RAG 是什麼,為何重要
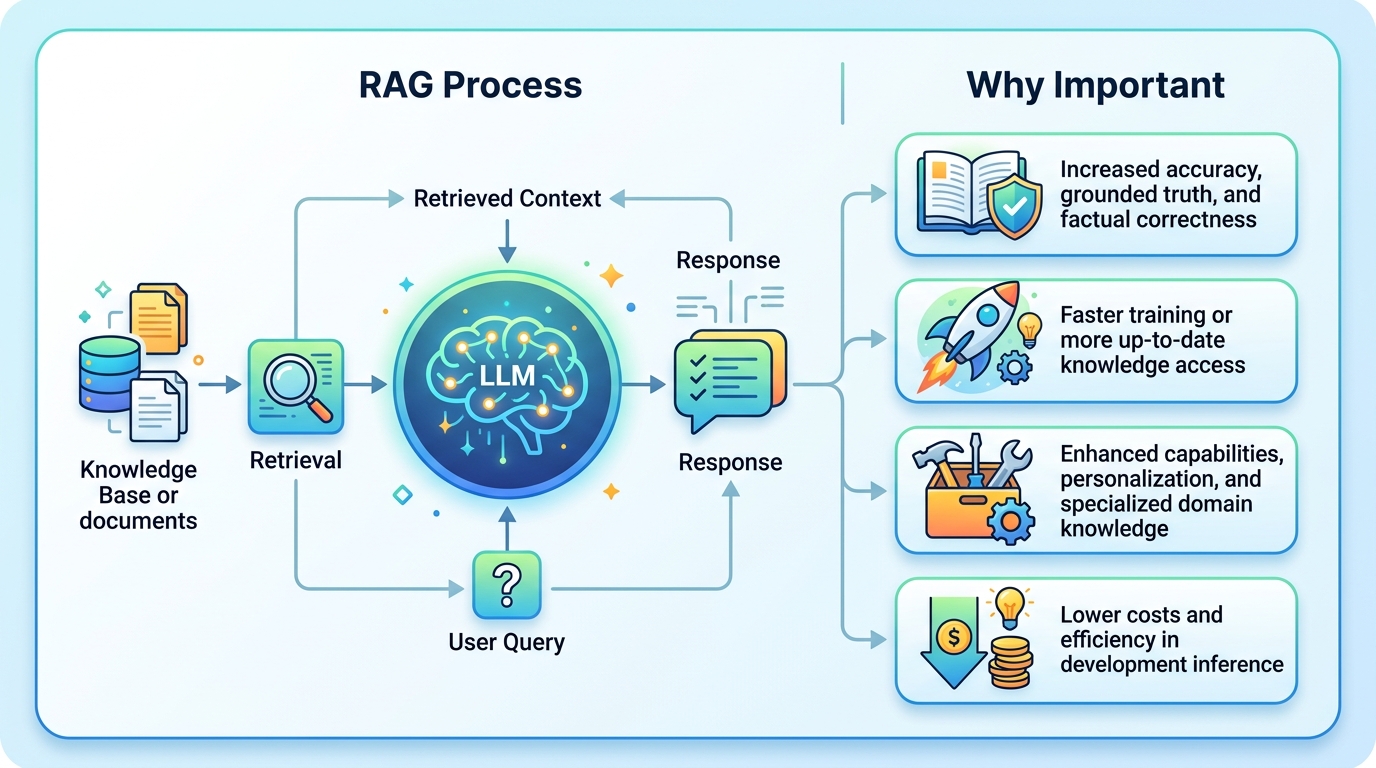
RAG 讓 LLM 先查外部可信資料再回答,能降低幻覺、更新更快,也更適合企業文件與權限控管。

RAG 讓 LLM 先查外部可信資料,再生成答案。
說白了,它是在模型回答前先查資料。這比只靠記憶亂猜,可靠很多。
AWS 把 RAG 定義成 Retrieval-Augmented Generation。它讓 GPT、Claude 這類 LLM,先從外部知識庫找資料,再組答案。這件事很實際。因為模型訓練資料是固定的,但政策、價格、文件、新聞都會變。
你可能會想問,這不就是搜尋嗎?不是。搜尋只找資料。RAG 會把找到的資料塞回 prompt,讓模型根據資料寫答案。講白了,就是先翻文件,再開口。
| RAG 概念 | AWS 的說法 | 為什麼重要 |
|---|---|---|
| 訓練資料 | 靜態,帶有時間限制 | 可能漏掉最新事實 |
| Retrieval | 從外部知識來源抓資料 | 補進新鮮且具體的上下文 |
| Amazon Kendra Retrieve API | 最多 100 段 passages | 給模型更多可用來源 |
| Passage 大小 | 每段最多 200 token words | 讓上下文保持精簡 |
RAG 為什麼會冒出來
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
LLM 很會寫字,這點沒人否認。但它們也很會一本正經地亂講。AWS 提到幾個常見問題:模型會編答案、講得太空、引用不可靠來源,還會把不同文件裡的名詞混在一起。
這在客服、內部知識庫、企業搜尋裡很致命。使用者問的是今年的福利政策,模型卻吐出去年版本。這不是文風問題,這是信任問題。
RAG 的做法很直接。先找資料,再生成答案。模型還是負責寫,但事實來源改成組織自己選的資料庫。這樣至少知道它是根據哪份文件在講。
- 不用為每個內部場景重訓整個 foundation model。
- 可以抓最新文件、API 資料、公告或紀錄。
- 開發者能控制模型能引用什麼。
- 也能先檢查權限,再把資料送進 prompt。
RAG 的實際流程
一個 RAG 系統通常從外部資料開始。可能是文件、API、資料庫,或 GitHub repo。這些資料會先切塊,再轉成 embeddings,存進 vector database。
使用者提問後,query 也會被轉成向量。系統拿它去比對知識庫,挑出最相關的 passages。接著把這些內容放進 prompt,交給 LLM 生成答案。
聽起來簡單,維運才是重點。資料一更新,embeddings 也要更新。你如果放著不管,retrieval 會撈到舊內容。那種錯法很陰險,因為答案看起來還是很順。
“Retrieval-augmented generation is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response.” — Amazon Web Services
RAG 和 semantic search 差在哪
AWS 把兩者分得很清楚。semantic search 是找資料的引擎。RAG 是完整流程。它先找,再寫。
這個差別很重要。搜尋系統解決的是「哪段文字相關」。RAG 解決的是「拿到這段文字後,要怎麼寫成答案」。在企業環境裡,前者常常比後者更難。
因為文件很多,而且散在各處。手冊、FAQ、客服紀錄、內部公告,全都可能是來源。這時候 semantic search 會先幫你縮小範圍,減少人工整理成本。
- Keyword search 快,但容易漏掉換句話說的內容。
- Semantic search 找的是語意,不是字面。
- RAG 會把找到的內容變成回答。
- 權限控管 可以先過濾文件,再進模型。
AWS 提供哪些 RAG 工具
AWS 這邊主打三個產品:Amazon Bedrock、Amazon Kendra,還有 Amazon SageMaker JumpStart。三者定位不一樣。
Bedrock 偏向 managed foundation models,也提供 knowledge base 來做 RAG。Kendra 偏企業搜尋。SageMaker JumpStart 則比較像給團隊自己拼一套 ML 工作流。
最具體的數字是 Kendra 的 Retrieve API。它最多可回傳 100 段 passages。每段最多 200 token words。這代表 AWS 想讓模型拿到夠多上下文,但又不想把 prompt 塞爆。
如果你在選方案,可以這樣看:
- Amazon Bedrock 適合想快點上線的人。
- Amazon Kendra 適合文件多、權限複雜的企業。
- Amazon SageMaker JumpStart 適合想自己組件的人。
- Retrieval quality 往往比模型大小更重要。
背景脈絡:為什麼大家都在談 RAG
RAG 會紅,不是因為它很潮。是因為它很務實。很多團隊不想每次文件一改,就重訓模型。那太貴,也太慢。
而且 LLM 的問題一直都在。它會 hallucinate,會講得很像真的。對消費者問答也許還能混過去。對企業文件、法務內容、產品規格,就很難混。
所以現在很多公司先做 RAG,再談 fine-tuning。這個順序很合理。先把資料接好,先讓答案有來源,再想要不要改模型本體。
這裡也能看出產業分工。模型供應商負責 LLM。雲端平台負責 retrieval、storage、權限與部署。開發團隊負責資料品質。三邊缺一個,效果都會掉。
接下來該怎麼看 RAG
我覺得,RAG 不是萬靈丹。資料亂、切塊爛、權限沒控好,答案一樣會出包。只是它比直接叫模型瞎答,至少多了一層把關。
如果你在做客服機器人、內部知識庫、或文件型產品,RAG 很值得先試。先問自己一件事:你的使用者是不是需要最新、可追溯、來自你自己資料的答案?
如果答案是 yes,那就別再只靠純生成。先把 retrieval 做好,再來談模型。這條路很務實,也比較少踩雷。