為什麼瀏覽器代理需要真正的執行層,而不是另一個包裝器
BrowserAct 的方向是對的:AI 代理需要真正的網頁執行層,而不是又一個脆弱的瀏覽器包裝器。
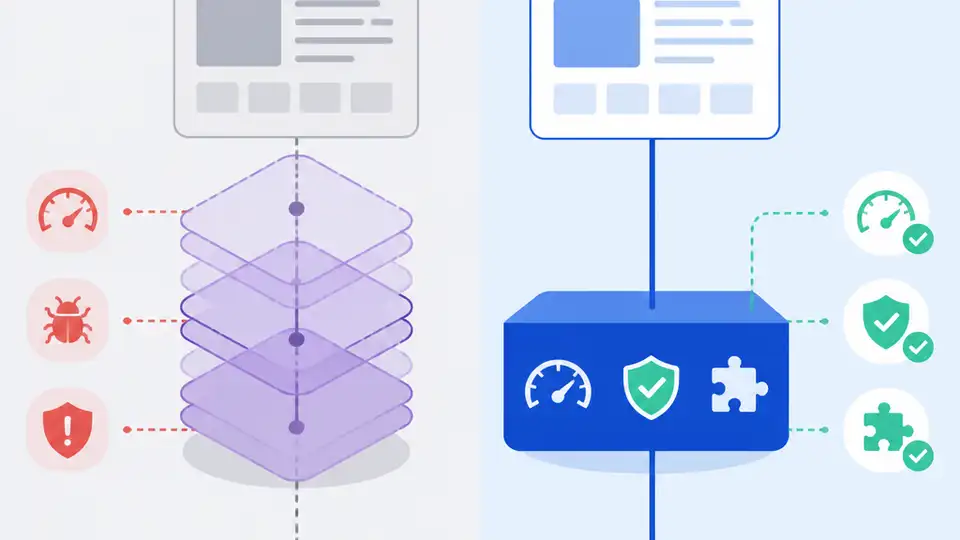
BrowserAct 的重點是:AI 代理要能在真實網站上穩定執行,不能只靠脆弱的瀏覽器包裝器。
BrowserAct 說對了一件事:瀏覽器自動化不是再包一層 Puppeteer 就能解決的問題,而是 AI 代理缺少一個真正的執行層。它開源的 browser-act 與 browser-act-skill-forge,不只是抓資料工具,而是在處理一個已經在生產環境反覆出現的失敗模式:代理可以推理,卻無法可靠地操作動態網站、登入流程和反機器人機制。
這次釋出的內容夠具體,足以證明方向不是空話。BrowserAct 宣稱 browser-act runtime 可以用隔離指紋、獨立 cookie jar、可選住宅 IP 路由去驅動真實瀏覽器,而 browser-act-skill-forge 則能先探索一次網站,再把行為封裝成可重用的 Skill。這代表系統不再要求代理每次都重新學一遍同一個網站,而是先建立可持續執行的能力,再把學到的流程沉澱下來。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
第一個原因很直接:真實網路本來就不是為自動化設計的。文中提到 Cloudflare、DataDome、hCaptcha 這類防機器人系統,已覆蓋全球前 10,000 大網站中的 40% 以上。這表示大量高價值流程早就被入口管制,若代理連門都進不去,模型再會推理也沒有用。
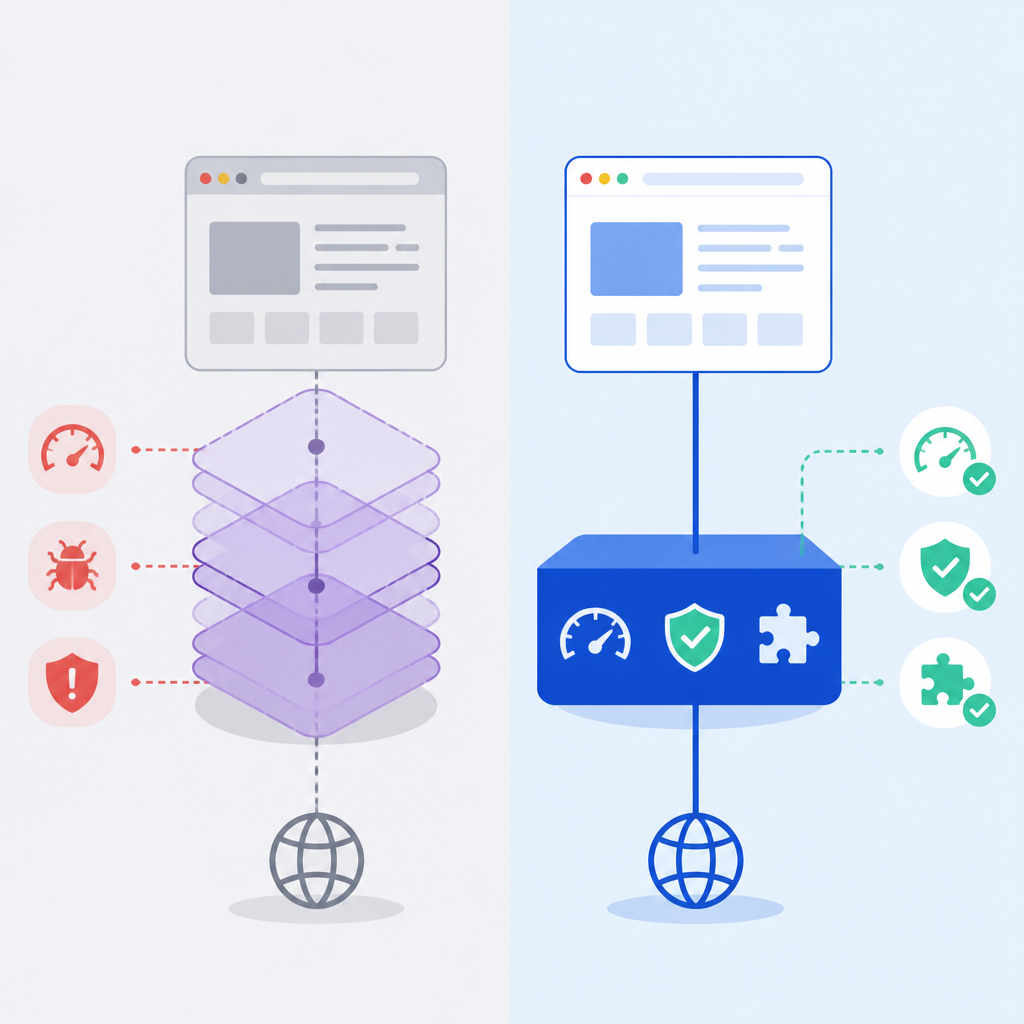
這也是傳統瀏覽器工具一直失敗的原因。一般工具可以點擊、輸入,但它仍然像自動化程式。網站改版會打壞 selector,登入流程會變,CAPTCHA 會冒出來,代理就開始重試、燒 token、再失敗。BrowserAct 強調瀏覽器身份隔離、session 分離與人工接手,不是裝飾,而是代理在現代網路上存活的最低條件。
第一個論點
第二個原因是:可重用的技能,比一次性的抓取程式更重要。若代理每次跑同一個網站都要重新摸索路徑,那你做出來的不是自主系統,而是多了一個語言模型的昂貴腳本。這種系統看起來很聰明,實際上只是在重複消耗成本。
BrowserAct 的 browser-act-skill-forge 正好對準這個痛點。以一個利基電商站、定期庫存檢查、或分頁式工作流為例,Forge 先探索一次、驗證可行路徑,再產出可部署的 Skill,附帶指南與腳本。之後代理直接呼叫 Skill,不必每次重學。這帶來的不只是速度,而是組織記憶,流程可以重用、共享,也比手寫 scraping code 更不容易因版面調整而失效。
第二個論點
第三個原因是經濟性。BrowserAct 把輸出做成結構化資料,而不是把原始 HTML 原封不動丟回模型,這是正確下注。文中聲稱,Skills 回傳 JSON 而非 raw HTML,帶來 93% 的 token 消耗下降。這件事很重要,因為多數 agent 管線浪費成本的地方,不是推理本身,而是讀了太多雜訊。
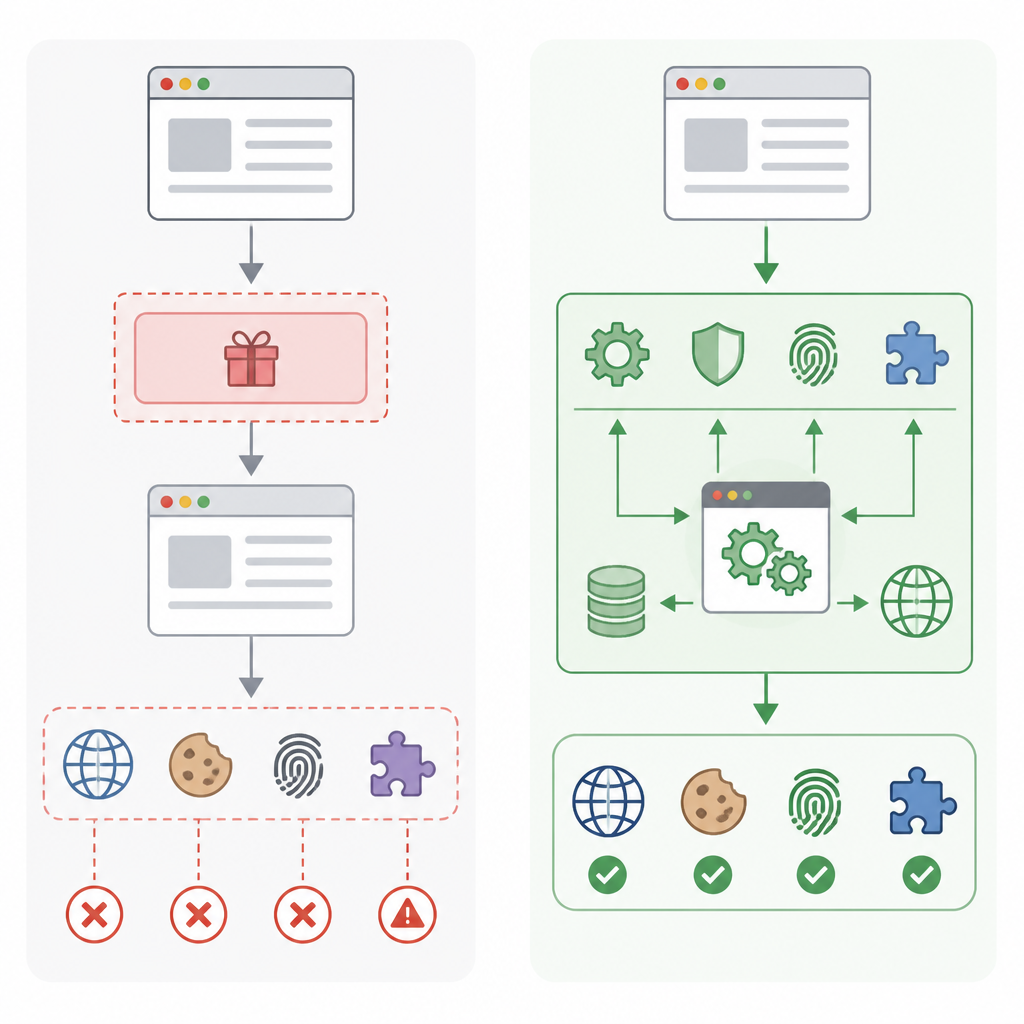
原始頁面內容冗長、噪音高、容易誤讀,模型花的 token 常常是在做頁面考古,不是在做決策。若代理能把網頁行為抽象成結構化工具,網路就不再只是一次性輸入流,而是工具圖譜。這才是可擴展的路徑,也才是避免代理變得脆弱、臃腫、昂貴的唯一辦法。
反方可能怎麼說
最強的反對意見是:BrowserAct 的框架其實是在鼓勵一場與網站治理機制的軍備競賽。指紋隨機化、CAPTCHA 處理、住宅代理、Chrome takeover,聽起來都像是在繞過平台防線,而不是建立可信任的自動化。批評者會說,如果你的產品依賴把機器人偽裝成人類,那你就是在優化對抗網站本身的治理層。
這個質疑不是空穴來風,尤其是針對代理路由與隱匿瀏覽這一層。它確實碰到邊界問題,但不足以推翻整體論點。真正的價值不是為了規避而規避,而是建立一個受控的執行層,去完成使用者本來就有權手動執行的任務。BrowserAct 對 Skill Forge 的限制其實是正確的:它只能做使用者在自己瀏覽器裡本來就能做的事。這條限制不是缺點,而是把耐久自動化和濫用清楚切開的分界線。
你能做什麼
如果你是工程師、PM 或創辦人,別再問模型夠不夠聰明,先問它有沒有穩定的執行、復原與重用能力。把流程設計成結構化 Skill,而不是臨時拼湊的 scraping 腳本;對身份驗證和高風險步驟保留人工接手;凡是會重複執行的工作,都應該被沉澱成可重用能力,而不是每次重新解一次。這樣做,代理系統才會從表演變成真正可運作的基礎設施。