8 步驟打造可上線的 LangChain RAG
這篇教你用 LangChain、向量資料庫、LangSmith 與 FastAPI,從文件匯入一路做到可部署、可追蹤、可維運的生產級 RAG。
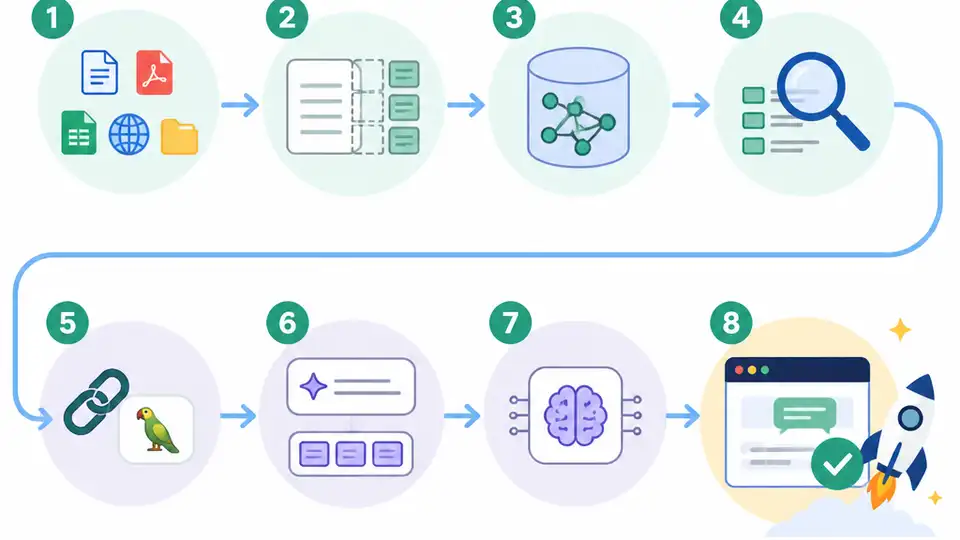
這篇教你用 LangChain、向量資料庫、LangSmith 與 FastAPI,從文件匯入一路做到可部署、可追蹤、可維運的生產級 RAG。
這篇給已經做過基礎檢索增強生成原型的開發者。你照著做完,會拿到一套能處理文件匯入、切塊、向量索引、檢索、觀測、API 驗證與部署的實作流程。
本文第一次提到的工具都附上官方文件或專案連結,方便你邊做邊對照:[LangChain 文件](https://python.langchain.com/docs/)、[LangChain GitHub 倉庫](https://github.com/langchain-ai/langchain)、[Chroma](https://www.trychroma.com/)、[Chroma GitHub 倉庫](https://github.com/chroma-core/chroma)、[Supabase pgvector 文件](https://supabase.com/docs/guides/database/extensions/pgvector)、[LangSmith 文件](https://docs.langchain.com/langsmith/)、[LangGraph GitHub 倉庫](https://github.com/langchain-ai/langgraph)。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- Python 3.11+
- Node 20+,如果你要另外跑前端或測試工具
- Docker 24+
- LangSmith 帳號與 API key
- Supabase 帳號與專案,若要用託管 Postgres 與 pgvector
- OpenAI API key,或其他 embedding 與聊天模型供應商金鑰
- Git 2.40+
- 具備 RAG、embedding、向量搜尋的基本概念
Step 1: 建立專案工作區
先把專案拆成資料匯入、索引、服務三個區塊,避免一開始就變成難以維護的筆記本原型。這樣後面除錯時,你才知道問題是出在切塊、索引,還是 API。
mkdir production-rag && cd production-rag
python -m venv .venv
source .venv/bin/activate
pip install langchain chromadb fastapi uvicorn langgraph langsmith supabase psycopg[binary] python-dotenv你應該看到虛擬環境成功啟動,套件也順利安裝完成。接著執行 python -c "import langchain, chromadb, fastapi",如果沒有任何錯誤訊息,就代表工作區已經可用。
Step 2: 匯入並切分文件
這一步的目標是把原始文件變成適合檢索的文字區塊,並保留來源資訊。之後你要回答「這段答案從哪裡來」時,metadata 會直接派上用場。
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = DirectoryLoader("./docs", glob="**/*.md")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=120,
)
chunks = splitter.split_documents(docs)
print(len(docs), len(chunks))你應該看到切出來的 chunk 數量大於原始文件數量。這表示切分器已經把長文件拆成更適合檢索的單位,不會整份文件一起塞進索引。
Step 3: 建立向量索引
這一步要把文件嵌入後存進向量資料庫,讓系統能做語意搜尋。本機開發先用 Chroma,正式環境則可以改成 Supabase 搭配 pgvector,部署和權限管理都比較好控管。
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db",
)
vectorstore.persist()你應該看到本機資料夾被建立,或是資料成功寫入 pgvector 資料表。接著做一次相似度搜尋,如果回傳的是語意相關的段落,而不是隨機文字,就代表索引已經正常。
Step 4: 串接檢索與回答生成
這一步要先做出最小可用的 RAG 流程,確認「先找資料,再回答」的核心行為真的成立。只要這條主幹正確,後面再加優化才有意義。
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
query = "RAG 裡的 hybrid search 是什麼?"
results = retriever.invoke(query)
print(results[0].page_content[:200])你應該看到最相關的 chunk 出現在第一筆結果。若內容明顯對應查詢主題,表示 embedding、切塊與索引策略大致對齊,可以進入觀測與部署階段。
Step 5: 開啟觀測與追蹤
到了正式環境,檢索失敗常常不會直接報錯,只會回錯答案。這一步的產出是可在 LangSmith 看到的完整追蹤紀錄,讓你能檢查提示詞、檢索結果、延遲與最終回應。
import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = "your-key"
os.environ["LANGSMITH_PROJECT"] = "production-rag"
# 執行一次 chain,然後到 LangSmith 檢視 trace。你應該在 LangSmith 儀表板看到新的 run,裡面包含 retriever 輸出與模型回應。這會比只看主控台 log 更快找出是哪一步出問題。
Step 6: 加上驗證並提供 API
這一步的目標是把 RAG 包成可部署服務,並先擋掉未授權請求。正式上線時,驗證、輸入檢查、環境變數管理都不能省。
from fastapi import FastAPI, Header, HTTPException
app = FastAPI()
API_TOKEN = os.getenv("RAG_API_TOKEN")
@app.get("/answer")
def answer(q: str, authorization: str = Header(default="")):
if authorization != f"Bearer {API_TOKEN}":
raise HTTPException(status_code=401, detail="Unauthorized")
return {"query": q, "status": "ok"}你應該能用 Uvicorn 啟動服務,沒有 token 時拿到 401,有 token 時拿到 200。這代表 API 閘門已經先於檢索邏輯生效。
Step 7: 調整混合搜尋與 token 預算
這一步要讓檢索更穩定,因為單靠語意搜尋有時會漏掉專有名詞、型號或程式符號。混合搜尋能補上關鍵字訊號,token 預算則能避免上下文爆掉與模型費用浪費。
# 建議流程
# 1. 先做向量相似度搜尋
# 2. 再做關鍵字或 BM25 搜尋
# 3. 合併並重新排序結果
# 4. 只保留符合 token 預算的上下文你應該看到含有產品名、程式碼符號或稀有詞的問題,答案品質明顯提升。若最後送進模型的 prompt 仍然低於上下文上限,就表示預算控制有在運作。
Step 8: 用 LangGraph 編排多路徑流程
最後一步是把單一路徑 RAG 升級成可分支、可重試、可多跳推理的流程。當問題類型不同時,系統可以走不同節點,而不是硬套同一條鏈。
from langgraph.graph import StateGraph
# 定義 retrieve -> grade -> refine -> answer 節點
# 加上 fallback search 或多模態文件處理分支
# 編譯圖後逐一路徑測試你應該看到不同類型的查詢觸發不同路徑,例如一般事實題、多跳題、或文件圖片題。這表示系統已經不是只會單次檢索,而是具備進階生產行為。
| 指標 | 基準/優化前 | 結果/優化後 |
|---|---|---|
| 答案可追溯性 | 只能人工翻 log | LangSmith 追蹤可直接看到檢索片段 |
| 檢索品質 | 只有單一向量搜尋 | 結合關鍵字與語意訊號的混合搜尋 |
| 部署準備度 | 筆記本原型 | 具備 token 驗證的 FastAPI 服務 |
常見錯誤
- 切塊太大。修法是把 chunk_size 調小,先用幾個真實問題回測再定稿。
- 沒開觀測。修法是先啟用 LangSmith trace,再開始調整提示詞。
- 把所有 chunk 都塞進 prompt。修法是加上 top-k、重新排序與嚴格 token 預算。
接下來可以看什麼
下一步可以延伸到重排序、評估資料集、多模態檢索,以及代理式備援流程,讓你的 RAG 系統能處理更難的問題與更髒的資料。如果你要對照完整作法,可以再往 GraphRAG、ColPali 類型的多模態檢索與生產部署主題深入。