OpenClaw 記憶體檢索怎麼跑
OpenClaw 的記憶體系統靠檔案監看、非同步去抖更新索引,還能依 API key 決定是否啟用搜尋。這種做法很務實,也方便除錯。

OpenClaw 的記憶體設計,第一眼看起來很樸素。沒有 API key,就直接關掉搜尋。記憶檔一改動,檔案監看器就觸發索引更新。更新還是非同步,而且有 debounce,避免代理卡住。
講白了,這種做法很像工程師會喜歡的風格。它不裝神秘,也不把記憶體包成黑盒子。你知道資料怎麼進來,也知道它怎麼被索引。這對代理工具很重要,因為記憶體一旦太花俏,除錯就會很痛。
OpenClaw 不是在賣「很聰明」的記憶體。它賣的是可預測的檢索流程。這套流程可以搭配本地模型,也能接 OpenAI、Gemini API、Voyage AI、Mistral。重點不是模型多炫,而是搜尋行為夠不夠穩。
OpenClaw 的記憶體層在做什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這套記憶體系統的核心,其實就三件事。第一,記憶資料放在檔案裡。第二,檔案變了就更新索引。第三,搜尋要看設定,有 API key 才開。這種架構很直白,沒有多餘的戲。

我覺得這裡最實際的地方,是它不會假裝功能還在運作。很多工具在 key 不見時,會回你一堆半殘結果,然後說自己有 fallback。OpenClaw 直接把 memory search 關掉。雖然有點硬,但至少誠實。
非同步加 debounce 也很合理。想像一下,代理正在跑任務,記憶檔卻連續被改三次。若每次都重建索引,伺服器和 CPU 都會很躁。OpenClaw 的做法是先等一下,把變更合併,再一次更新索引。
- 沒有 API key 時,memory search 直接停用
- 檔案變動時,watcher 觸發索引更新
- 索引更新走非同步流程
- debounce 可避免重複重建索引
- 代理執行時,不會被記憶體刷新卡住
這種設計很像在說一句話:記憶體要有,但不要搶戲。對開發工具來說,這句話其實很重要。
為什麼這種設計很適合代理工作流
代理工具最怕兩件事。第一是忘記上下文。第二是把過期資料塞回 prompt。前者會讓工具像金魚,後者會讓工具像亂抄筆記。OpenClaw 把記憶體綁在檔案與索引上,就是在避免這兩種問題。
這種模式也很容易理解。檔案就是檔案。索引就是索引。搜尋開不開,看設定就知道。除錯時,你不用猜某個 hidden state 到底做了什麼。這比那種自動幫你塞 context 的黑盒子舒服很多。
而且很多團隊本來就用 Markdown、純文字、任務清單來存知識。OpenClaw 這種 watcher-based 的路線,剛好可以把既有工作方式接進來。你不用重學一套資料格式,也不用每次手動重建記憶。
“The best code is no code at all.” — Jeff Atwood
這句話出自 Jeff Atwood。放在記憶體系統上也很貼切。若索引能自己更新,使用者就少掉很多手動同步。少一步操作,就少一個出錯點。
說真的,代理工具的體驗常常不是輸在模型,而是輸在流程。模型再強,記憶體亂掉,整個系統還是會讓人翻白眼。OpenClaw 至少在這件事上,思路是對的。
和其他記憶體方案比起來,差在哪
很多框架喜歡把記憶體做得很大包。向量資料庫、長期摘要、自動注入 prompt,全部一起上。這樣看起來很猛,但維護起來通常很累。你很難快速回答:到底是哪一步把資料弄壞了?
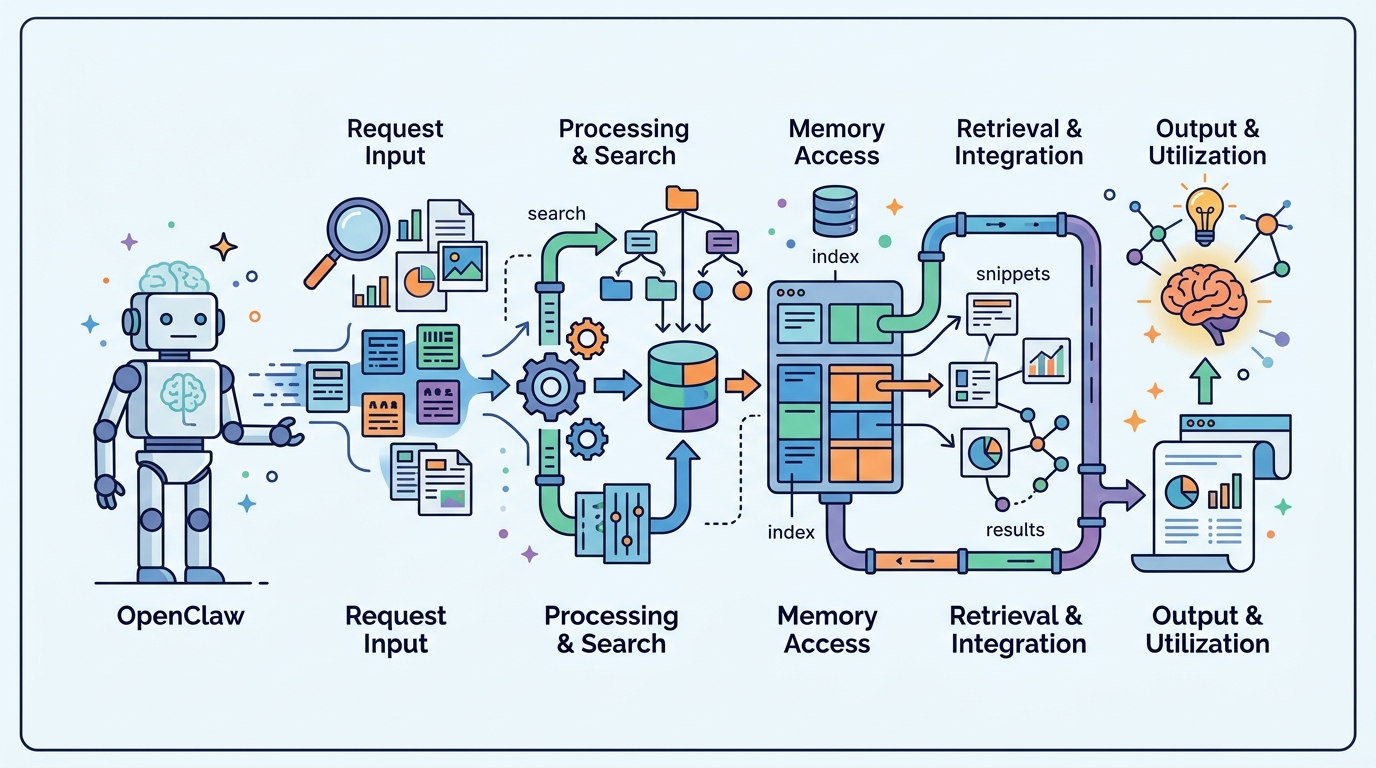
OpenClaw 的路線比較克制。它看起來是把記憶體當成可索引的資料層,而不是一個會自己長出很多行為的神秘模組。這代表它的可觀測性比較高,也比較容易除錯。
另一個差異是模型後端的彈性。OpenClaw 可以搭本地模型,也能接多家 API。這對台灣開發者很實際,因為大家在意的不只是品質,還有延遲、費用、以及資料要放哪裡。
- OpenAI:工具鏈完整,適合快速整合
- Gemini API:和 Google 生態整合方便
- Voyage AI:偏向 embedding 與檢索品質
- Mistral:適合想用開放模型的團隊
- OpenClaw:把檔案監看與索引更新綁在一起
如果拿它跟全託管記憶體服務比,OpenClaw 的優勢是透明。你看得到流程,也比較知道成本在哪。若拿它跟純手動筆記比,它又省掉很多同步工作。這個中間路線,通常最容易被工程團隊接受。
這套做法放在產業裡,代表什麼
代理工具正在往有狀態的方向走。以前大家只問模型會不會回答。現在大家開始問,它會不會記得專案規則、會不會認得 repo、會不會在第三次對話後還記得你剛剛改了什麼。
這時候,記憶體就不能只是「看起來很 AI」。它要能更新,要能追蹤變更,也要能在失敗時明確停用。OpenClaw 的設計,就是把這些條件拆開處理。它不是把所有事情塞進一個超大抽象層。
從產業角度看,這種做法會越來越常見。因為團隊真的不想再碰那種「自動化很多,但沒人知道它做了什麼」的系統。能解釋、能觀察、能重現,這三個條件,比華麗功能更值錢。
另外,記憶體系統的品質,常常跟 embedding 或檢索層有關。這也是為什麼 OpenClaw 同時支援不同模型後端很重要。你可以依照成本、速度、或部署限制去換,不必整套重寫。
我自己的看法很簡單。代理工具要活得久,記憶體就不能太玄。越玄的東西,越難維護。越難維護,最後越容易被團隊關掉。
下一步該看什麼
OpenClaw 這套記憶體系統最值得看的,不是它有沒有「智慧」,而是它能不能穩。索引更新會不會漏掉變更?檔案變大後速度會不會掉?搜尋結果會不會隨資料量增加而飄掉?這些才是真問題。
如果後面能看到檢索準確率、更新延遲、以及大型記憶檔的實測數據,那就更有說服力。沒有這些數字前,我會先把它看成一個很務實的工程方案,而不是什麼神奇記憶體引擎。
講白了,OpenClaw 給了一個不難懂的答案:把記憶體當資料層處理,把搜尋當配置功能處理,把更新放到背景做。這種設計也許不炫,但很耐用。
如果你在做代理工具,我會建議先問自己一句:你的記憶體流程,能不能用一分鐘講完?如果不能,通常就代表它太複雜了。OpenClaw 這種路線,至少提醒了大家一件事,好的記憶體系統,應該先讓人放心,再談聰明。