5 步建出 1930 截止 LLM 測試台
用 5 個步驟建立一個 1930 截止的 LLM 測試台,驗證歷史推理與無污染泛化。

用 5 個步驟建立一個 1930 截止的 LLM 測試台,驗證歷史推理與無污染泛化。
這篇給 ML 工程師、研究科學家與平台團隊看,目標是把一個只吃 1931 年以前英文文本的實驗管線做出來。照著做完,你會得到可追溯的歷史語料、去時間污染的篩選流程、OCR 清理後的訓練資料、古典指令微調資料,以及一套能和現代基線對照的評估流程。
這個做法適合用來研究歷史推理、資料污染、以及模型在截止日期之後的泛化能力。你也會直接看到 OCR 品質、日期過濾與後訓練資料設計,如何和模型規模一樣重要。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- Python 3.11+
- CUDA GPU,至少 28 GB VRAM,適合 13B 模型
- PyTorch 2.4+
- Hugging Face 帳號與模型權重存取權
- Git 2.40+
- OCR 工具,例如 Tesseract 5+ 或自建文件 OCR 管線
- 可取得歷史語料,包含書籍、報紙、期刊、專利與判例
- 選用:偏好最佳化用的 judge model API key 或本地模型
參考實作可先看專案頁、論文與 demo,再對照原始碼與權重。第一次出現的公開資源可從 Talkie-1930 demo、MarkTechPost 專案介紹 與其連結的 GitHub、模型資源開始。
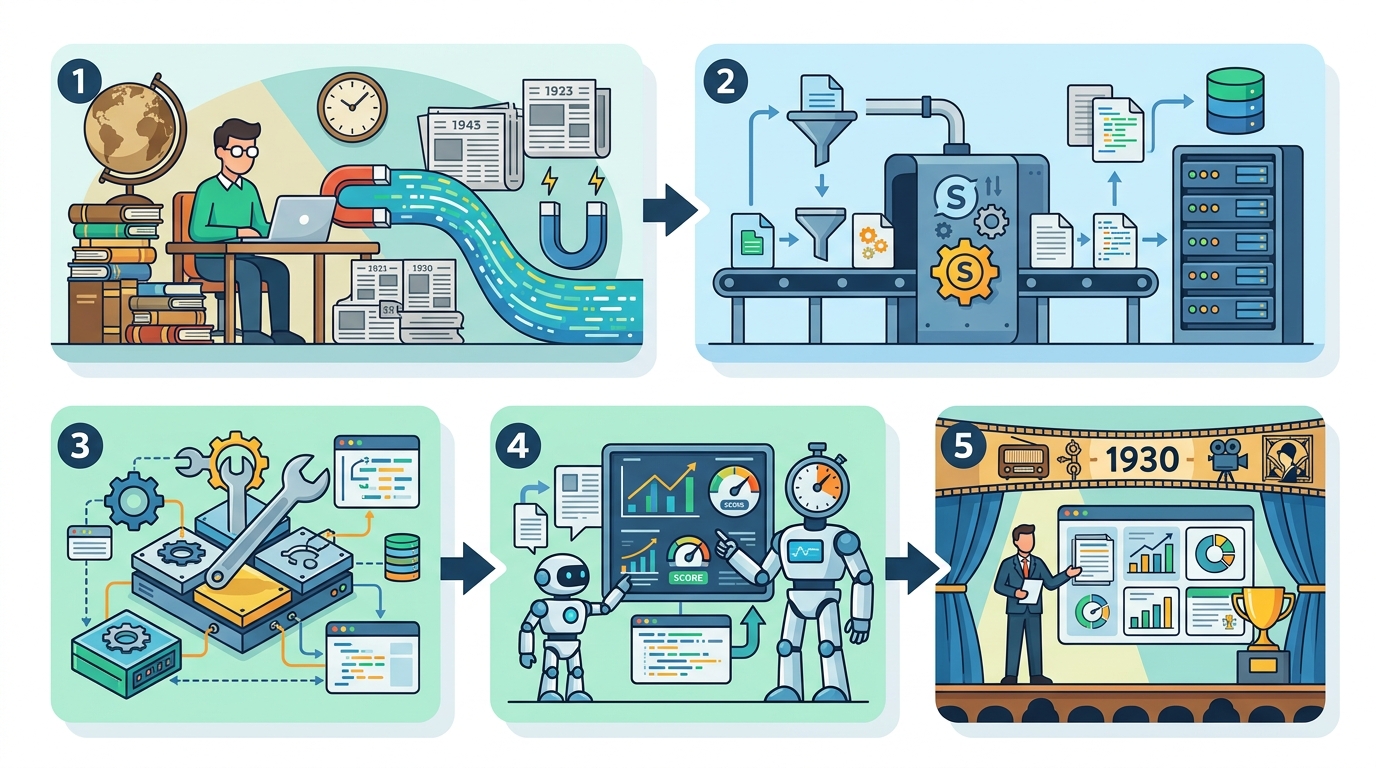
Step 1: 組裝 1931 前語料清單
目的:建立一份日期明確、可稽核、且法律上可用的歷史語料清單,讓模型的知識截止日清楚可查。
先收集公有領域英文文本,來源包含書籍、報紙、期刊、科學雜誌、專利與判例。每筆資料都要保留 metadata,尤其是出版日期、來源類型與掃描來源。再替每個項目建立穩定 ID,確保訓練 token 能回溯到原始實物。
python build_corpus.py \
--sources books,newspapers,journals,patents,case_law \
--cutoff-date 1930-12-31 \
--output corpus/manifests/pre1931.jsonl你應該看到一份 manifest,裡面每個文件都被驗證在 1930-12-31 以前。抽查一筆記錄時,source、publication year 與 scan path 都應該存在。
Step 2: 排除時間污染文件
目的:移除不合時代的內容,避免誤標日期、後來重印版或編者註把 1930 之後的知識帶進模型。
做一個文件層級的篩選器,把日期檢查和 n-gram 或分類器式的時代錯置偵測一起用。把提到 1930 年後事件、技術或人物的頁面標記出來,並排除 metadata 不確定的項目。這一步很關鍵,因為只靠日期欄位,仍可能漏掉污染樣本。
實作上,建議保留一個 quarantine 集合,先把可疑文件丟進去,再人工複核後決定是否納入正式語料。若要重現 Talkie-1930 類型的實驗,這個步驟不能省,因為清單正確不代表內容一定乾淨。
你應該看到語料規模下降,外加一份 leakage report。好的驗收訊號是,隨機抽樣內容不再出現明顯的 1930 後引用,例如第二次世界大戰、現代電腦或更晚的政治事件。
Step 3: 轉 OCR 並清理掃描頁
目的:把頁面影像轉成可訓練文字,同時把歷史掃描常見的雜訊降到最低。
先對每一頁掃描檔做 OCR,再處理斷字、頁首頁尾、邊註與連字形變體。若條件允許,拿一小段人工轉錄資料當基準,對照普通 OCR 與清理後文本的差異。這類歷史資料的問題通常不是只有識別率,而是版面和字形造成的系統性錯誤。
python ocr_pipeline.py \
--input scans/ \
--engine tesseract \
--cleanup rules/historical_regex.yml \
--output text/ocr_cleaned/你應該看到頁級對齊的文字檔,以及一份品質報告,裡面包含 character error rate、token retention 與 cleanup gains。若清理後樣本仍有斷行、重複頁首或怪異空白,先修 preprocessing rules,再進入訓練。
Step 4: 用歷史 token 訓練 base model
目的:把基礎模型限制在 1930 截止世界的語言分布中,讓它只學歷史語料的模式。
使用標準 causal language modeling 設定,但資料流必須保持純歷史。token 數量要精準追蹤,參考專案使用過約 2600 億 token。checkpoint 要定期存,並在保留的 1931 前文本上算 perplexity,確認模型是在學分布,而不是背掃描雜訊。
為了可重現,請固定 tokenizer、sequence length、optimizer 與 mixed precision 設定。若你要做現代對照組,請用相同架構與超參數,在當代語料上訓練一個 twin model,這樣比較才公平。
你應該看到 training loss 穩定下降,且 held-out historical perplexity 持續改善。健康的訊號是,模型能以符合年代的語氣續寫文本,而且不會冒出現代用語。
Step 5: 用古典指令後訓練並評估
目的:讓模型學會跟隨指令,但不把現代聊天習慣或當代知識帶進來。
把 pre-1931 來源整理成 instruction-response 對,例如禮儀手冊、書信指南、食譜書、字典、百科全書、詩集與寓言集。接著做 supervised fine-tuning,再用 judge model 做 preference optimization。參考管線會再加一輪合成對話,提升指令跟隨能力,同時維持歷史約束。
python post_train.py \
--base_model checkpoints/talkie_base \
--instruction_data data/vintage_instructions.jsonl \
--dpo_judge claude-sonnet-4.6 \
--output checkpoints/talkie_it你應該看到五分量表上的指令遵循分數上升,對話回應也更實用。評估時,請同時測 anachronistic 與已過濾的 benchmark,再和你的 modern twin 對照,才能看出差距是來自歷史截止、OCR 雜訊,還是主題不匹配。
常見錯誤
- 只靠日期欄位過濾。修法:加上時代錯置分類器,並對可疑文件做人工複核。
- 直接拿原始 OCR 文本訓練。修法:先套清理規則,再用人工轉錄子集驗證。
- 後訓練混入現代指令資料。修法:只從 1931 年以前的手冊、百科與類似來源萃取 prompt 與答案。
另一個常見問題是低估硬體需求。13B 模型要能跑得穩,通常需要仔細調整 batch size 與 CUDA 記憶體餘裕;若你要多節點擴充,還要固定資料順序與 checkpoint 命名,才能讓歷史實驗可重現。
接下來可以看什麼
如果這條管線已經跑通,下一步可以擴到更大的歷史語料、加入更適合舊版排版的 OCR 模型,並做預測、時間驚奇與程式泛化的控制實驗。再往下,你就能把 1930 截止模型和現代 LLM 並排比較,觀察哪些能力依賴網路時代知識,哪些其實來自語言建模本身。