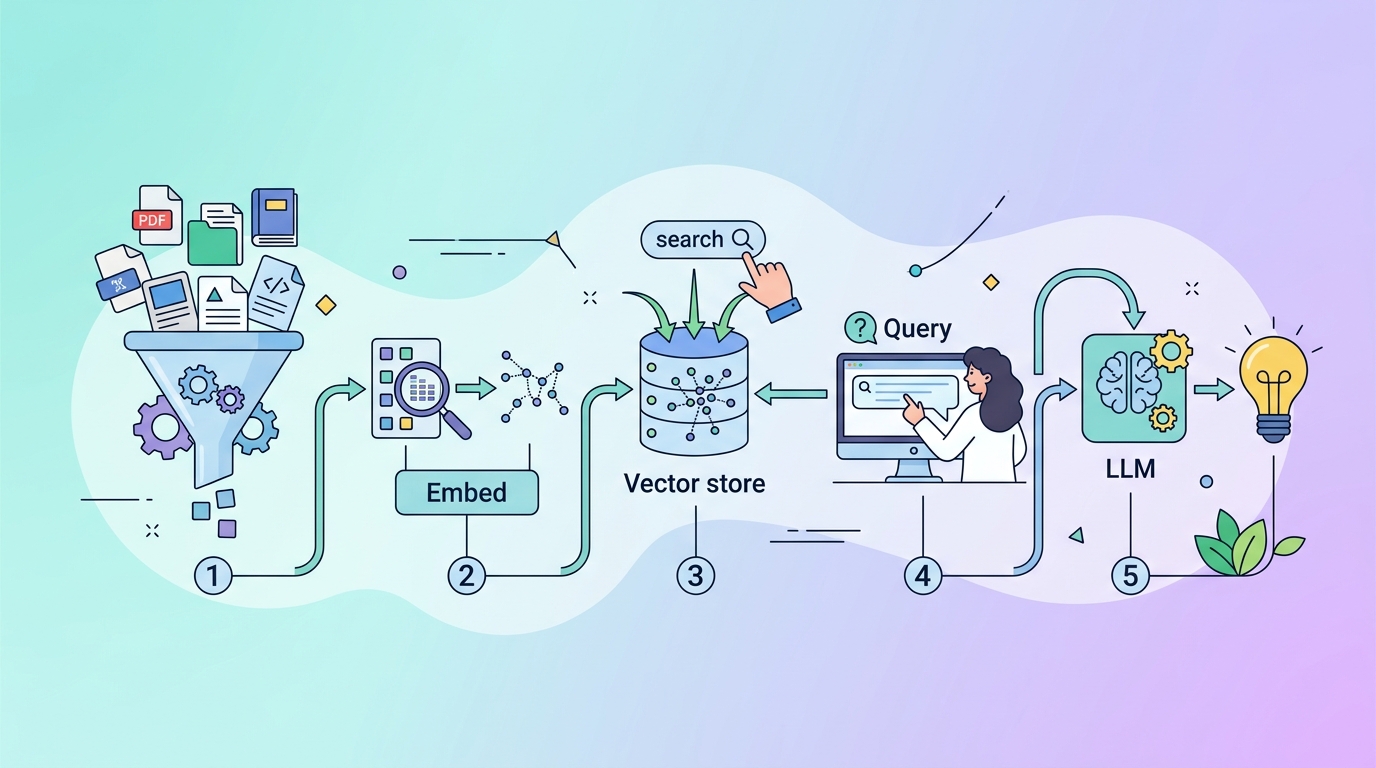
5 步完成 RAG 管線
這篇教你用 5 個步驟做出 RAG 管線,讓模型先檢索你的文件,再根據內容產生有依據的答案。

這篇教你用 5 個步驟做出 RAG 管線,讓模型先檢索你的文件,再根據內容產生有依據的答案。
這篇給想把 LLM 接到自家文件的開發者看。照著做完,你會得到一條可運作的 RAG 流程,能匯入文件、切分段落、產生 embeddings、查回相關內容,最後生成有來源依據的回答。
你也會有一套逐步驗收的方法,方便在上線前檢查檢索品質、延遲與資料新鮮度。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- Node 20+ 或 Python 3.11+
- OpenAI API key,或其他聊天模型 API key
- Embedding 模型帳號,或本地 embedding runtime
- 向量資料庫,例如 Pinecone、Weaviate、Chroma 或 pgvector
- 文件來源,例如 PDF、Markdown、網頁或資料庫
- 可讀取 [OpenAI docs](https://platform.openai.com/docs) 與 [LangChain GitHub repo](https://github.com/langchain-ai/langchain) 的權限,若你要沿用本文示例 stack
Step 1: 準備文件語料
目的:建立一份可被檢索的可信資料來源。
先把你要讓模型信任的內容收集起來。客服機器人可用產品文件與 FAQ;法務或醫療工具則只應使用已核准的內部資料。把內容轉成純文字、去重,並把長文件切成較小區塊,讓檢索器能回傳精準段落,而不是整頁內容。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=120,
)
chunks = text_splitter.split_text(long_document_text)
print(len(chunks))你應該看到 chunk 數量大於 1,而且每個 chunk 都像完整段落。如果 chunk 太大,檢索會變吵;如果太小,回答可能失去上下文。
Step 2: 產生每段 embeddings
目的:把文字轉成能表達語意的向量,而不是只看關鍵字。
把每個 chunk 送進 embedding 模型,讓語意相近的段落在向量空間中靠近。這是檢索品質的基礎。索引與查詢時請使用同一個 embedding 模型,否則相似度搜尋會變得不可靠。
同時保存向量、原始 chunk 文字,以及 title、URL、section、timestamp 等 metadata。這些資訊能幫你追溯答案來源,也能依文件類型或新鮮度過濾結果。
你應該看到每個 chunk 對應一個固定長度向量,通常是數字陣列或 float array。如果這一步失敗,先檢查文字是否為空,再確認模型維度是否符合向量資料庫需求。
Step 3: 建立向量索引
目的:讓知識庫可以用相似度快速搜尋。
把 chunk embeddings 匯入向量資料庫,建立適合最近鄰搜尋的 index。這樣系統就能在毫秒內拿使用者問題對照已存內容,而不是掃描所有文件。若你的應用服務多個團隊,可加上 source、language、tenant 等篩選條件。
實作流程是先把每個 chunk 的 vector、text 與 metadata 一起 upsert,接著確認 index 已可供查詢。若你用 pgvector,先建立 vector 欄位與 similarity index;若你用代管服務,先確認 namespace 或 collection 名稱正確再匯入。
你應該看到索引中的 record 數量與已準備的 chunks 一致。做一個快速查詢後,回傳內容應該是最相關的段落,而不是隨機文字。
Step 4: 取回相關上下文
目的:在 LLM 寫答案前,先抓到最有支撐力的段落。
當使用者提問時,先用同一個模型把問題轉成 embedding,再對向量索引做 similarity search。回傳 top-k chunks,通常是 3 到 8 段;若你更重視精準度,也可以再用 cross-encoder 或 LLM scorer 重新排序。
要持續觀察檢索品質。如果第一名結果只算勉強相關,請改善 chunk 切法、加上 metadata filters,或補強文件語料。RAG 的品質關鍵在檢索,因為生成器只能依據拿到的內容回答。
你應該看到一小串明顯符合使用者意圖的段落。如果段落離題,就算生成步驟很強,答案也很可能偏弱。
Step 5: 組合提示詞並生成答案
目的:輸出有依據、可追溯的回答。
建立一個 prompt,把使用者問題、檢索到的 chunks,以及明確規則一起放進去,例如盡量只根據提供的 context 作答。接著把這個 prompt 送給 LLM,並要求它在資訊不足時直接說明,而不是自行補造事實。這能降低 hallucination,也讓系統更容易被信任。
prompt = f"""
Use only the context below to answer the question.
If the context is insufficient, say so.
Context:
{retrieved_context}
Question:
{user_question}
"""
response = llm.invoke(prompt)
print(response.content)你應該看到答案有反映檢索到的內容,最好還能提到來源或關鍵事實。請用一個明確有收錄在語料中的問題,和一個沒有收錄的問題測試;前者應該正確,後者應該禮貌地表示上下文不足。
常見錯誤
- 查詢與文件使用了不同的 embedding 模型。修法:索引與檢索固定同一模型,若更換模型就重新嵌入整份語料。
- chunk 切太大或太小。修法:先從 500 到 1,000 字元加上 overlap 開始,再依檢索結果調整。
- 略過資料更新。修法:加排程重建索引,或做增量更新,讓新文件與修訂內容能進入 vector store。
接下來可以看什麼
當基本管線跑通後,可以再加 citations、reranking、cache layer,以及針對答案忠實度與檢索召回率的評估測試。下一步也能把同一套模式延伸到 chat memory、tool use,或支援客服、搜尋與內部知識庫的專屬助理。