LLMs work by predicting the next token
A clear guide to how LLMs are trained, tuned, and used, with 5 practical pieces of the model pipeline.

Large language models predict tokens, learn from huge text corpora, and adapt through fine-tuning.
Large language models are easier to understand when you break them into five parts: training data, tokenization, transformer attention, parameter learning, and post-training alignment. IBM notes that some popular models now have billions or trillions of parameters, which explains both their power and their cost.
| Item | What it does | Key detail |
|---|---|---|
| Tokenization | Splits text into machine-readable units | Words, subwords, or characters |
| Transformer attention | Tracks relationships between tokens | Uses query, key, and value vectors |
| Parameters | Store learned model behavior | Can reach billions or trillions |
| Fine-tuning | Adapts a base model for a task | Includes RLHF for alignment |
| Small language models | Run with fewer resources | Fit smaller devices and tighter budgets |
1. Training data at massive scale
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
LLMs start with huge text collections pulled from books, articles, websites, code, and other sources. The model is not memorizing a single document; it is learning patterns across a broad mix of language so it can generalize to new prompts.
That training pipeline depends on careful cleanup. Data scientists remove duplication, errors, and unwanted content before the model ever sees the text. This matters because bad inputs can distort what the model learns and can also carry forward bias or noise.
- Sources: books, articles, websites, code
- Prep steps: cleaning, deduplication, filtering
- Goal: expose the model to varied language patterns
2. Tokenization turns text into units
Before training, text is broken into tokens, which may be words, subwords, or characters. Tokenization gives the model a consistent way to process language, including rare terms and new words it has never seen in exactly that form.
This is one of the most practical ideas in LLMs: the system does not read like a person does. It reads sequences of tokens, then predicts what token should come next based on patterns it learned during training.
- Token types: word, subword, character
- Benefit: consistent handling of rare and novel words
- Result: language becomes machine-readable input
3. Transformers use self-attention
LLMs are built on transformer models, and the transformer’s self-attention mechanism is the core reason they work so well with language. Self-attention lets the model weigh relationships between tokens, including tokens that are far apart in a sentence or paragraph.
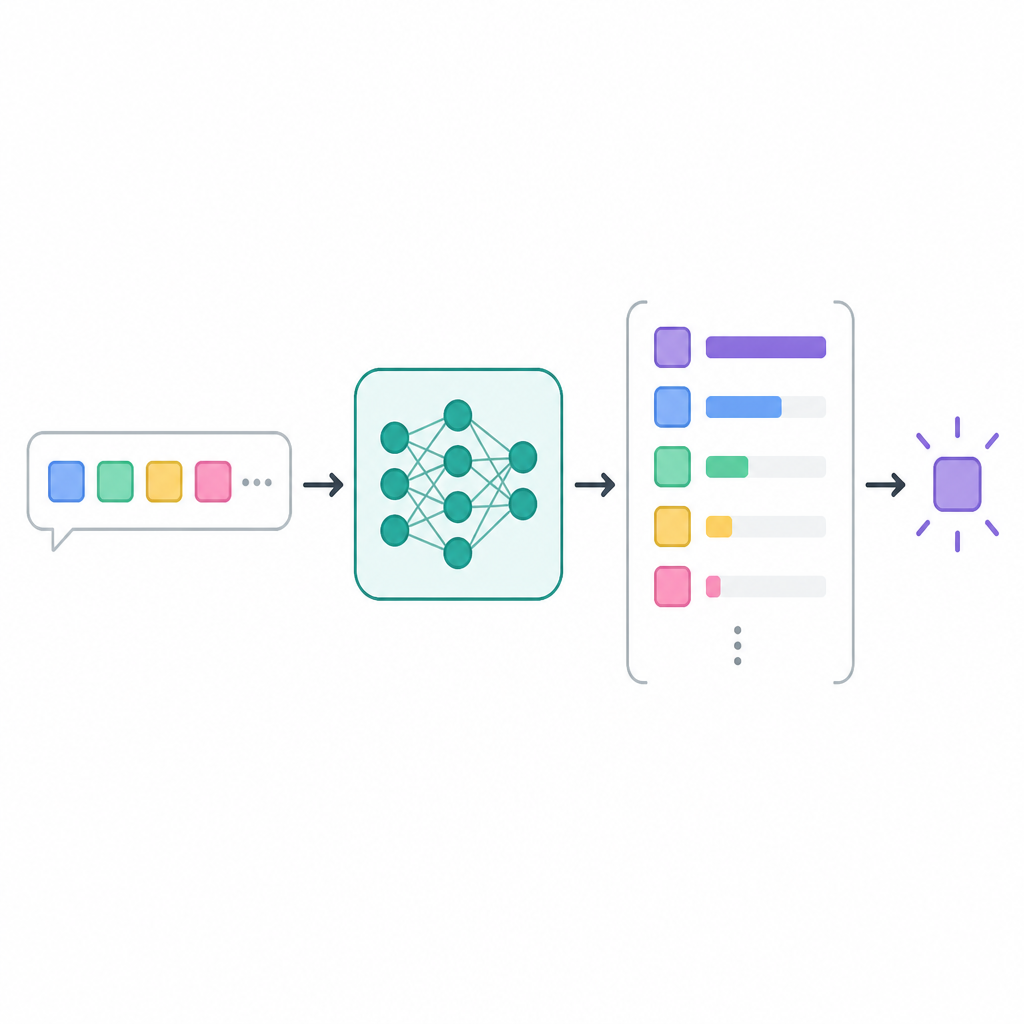
IBM describes this as the model calculating which parts of the sequence matter most at each moment. Each token becomes a query, key, and value vector, and those vectors are compared to decide how much information should flow forward.
token -> embedding -> query/key/value -> attention weights -> output
4. Parameters store what the model learns
During training, the model adjusts internal weights called parameters. These are the configuration values that shape how the network processes input and produces output, and modern LLMs can contain billions or even trillions of them.
That scale is why LLMs can pick up grammar, factual patterns, reasoning structures, and writing styles. IBM also notes that smaller language models exist for constrained environments, where fewer parameters make deployment easier on local or resource-limited hardware.
- Parameters: internal weights learned during training
- Scale: billions or trillions in large models
- Small models: better for smaller devices and tighter compute budgets
5. Fine-tuning and RLHF shape behavior
After pretraining, an LLM can be fine-tuned for a specific job, such as customer support, summarization, or code help. This second stage adjusts the base model so it performs better in a target setting instead of just being generally fluent.
One common method is reinforcement learning from human feedback, or RLHF. Humans rank outputs, and the model learns to prefer responses people rate higher, which helps with alignment, meaning outputs are more useful, safe, and consistent with human values.
- Fine-tuning: adapts a general model to a task
- RLHF: uses human rankings to improve outputs
- Alignment goal: useful, safe, consistent responses
How to decide
If you want the shortest mental model, remember this: LLMs are token predictors trained on massive text, powered by transformer attention, and shaped by post-training methods like fine-tuning and RLHF. That is the core path from raw data to useful output.
If you care most about deployment, focus on parameters and model size. If you care most about behavior, focus on fine-tuning and alignment. If you care most about the engine under the hood, focus on tokenization and self-attention.