OpenAI内容过滤器背后的标注工厂
OpenAI把数万条有害文本送去人工标注,用来训练ChatGPT过滤器。它为什么要这样做?
2021年11月起,OpenAI把数万条文本片段发给肯尼亚外包公司进行标注,这些材料里有暴力、仇恨言论和性虐待内容。目标很直接:训练一个检测器,让它在用户看到之前先拦住类似内容。
这件事很容易被阴谋论包裹,但真正值得看的不是“AI里是不是藏了谁的意识”,而是内容审核这门生意到底怎么运转。它依赖大量人工判断、脏数据清洗、模型分类器和产品层过滤,整个链条都很朴素,也很残酷。
这套系统到底在做什么
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
OpenAI这次做的,不是训练一个会聊天的模型,而是训练一个用于识别有害文本的检测器。简单说,就是先给一堆样本贴标签,再让模型学会分辨相似文本,最后把结果接进ChatGPT的内容过滤流程里。
这种做法在AI行业里很常见。大模型本身不会“理解”什么是有害内容,它只是从人工标注里学到统计模式。只要样本够多,模型就能对某些侮辱、骚扰、暴力、色情剥削类文本做出高召回率判断。
这类系统通常会被放在两处:一处在生成前做输入侧检查,另一处在生成后做输出侧审核。前者拦截用户提示词,后者过滤模型回复。两层都上,误放行的概率才会下降。
- 训练目标:识别暴力、仇恨、性虐待等文本
- 数据来源:数万条文本片段
- 处理方式:人工标注后再训练分类器
- 部署位置:ChatGPT内容过滤链路
为什么偏偏要找外包人工标注
原因并不神秘:这类工作需要人眼判断,而且要有人能接受长时间接触恶心内容。机器可以做筛选,但第一批标签往往还是得靠人来定。
肯尼亚外包公司参与这类工作,说明AI产业链早就全球化了。训练数据、标注劳动力、审核流程,分别分布在不同国家。用户在美国、欧洲或亚洲看到的一个“安全”功能,背后可能是一群远程标注员在逐条看极端文本。
这也解释了为什么很多AI公司会强调“安全”与“对齐”。这些词听上去抽象,落到执行层面,就是把大量脏活拆成标准化任务,再交给标注团队和审核系统处理。
“The internet is the first thing that humanity has built that humanity doesn’t understand, the largest experiment in anarchy that we have ever had.” — Eric Schmidt
这句话虽然不是专门谈内容审核,却很适合这里。互联网内容太多、太杂、太快,任何想做过滤的公司都得面对同一个现实:先把混乱变成可分类的数据,再谈规则。
和其他内容审核方案比,差别在哪
OpenAI这类做法的重点,是把人工经验转成可复用的分类器。和纯人工审核比,它的速度更快;和纯规则过滤比,它更能识别变体写法、拼写变形和语义绕过。
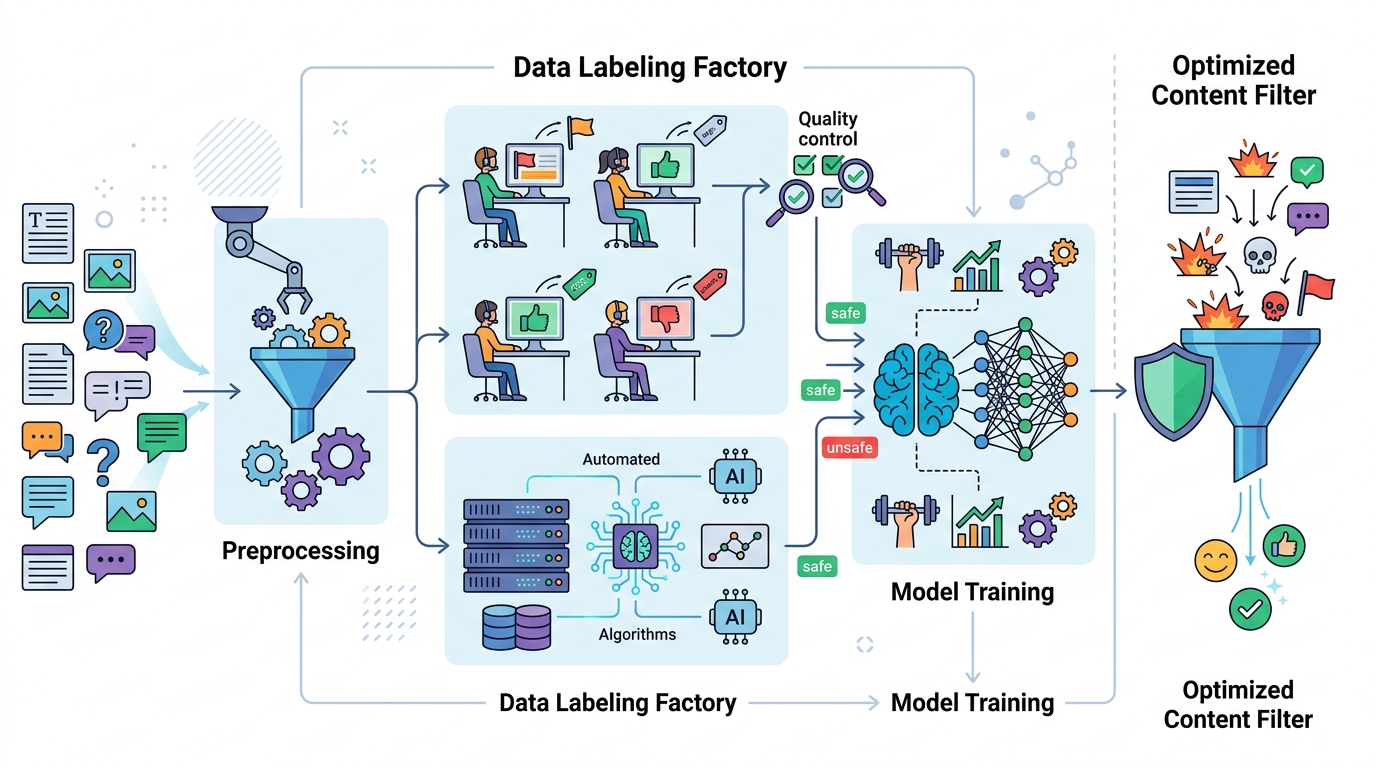
但代价也明显。分类器会误杀正常内容,也会漏掉新型规避表达。尤其是涉及政治隐喻、黑话、俚语时,模型常常比人更笨。为了减少误伤,产品团队通常得不断回收样本、重新标注、再训练。
如果把它和常见的审核路径放在一起看,差异会更清楚:
- 纯人工审核:准确率高,但慢,成本也高
- 关键词规则:便宜,速度快,绕过也最容易
- 机器分类器:覆盖面广,能处理变体,但需要持续迭代
- 多层混合方案:最常见,成本和效果最平衡
从工程角度看,OpenAI这类系统并不神秘。真正难的是把它做得足够稳定,同时别把正常用户体验弄坏。审核太松,平台会被垃圾内容淹没;审核太严,用户会觉得模型像个动不动就罢工的保守派。
为什么阴谋论总会缠上AI
AI很容易被神秘化,因为大多数人看不到训练过程,只能看到最终输出。输入、标注、清洗、微调这些环节都藏在后台,外界只看见一个会说话的接口,于是很自然地开始脑补“它到底吃了什么”。
但从这条新闻本身看,最重要的信息其实很普通:OpenAI在做内容过滤训练,而且用了人工标注。这个流程说明的是工业化审核,不是超自然秘密。
真正值得警惕的,是人们对AI黑箱的误解会被反复利用。有人拿它编故事,有人拿它制造恐慌,还有人借机把正常的工程问题说成阴谋。结果是,大家讨论的重点被带偏,真正该问的问题反而没人问:这些标注员的工作条件怎么样,数据处理合规吗,过滤器误伤率有多高。
如果你关心的是产品安全,那么更应该盯住两个指标:误报率和漏报率。前者决定用户会不会被过度拦截,后者决定平台会不会放出真正危险的内容。AI审核不是玄学,就是一场持续调参的工程活。
结论:别被神秘叙事带跑
把“失踪人口意识”这类说法放到这条新闻里,基本属于把普通的数据标注工作往神秘主义方向硬拽。更合理的解释很无聊,也更接近现实:OpenAI在用人工标注训练内容过滤器,目的就是让ChatGPT更少输出危险文本。
接下来更值得关注的,不是这些文本“像不像某种秘密材料”,而是这类审核系统会不会继续扩大到更多产品、更多语言和更多地区。如果未来你发现模型越来越谨慎,背后多半不是“意识被抽出来了”,而是标注、过滤和审核这三件事又被加码了一轮。
// Related Articles
- [IND]
Circle’s Agent Stack targets machine-speed payments
- [IND]
IREN signs Nvidia AI infrastructure pact
- [IND]
Circle launches Agent Stack for AI payments
- [IND]
Why Nebius’s AI Pivot Is More Real Than Hype
- [IND]
Nvidia backs Corning factories with billions
- [IND]
Why Anthropic and the Gates Foundation should fund AI public goods