training, testing, and deployment into a repeatable process. Here’s how it works, why it matters, and where AWS fits.
Machine learning projects fail in a very predictable way: the model works in a notebook, then production gets messy. AWS says MLOps is the answer, and that matters because ML systems do not stay still. Data changes, features drift, code gets updated, and a model that looked great last week can become unreliable fast.
MLOps is the practice of treating models like software that needs versioning, testing, deployment, monitoring, and rollback. If your team already uses CI/CD for app code, MLOps extends that discipline to data and models too.
What MLOps actually is
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
MLOps, short for machine learning operations, combines machine learning development with deployment and operations. The goal is simple: make the ML lifecycle repeatable instead of improvised. That includes data preparation, model training, validation, release, and infrastructure management.
AWS frames MLOps as a culture and a practice, which is accurate. The tooling matters, but the bigger shift is organizational. Data scientists, engineers, and product teams need a shared process so models can move from experimentation to production without manual handoffs at every step.
That matters because ML systems are more fragile than standard application code. A normal app can often tolerate a slow release cycle. A model pipeline cannot, because training data, feature definitions, and serving code all interact.
- ML projects often involve repeated experiments before a model is fit for production.
- Models need versioning for code, data, and parameters.
- Production systems need monitoring for drift and performance decay.
- Manual handoffs slow releases and make failures harder to trace.
Why teams need MLOps now
The classic ML workflow starts with data collection, then moves into cleaning, feature engineering, training, validation, and deployment. That sounds tidy on paper. In practice, teams deal with multiple data sources, changing schemas, retraining cycles, and constant pressure to ship updates.
Without MLOps, every model release becomes a custom project. Teams copy artifacts by hand, retrain on different machines, and hope the serving environment matches what they tested. That creates avoidable bugs and makes reproducibility a headache. Once you add compliance requirements, access controls, and fairness checks, the manual approach starts to crack.
MLOps reduces that friction by treating models, data, and application code as part of one release process. It also makes it easier to answer basic questions later: Which data trained this model? Which code version produced it? Why did performance change after deployment?
- Faster release cycles for models and prediction services.
- More consistent experimentation across teams and environments.
- Lower operational overhead because repeatable tasks are automated.
- Better troubleshooting when a model behaves differently in production.
The four principles that matter most
A useful MLOps setup usually comes down to four ideas: version control, automation, continuous processes, and governance. Those ideas sound abstract until you map them to real work. Then they start to look like the difference between a system you can trust and one you keep patching.
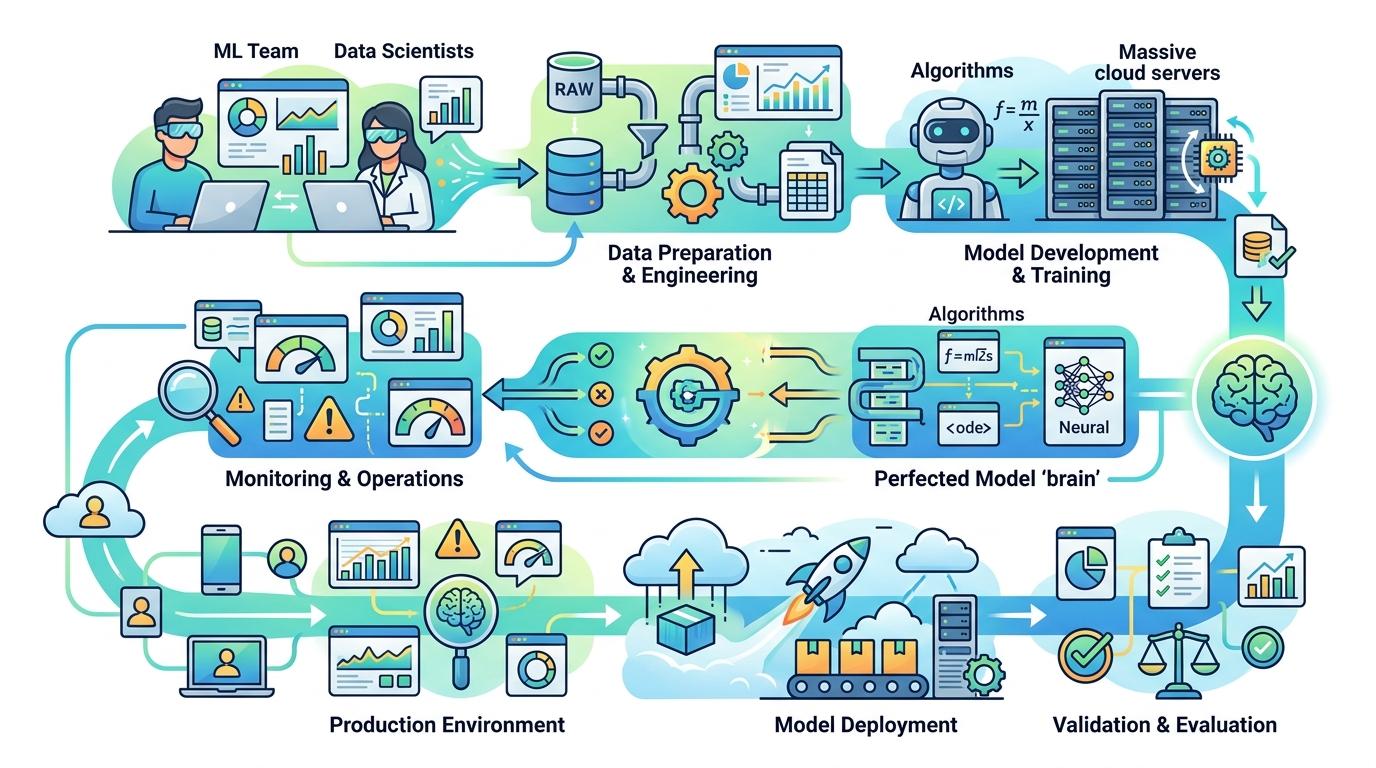
Version control is the first piece. If you cannot track model code, data transformations, and training settings, you cannot reproduce results. Automation is the second piece, covering ingestion, preprocessing, training, validation, and deployment. The third is continuous operation, which includes continuous integration, continuous delivery, continuous training, and continuous monitoring. The fourth is governance, which covers approval workflows, access control, documentation, and bias review.
“The practice of machine learning operations (MLOps) is to bring together the development and operations of machine learning systems.” — Google Cloud
That quote is from Google Cloud’s own MLOps documentation, and it captures the point well. MLOps is about closing the gap between model building and model running. If those two worlds stay separate, production issues pile up quickly.
One detail from AWS is especially worth calling out: automated testing is not just for code. ML pipelines need tests for data quality, model behavior, and deployment compatibility. Infrastructure as code also matters because it lets teams recreate the same environment across development, staging, and production.
How MLOps compares with DevOps
DevOps and MLOps share a family resemblance, but they solve different problems. DevOps focuses on shipping software reliably. MLOps focuses on shipping software that depends on data and model behavior that can drift over time.
With DevOps, the main concern is usually code quality, deployment safety, and operational stability. With MLOps, the pipeline includes those concerns plus training data, feature consistency, and retraining. That extra layer changes everything. A model can degrade even when the code does not change, which is why monitoring is so important.
Here is the practical comparison:
- DevOps: code changes are tested, integrated, and deployed through CI/CD pipelines.
- MLOps: code, data, and models are tested, integrated, deployed, and monitored together.
- DevOps: release quality depends mainly on application behavior.
- MLOps: release quality depends on application behavior, model accuracy, and data drift.
- DevOps: rollback usually means reverting code.
- MLOps: rollback may mean reverting code, model versions, or feature definitions.
That is why MLOps teams often use a model registry, pipeline orchestrator, and feature store. Those pieces keep experiments organized and make it possible to compare versions across environments. Tools like Amazon SageMaker, MLflow, and Kubeflow Pipelines are common choices for teams building that stack.
What AWS wants teams to do next
AWS breaks MLOps maturity into levels. Level 0 is mostly manual, with data scientists handling training and engineers handling deployment. Level 1 adds continuous training and a recurring training pipeline. Level 2 adds orchestration, model registries, and repeated pipeline execution at scale.
The progression is useful because it shows MLOps is not an all-or-nothing project. A small team can start by versioning training code and automating deployment, then add monitoring and retraining later. A larger company may need a full pipeline orchestrator from the start because it runs many models across multiple business units.
For teams using AWS, the main takeaway is straightforward: stop treating a model like a one-off artifact. Treat it like software that changes over time and needs a release process. If your team cannot answer where a model came from, what data trained it, and when it should be retrained, you do not have MLOps yet.
My prediction is simple: the teams that win with ML will be the ones that can ship model updates as predictably as app updates. If your pipeline still depends on spreadsheet handoffs and manual retraining, the next step is not a bigger model. It is a better process.
// Related Articles
- [TOOLS]
Aliyun Bailian Token Plan turns credits into agents
- [TOOLS]
One API gateway turns six AI APIs into one
- [TOOLS]
OpenAI FDEs turn broken agents into shipped systems
- [TOOLS]
Anthropic’s daily brief turns news into a workflow
- [TOOLS]
Claude Reflect turns usage into retention
- [TOOLS]
Midjourney turns prompt ideas into art