AI异常处置正在变成多Agent协作
XCOPS广州站披露阿里云AIOps方案:异常检测、日志聚类、多Agent根因定位,正把运维流程改成自动化闭环。

5月22日,XCOPS智能运维管理人年会广州站将把“AI驱动的智能异常处置”摆到台前。阿里云计算平台智能运维算法团队负责人张颖莹会分享一条完整链路:从异常发现、问题定界,到根因定位,再到异常处置平台落地。
这不是一场只讲概念的分享。公开信息里已经给出四个很具体的技术点:通用时间序列异常检测、基于下钻和日志聚类的问题定界、多Agent根因定位框架,以及通用异常处置平台构建。对做SRE、AIOps、数据库自治的人来说,这几项拼在一起,基本就是一套面向生产环境的故障自动化路线图。
更值得注意的是,这场分享来自阿里云计算平台智能运维算法团队。阿里云把这类能力放到MaxCompute、Flink、DataWorks、PAI这些大数据和AI产品里,说明它讨论的不是实验室 demo,而是高频、真实、线上化的运维问题。
异常处置为什么变成了AI问题
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
运维里最费时间的,从来不是“发现报警”,而是“搞清楚报警意味着什么”。一个指标抖动,背后可能是流量变化、任务堆积、依赖服务变慢,或者只是数据延迟。人工排查时,工程师会先看指标,再翻日志,再查调用链,最后去确认影响范围。这个过程一旦面对多系统、多租户、多链路,效率就会急剧下降。

阿里云这次给出的思路很直接:先用时间序列异常检测把异常抓出来,再通过下钻分析和日志聚类缩小范围,最后把多个智能体组织起来做根因定位。这里的重点不是“AI替代人”,而是把人最耗时的搜索、归纳、比对工作交给模型,把判断和决策留给工程师。
从公开议题看,这套方法尤其适合大数据和AI平台。因为这类系统的特点很鲜明:任务多、链路长、组件杂,单点故障常常会在多个指标上同时冒头。只靠阈值告警,往往只能告诉你“出事了”,不能告诉你“为什么出事”。
- 异常发现:通用时间序列异常检测,处理指标波动和突发偏移
- 问题定界:通过下钻分析和日志聚类,快速缩小故障范围
- 根因定位:多Agent协作,分工处理线索检索、工具调用和推理归纳
- 平台化落地:把能力接入异常处置平台,形成线上闭环
多Agent根因定位,重点在分工
这次分享里最有看头的,是“多Agent根因定位框架”。很多人一听多Agent,第一反应是让几个模型一起聊天。但真正能落地的多Agent系统,核心不是“多”,而是“分工明确”。
在异常处置场景里,Agent 需要扮演不同角色:有的负责读监控和指标,有的负责查日志,有的负责调用内部工具,有的负责把碎片证据串成一条因果链。这样做的好处很明显,模型不必一次吞下所有上下文,工程上也更容易把权限、审计、工具调用边界管住。
张颖莹的公开介绍也很能说明问题。她是阿里云算法专家,在智能运维领域深耕8年,长期支撑 MaxCompute、Flink、DataWorks、PAI 等产品的智能化运维。她还参与过SREWorks开源大数据运维平台开发,以及中国信通院《智能运维能力成熟度模型》行业标准编写。这种背景意味着她讲的多Agent,不太可能停留在概念层面。
“用产品和服务支撑计算平台 MaxCompute、Flink、Dataworks、PAI 等多个大数据&AI产品的智能化运维。” —— 张颖莹,阿里云计算平台智能运维算法团队负责人
这句话的价值在于,它把智能运维的目标说得很清楚:不是做一个漂亮的模型演示,而是把模型塞进真实产品链路里,持续处理线上问题。对企业来说,这才是AI运维的门槛。
和传统AIOps相比,差别在闭环速度
传统AIOps常见做法是告警降噪、异常检测、事件关联。它们能解决“告警太多”的问题,但到了根因定位,往往还需要人来接管。多Agent方案的变化在于,它试图把“从告警到解释”这段路缩短。
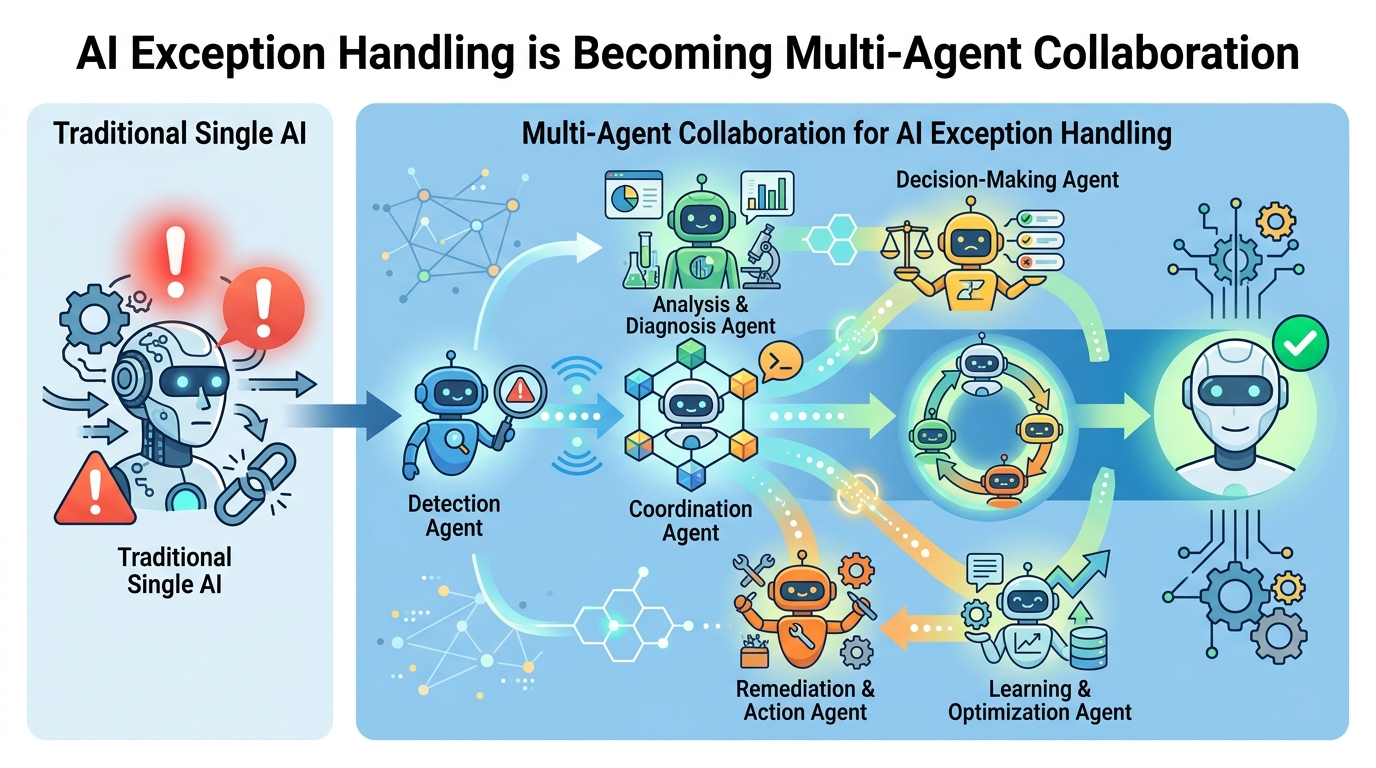
如果把这次XCOPS广州站披露的方案和典型传统流程放在一起看,差异会更直观:
- 传统流程:指标报警后人工排查,常见耗时是几十分钟到数小时
- AI流程:先做异常检测,再自动下钻和日志聚类,把排查范围压到少数候选项
- 多Agent流程:多个角色并行工作,减少单线程排查带来的等待时间
- 平台化流程:把经验沉淀为可复用工具箱,后续同类问题可以更快处理
阿里云团队提到的另一个关键词是“工具箱建设”。这点非常现实。大模型再强,如果拿不到监控、日志、配置、变更记录这些一手数据,推理质量就会打折。工具箱越完整,Agent 越像一个能干活的运维同事,而不是只会给建议的聊天窗口。
从行业趋势看,这种变化也和大模型应用部署框架有关。企业现在最缺的不是一个会说话的模型,而是能接入权限系统、观测系统、工单系统的应用框架。谁能把模型接进生产链路,谁就能把“发现问题”推进到“解决问题”。
广州站透露了一个更现实的方向
这场分享放在XCOPS广州站,背后传递的信息很明确:AI运维已经从“要不要做”进入“怎么做才稳定”的阶段。大会信息里还提到,现场会覆盖“垂类Agent应用与人机协作模态”“数据库自治与底层技术演进”“金融核心改造与安全效能双升级”等主题,这说明行业关注点已经从单点模型能力,转向系统级交付能力。
再看张颖莹的履历,细节也很有说服力。她带领团队拿过ICASSP国际智能运维算法大赛冠军,相关研究成果被 ICLR、KDD、VLDB、SIGMOD、ICDE、WWW、CIKM、ICASSP 等国际会议接收。对一个运维方向的团队来说,这种科研和工程双线推进的背景并不常见。
如果把这次公开信息提炼成一句话,那就是:异常检测已经不够用了,企业现在需要的是“发现异常后,系统能自己找线索、自己缩小范围、自己给出根因候选”。这会直接影响运维团队的组织方式,也会影响未来监控产品的设计方式。
对正在做AIOps或数据库自治的团队,我的判断很直接:接下来一年里,最值得投入的不是再堆更多告警规则,而是把日志、指标、变更、拓扑和工单打通,先做出一条可验证的异常处置闭环。谁先把这个闭环跑通,谁就能先把夜班里最耗人的那部分工作交出去。
问题已经变了。现在不再是“模型能不能识别异常”,而是“模型能不能在5分钟内把异常说清楚”。这会是很多运维平台下一轮升级的分水岭。
// Related Articles
- [IND]
Circle’s Agent Stack targets machine-speed payments
- [IND]
IREN signs Nvidia AI infrastructure pact
- [IND]
Circle launches Agent Stack for AI payments
- [IND]
Why Nebius’s AI Pivot Is More Real Than Hype
- [IND]
Nvidia backs Corning factories with billions
- [IND]
Why Anthropic and the Gates Foundation should fund AI public goods