AWS 用 S3 加速 LLM 微調
AWS 示範怎麼用 SageMaker Unified Studio、S3 和 MLflow,拿 DocVQA 資料微調 Llama 3.2 11B Vision Instruct,並比較 1,000、5,000、10,000 筆資料的訓練效果。
AWS 這篇示範很直白。它拿 SageMaker JumpStart 的 Llama 3.2 11B Vision Instruct 當底。先跑出 DocVQA 的 ANLS 85.3%。再用 Amazon S3 裡的 1,000、5,000、10,000 組影像問答資料去微調。
說白了,重點不是模型名字多長。重點是 AWS 想把 S3 變成 ML 工作流的起點。資料、權限、訓練、評估,都塞進 Amazon SageMaker Unified Studio 裡。這種做法對台灣團隊很實際。因為很多資料本來就躺在 S3,沒人想再搬來搬去。
這篇也很像 AWS 在講一個老問題。很多公司有 PDF、影像、客服紀錄、合約、報表。資料都有。可是真正能拿來訓練 LLM 的流程,常常亂成一團。AWS 想做的事,就是把這些散掉的資料,變成可追蹤的訓練資產。
這次 AWS 到底示範了什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這個範例不是單純跑一個 fine-tune。它是完整流程。先從 DocVQA dataset 找資料。再把 S3 bucket 加進專案目錄。接著發佈成可訂閱的資料資產。最後由另一個專案去取用、前處理、訓練和評估。
這種分工很像真實公司。資料團隊管資料品質和存取。模型團隊管實驗和指標。以前這兩邊常靠 Slack 訊息和共享資料夾硬接。現在 AWS 想把這層關係做成系統功能,而不是靠人記得流程。
另一個實用點是 MLflow。如果你真的要比較 1,000、5,000、10,000 筆資料的效果,光靠 notebook 註解根本不夠。你要知道哪次訓練用了什麼資料、多少成本、結果差多少。沒有追蹤,最後只會剩下一堆「我印象中有變好」。
- 基礎模型:Llama 3.2 11B Vision Instruct
- 基準分數:DocVQA 的 ANLS 85.3%
- 訓練資料量:1,000、5,000、10,000 筆
- DocVQA 訓練資料總量:39,500 筆
- 訓練機型:ml.p4de.24xlarge
這裡還有一個很 AWS 的味道。它不只講模型。它也講專案結構。資料提供者和資料使用者分開。這對大型組織很重要。因為資料治理和模型開發,本來就不該混在同一個腳本裡。
講白了,AWS 這次不是在秀模型多神。它是在秀一條比較像企業會用的路。從 S3 到 Studio,到訓練,到評估。每一步都能留痕跡。這比單純丟一個 demo 網頁有用多了。
為什麼 S3 這層整合很重要
以前很多團隊把 S3 當冷資料倉庫。檔案先丟進去,之後再說。AWS 這次的說法不一樣。它想把 S3 變成 unstructured data 的正式入口。也就是說,PDF、圖片、客服對話、研究資料,都可以直接進 ML 流程。
這個方向對企業很合理。因為大多數有價值的資料,根本不是乾淨的 CSV。它們是掃描檔、合約、內部文件、工單、email、聊天紀錄。這些東西如果不能直接進訓練流程,資料團隊就得一直做人肉搬運。
更實際的是權限設計。這次流程用 Amazon S3 Access Grants 拿暫時性憑證,再把資料同步到本地環境訓練。這比長期金鑰安全很多。也比較符合企業內部稽核的需求。
"The integration between Amazon SageMaker Unified Studio and Amazon S3 general purpose buckets makes it straightforward for teams to use unstructured data stored in Amazon S3 for machine learning and data analytics use cases."
這句話很像 AWS 的核心論點。它不是在說資料會自動變聰明。它是在說,讓資料從 bucket 走到訓練環境,不該再是一堆手工步驟。這個差別很大。因為流程一亂,後面所有實驗都會亂。
還有一個很現實的點。AWS 提到某些 run 會跑超過 4 小時。它也建議 JupyterLab space 設 6 小時 idle timeout,第一輪完整執行要準備 100 GB 儲存空間。這些數字很重要。因為 demo 跟真的上線,差的就是這種細節。
1,000、5,000、10,000 筆資料差在哪
這次最有價值的地方,是它不是只跑一個訓練結果。AWS 故意做三組資料量。1,000、5,000、10,000 筆。這樣你才看得出來,資料增加到底值不值得。這比只貼一個漂亮分數誠實多了。
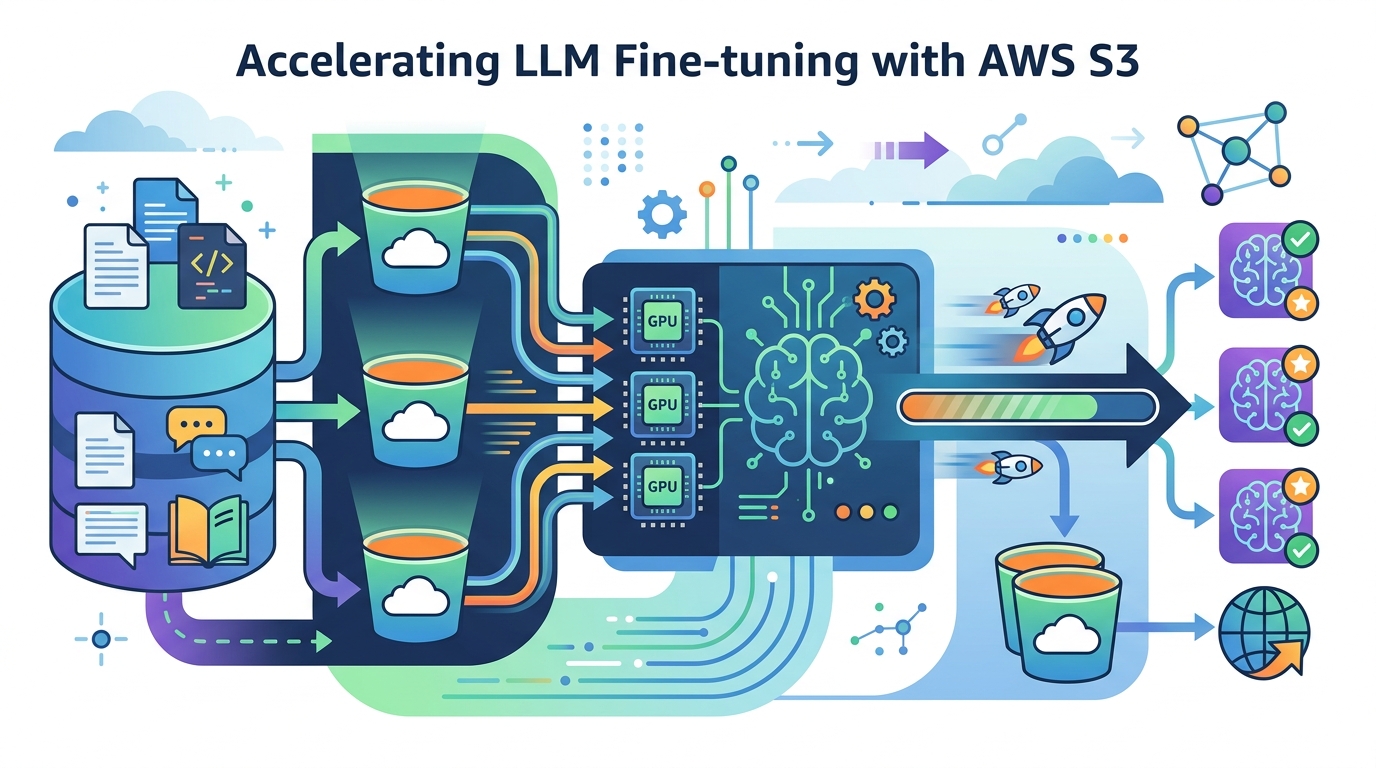
對做文件理解的團隊來說,這種比較很實用。因為訓練成本不便宜。尤其是 ml.p4de.24xlarge 這類機型,錢燒得很快。如果 1,000 筆就接近 10,000 筆,那你幹嘛多花錢。反過來,如果 10,000 筆真的能拉開差距,那就有理由加資料。
AWS 沒有在節錄裡直接貼完整比較表,但實驗設計已經很清楚。基準模型先有 85.3% ANLS。之後所有 fine-tune 都用同一個評估指標。這代表比較是公平的。至少不是今天換 metric,明天換資料切法。
- 資料來源:Hugging Face 的 DocVQA
- 訓練切片:前 10,000 筆
- 驗證切片:前 100 筆
- 目標:提升文件影像問答準確率
- 指標:Average Normalized Levenshtein Similarity
ANLS 這個指標很適合文件任務。因為它會容忍一點字串差異。像日期格式不同,或標點不一樣,不該直接判死刑。文件問答不是寫作文。你要的是答案對,不是字面完全一樣。
如果拿別家方案比,AWS 這套比較像平台打法。它不是只賣模型 API。它是把資料、權限、訓練、追蹤串起來。跟單純用開源框架自己拼流程相比,省的是整合時間,不是只有算力。
這對 AWS 使用者代表什麼
如果你的原始資料本來就放在 S3,這套流程會少掉很多麻煩。你不用一直搬檔案。也不用每個專案都重做一套存取規則。資料資產先進目錄,再由不同團隊訂閱。這種方式很適合有治理需求的公司。
我覺得 AWS 真正在推的,是一種資料產品化的工作方式。不是把檔案丟進 bucket 就算完。你要先想好 metadata、權限、版本、評估方式。這聽起來很麻煩,但對企業來說其實比較省事。因為後面少很多鬼打牆。
對開發者來說,最直接的建議很簡單。下一次你要做 fine-tuning,先把資料 bucket 整理好。先定義誰能看。先決定怎麼追蹤實驗。不要等模型跑起來才補流程。那樣通常只會把技術債做大。
這波其實是在拚資料工作流
如果把這篇拆開看,AWS 真正在意的不是 Llama 3.2 本身。因為那只是起點。它想證明的是,S3 裡的非結構化資料,可以直接進到企業級 ML 工作流。這對 AWS 很合理。因為它最強的本來就是雲端資料和權限管理。
這也能看出 AWS 跟其他平台的差別。很多工具很會做模型,但資料治理弱。很多開源方案很自由,但整合成本高。AWS 想站在中間。它要你在同一個地方,把資料、訓練、追蹤、分享都做完。
說真的,這條路不浪漫。也不帥。可是企業買單時,常常就是看這種東西。誰能少掉 3 個腳本、2 組權限、1 堆人工搬檔,誰就比較有機會進正式流程。
下一步你該看什麼
我會先看兩件事。第一,10,000 筆資料到底比 1,000 筆多多少分。第二,這套流程從 demo 變成正式專案時,設定成本會不會暴增。這兩個答案,會決定它是好看的範例,還是真的能落地。
如果你的團隊也在做文件理解、客服自動化、合約抽取,我會建議先從 S3 的資料治理下手。把資料分類、權限、版本和評估指標先定好。之後再談模型。這樣比較不會一邊訓練,一邊救火。
接下來最值得觀察的,是 AWS 會不會把同一套流程擴到更多場景。像支援工單、內部知識庫、保險文件、法遵審查。這些場景都很吃非結構化資料。誰先把工作流做順,誰就比較有機會把 LLM 變成日常工具。