為什麼 Pi MCP Adapter 才是使用 MCP 的正確方式
Pi MCP Adapter 才是使用 MCP 的正確方式,因為它在保留工具能力的同時,大幅降低 token 浪費。
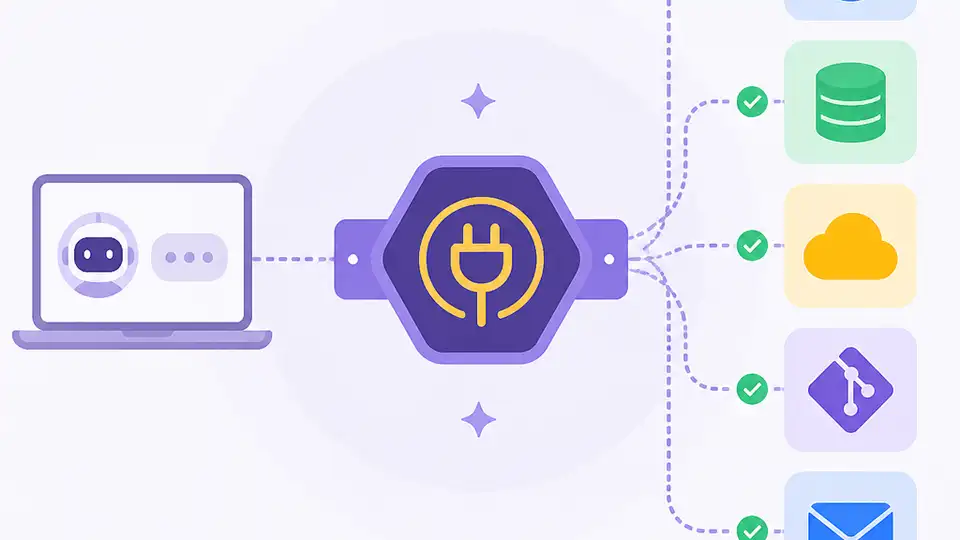
Pi MCP Adapter 在保留工具能力的同時,大幅降低 MCP 的 token 浪費。
Pi MCP Adapter 才是 MCP 的正解,因為它保住工具生態的實用性,卻把上下文成本壓到接近單一代理工具的水位。
GitHub 倉庫的描述已經把問題講得很直白:一個 MCP server 可能在工具定義上先吃掉 10k 以上 token,模型還沒開始工作,成本就先付出去了。這不是抽象的效率問題,而是每一次對話都在被課稅。Pi 的做法是先暴露一個約 200 token 的 proxy tool,再按需載入工具。差別很明確,前者是還沒開工就先丟掉半個上下文窗,後者是把上下文留給真正的任務。
第一個論點:MCP 的預設形狀太浪費
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
很多人批評 MCP 時,真正打到的其實不是協議本身,而是常見實作方式。若 agent 一開始就得吞下一整包工具清單,模型付出的成本和實際會不會用到那些工具無關。Pi MCP Adapter 的價值在於把 discovery 變成 lazy loading:先查 metadata,再只呼叫需要的工具。這不是包裝術語,而是直接改寫成本結構。
倉庫裡的範例說得更具體:原本要把 26 個 tool definitions 塞進 prompt,現在可以先搜尋,再用一個精簡 JSON 呼叫目標工具。兩次互動,取代 26 份定義在上下文裡排隊。這件事重要,是因為 context 不是免費資源。每多一個工具 schema,就少一點空間留給使用者真正的需求。
第二個論點:能持續的 UI,比一次性的工具呼叫更有價值
Pi MCP Adapter 不只是壓縮層,它還支援可持續的對話式 UI,這才是實用性真正升級的地方。adapter 透過 mcp({ action: "ui-messages" }) 取回訊息,並在共享 session 中回應。當 agent 在同一個工具上再次操作時,新的結果會推進到既有視窗,而不是把前一次輸出整個覆蓋掉。這代表使用者看到的是一個活著的介面,不是一串可丟棄的工具回傳。
如果 agent 要做的不只是補字,這種互動就是必要條件。圖表可以在原地迭代,瀏覽器任務可以保留狀態,使用者也能在不失去介面的情況下回覆提示。倉庫把這稱為 live updates,這個命名是對的。Agent 真正變得有用,不是因為它吐出更多結果,而是因為它能透過持續存在的畫面協作。
反方可能怎麼說
最強的反對意見是:Pi 的做法多加了一層,層數一多,複雜度就可能被藏起來而不是消失。倉庫引用的 Mario 批評並不荒唐,如果某個流程只需要幾個簡單 CLI 工具,那為什麼還要把 MCP 放進堆疊裡?對工具集合很小、流程很穩定的團隊來說,直接腳本確實更好理解,也更好控管,少了 proxy、metadata cache 和 adapter 設定檔這些間接成本。
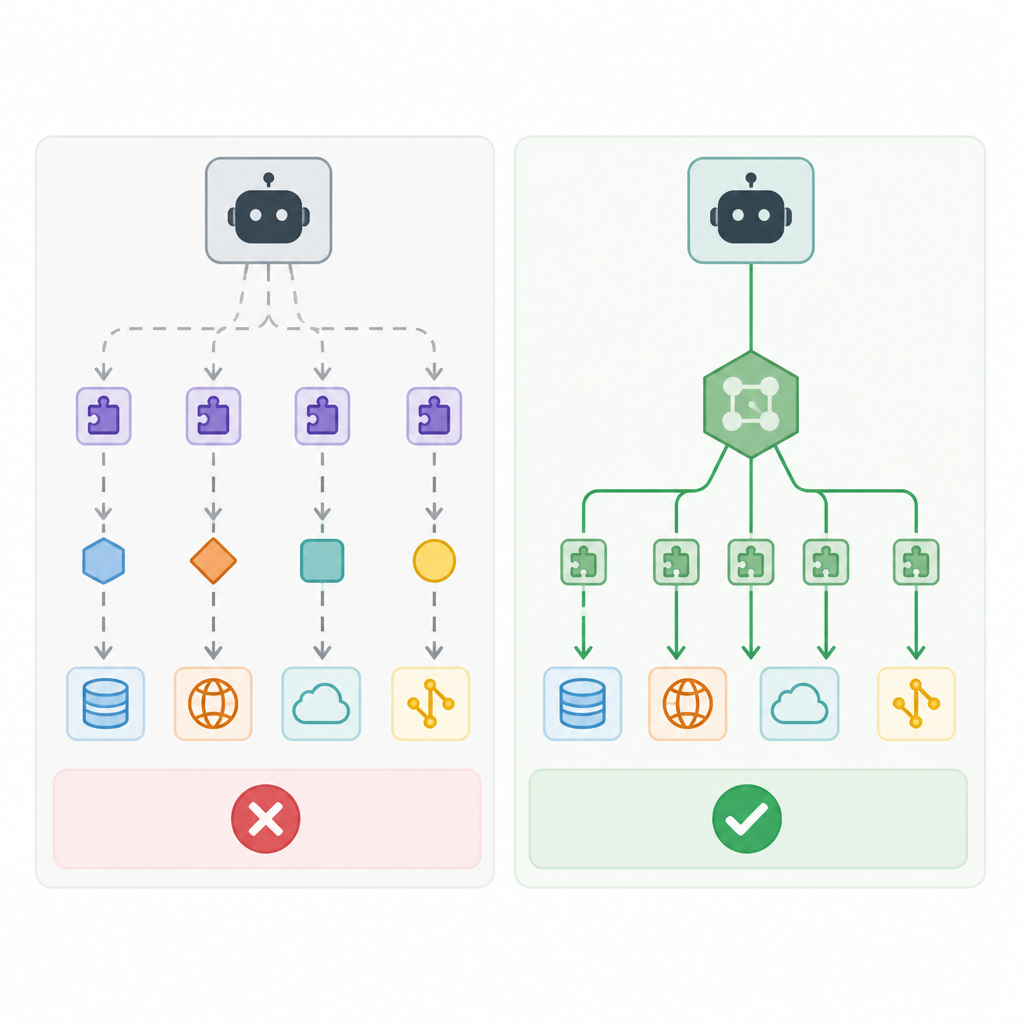
這個批評在一個狹窄情境裡成立:工具很少,工作流固定,MCP 真的只是多餘儀式。但多數 agent 團隊面對的不是這種世界。只要你需要瀏覽器、資料庫、API 和 UI surface 同時協作,單靠「直接寫 CLI」就會迅速失去擴展性。Pi 的答案不是否認複雜度,而是把代價說清楚:保留 MCP 生態,移除 prompt 稅。對多工具 agent 來說,這是更合理的工程選擇。
你能做什麼
如果你是工程師、PM 或創辦人,別再把工具暴露當成「全部塞進上下文」和「完全不用 MCP」的二選一。面對廣泛工具生態,優先採用 proxy-first 的 adapter 模式;只有少數真的需要第一時間可見的命令,才直接暴露。把 lazy loading 設成預設值,若產品包含互動式 UI,就立刻導入 session reuse 和 in-place updates。你該衡量的不是能宣告多少工具,而是你到底為真正的任務保留了多少上下文。