OpenAI內容過濾器的標註工廠
OpenAI把數萬條有害文本交給人工標註,再訓練內容過濾器。這篇拆開它的流程、成本、誤殺率與產業脈絡。

2021 年 11 月起,OpenAI把數萬條文本片段交給外包團隊標註。內容很硬,包含暴力、仇恨言論,還有性虐待相關材料。目的很直接,就是先訓練一個檢測器,別讓這些東西先跑到使用者眼前。
這件事沒有什麼神秘感。講白了,就是一條很工業化的流水線。人工先貼標籤,再讓模型學分類,最後接到 ChatGPT 的過濾流程裡。你看到的是一個聊天框,背後其實是一整套髒活拆解系統。
我覺得這才是重點。不是 AI 裡有沒有什麼意識,而是內容審核到底怎麼做。它靠的是人工判斷、資料清洗、分類器和產品層防線。每一層都很土,但少一層就可能出事。
這套系統到底在幹嘛
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這次做的不是聊天模型訓練,而是內容檢測器訓練。流程很像考試。先給模型看一堆樣本,再告訴它哪些是有害內容,哪些不是。最後,它就學會對相似文本做判斷。

大模型本身不會「理解」什麼叫有害。它只是從大量人工標註裡抓統計規律。樣本夠多時,模型就能對侮辱、騷擾、暴力、色情剝削類文本做出不錯的召回率。講白了,就是分類器。
這種系統通常放兩層。第一層看輸入,先擋使用者提示詞。第二層看輸出,防止模型回話踩線。兩層一起上,誤放行機率才會低一點。只靠單層,常常像拿紙板擋子彈。
- 訓練目標:辨識暴力、仇恨、性虐待文本
- 資料量:數萬條文本片段
- 處理方式:人工標註後訓練分類器
- 部署位置:輸入側與輸出側過濾
- 核心指標:誤報率與漏報率
這裡還有一個現實問題。標註不是純技術活。它牽涉語境、文化、黑話、語氣,甚至地區差異。台灣人看得懂的梗,放到別的市場可能完全變味。這也是為什麼內容過濾很難一次做對。
為什麼要找外包人工標註
原因其實不玄。這類工作需要人眼做判斷,而且人要能扛住長時間看噁心內容。機器可以先篩,但第一批標籤通常還是得靠人來定。沒有人工,模型連「什麼叫危險」都學不穩。
肯亞外包公司參與這件事,說明 AI 產業鏈早就全球化了。資料在一國,標註在另一國,產品在第三國。你在手機上看到的安全功能,背後可能是另一個時區的一群人,在逐條看極端文本。這畫面很樸素,也很殘酷。
這也解釋了為什麼很多公司愛講「安全」和「對齊」。這些詞聽起來很高級,落地後就是拆任務、訂規則、做複核。說白了,還是人力密集,只是包裝得比較像 AI。
“The internet is the first thing that humanity has built that humanity doesn’t understand, the largest experiment in anarchy that we have ever had.” — Eric Schmidt
這句話很適合拿來看內容審核。網路內容太多、太雜、太快。任何想做過濾的公司,都得先把混亂變成可分類的資料。沒有這一步,後面全是空談。
外包標註還有一個常被忽略的點,就是成本控制。用美國本土團隊做,薪資和合規成本都高。把流程拆到海外,成本會低很多。這不是什麼陰謀,就是科技公司常見的供應鏈思路。
和其他內容審核方案比,差在哪
OpenAI 這種做法的核心,是把人工經驗轉成可重複使用的分類器。跟純人工審核比,速度快很多。跟純規則過濾比,它比較能看懂變體寫法、拼字變形,還有刻意繞規則的表達。
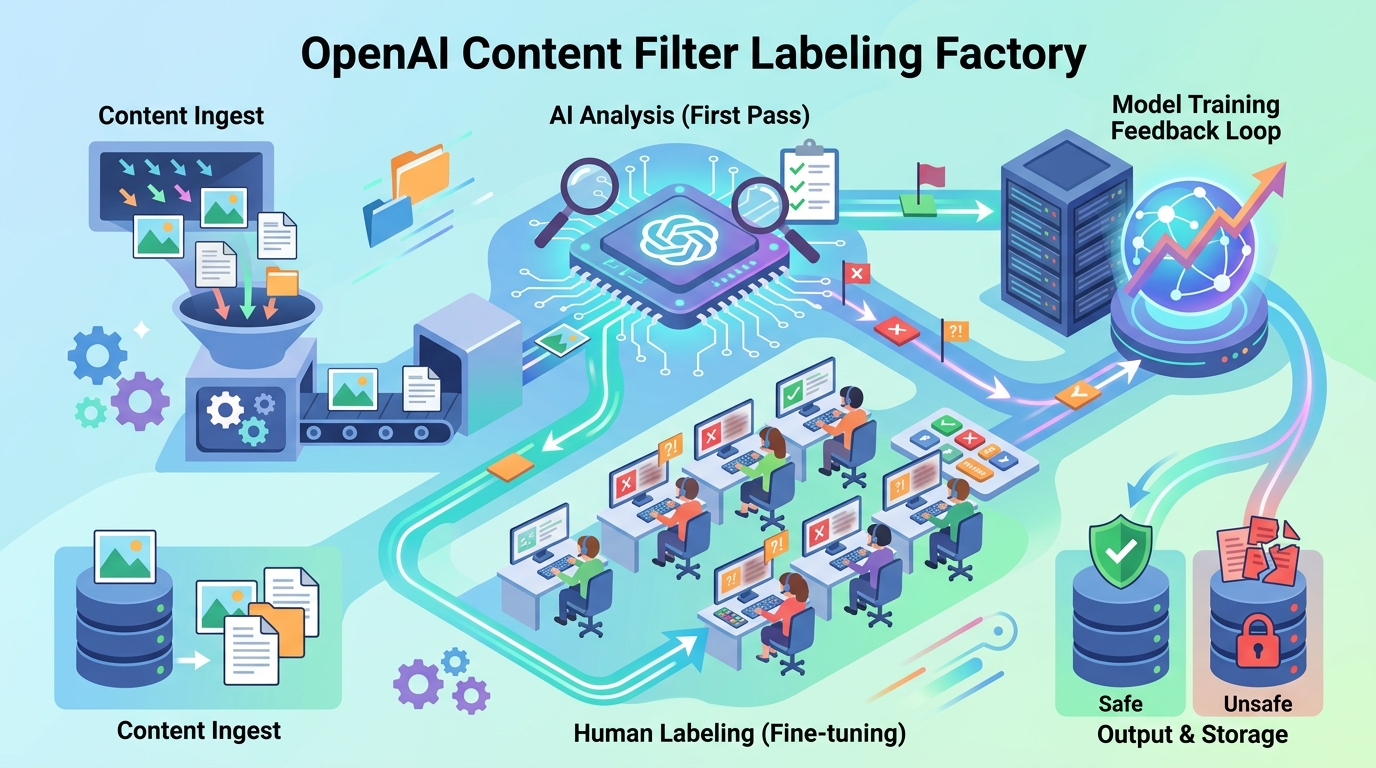
但代價也很明顯。分類器會誤殺正常內容,也會漏掉新黑話。尤其是政治隱喻、次文化術語、諧音梗,模型常常比人還笨。你以為它很聰明,其實它只是很會猜統計模式。
如果把常見方案放一起看,差異就很清楚:
- 純人工審核:準,但慢,成本高
- 關鍵字規則:便宜,快,但最容易被繞過
- 機器分類器:覆蓋廣,能處理變體,但要一直更新
- 混合方案:最常見,效果和成本比較平衡
- 多語系擴充:最麻煩,因為語境差很多
如果看競品,Anthropic、Google AI、Meta AI 都有類似的安全層,只是做法不同。有人偏重憲法式對齊,有人偏重產品端規則,有人偏重大規模審核流程。方向不一樣,但問題都一樣:怎麼少放行危險內容,又不要把正常用戶卡死。
這裡可以直接看數字思維。假設誤報率 2%,漏報率 5%,一個每天 1,000 萬次請求的產品,就會有 20 萬次正常內容被擋,還有 50 萬次危險內容漏掉。這種規模下,任何小數字都會變成大問題。
為什麼 AI 容易被神秘化
AI 很容易被講得像黑箱魔法。原因很簡單。多數人看不到訓練過程,只看到最後輸出。輸入、標註、清洗、微調這些環節都藏在後台,外界當然會開始腦補。
但這條新聞其實很普通。OpenAI 在做內容過濾訓練,而且用了人工標註。這說明的是工業流程,不是超自然秘密。很多時候,最無聊的解釋才最接近真相。
真正該擔心的,不是那些聳動說法,而是標註員的工作環境、資料合規、以及模型誤傷率。這些才是產品安全的核心。你如果只盯著陰謀論,很容易把真正該問的問題丟掉。
再說一次,內容審核不是玄學。它就是一場持續調參的工程。資料變了,黑話變了,模型就得跟著改。你今天擋得住的詞,明天可能就換個拼法再回來。
這件事放回產業脈絡看
內容審核其實是 AI 產業很早就存在的底層工作。從社群平台到搜尋引擎,從廣告投放到影像生成,大家都在做類似的事。差別只是,LLM 把這件事推到更前台了。
以前平台多半處理貼文、圖片、影片。現在 LLM 要處理的是即時對話。這代表風險更快、互動更密、修正窗口更短。你今天放掉一個危險提示詞,幾秒後模型就可能吐出一段不該出現的內容。
所以你會看到更多層的防護。像是輸入過濾、輸出過濾、政策分類器、人工複核、風險回饋。這些東西看起來很瑣碎,但它們就是現在 AI 產品能不能上線的關鍵工程。
從市場角度看,這也意味著一件事:安全不再只是法務問題,而是產品能力。誰能把過濾做穩,誰就比較能放心擴大使用場景。誰做不好,就會一直被公關和合規追著跑。
結尾:別被神秘敘事帶跑
把這件事講成什麼「秘密材料」或「神祕工廠」,其實太戲劇化了。更合理的說法很樸素:OpenAI 用人工標註訓練內容過濾器,目的就是讓 ChatGPT 少吐出危險文本。
接下來比較值得看的是兩件事。第一,這類審核系統會不會擴到更多語言。第二,誤報率能不能壓下來。對使用者來說,最實際的問題不是 AI 有沒有靈魂,而是它會不會把正常內容當垃圾擋掉。
我自己的判斷很直接。未來一年,內容過濾會變得更嚴,也會更細。你如果是開發者,最好開始關心你的產品裡,哪些地方也該加一層分類器。別等到出事了,才回頭補洞。