Midjourney公测背后的视觉生成史
Midjourney在Discord公测后走红。它的审美偏好算法和社交式交互,改写了图像生成的传播方式。

7月,Midjourney进入公测,创始人 David Holz 没有把产品做成传统 App,而是把入口放进了 Discord。这个选择很聪明:用户不是一个人对着空白画布,而是在一个公开频道里看着别人不断生成、修改、再生成,像在围观一场实时创作秀。
这种“广场式”体验迅速放大了传播效率,也让 Midjourney 的审美标签变得非常鲜明。它的图像不追求机械式还原,更像是把“好看”写进了默认参数里,尤其是 V-series 之后,那种偏 CG、偏海报、偏概念设计的质感,几乎成了它的招牌。
如果把这件事放回技术史里看,Midjourney 只是最新一轮爆发。视觉生成已经走了七十多年,从早期的规则绘图,到神经网络,再到今天的大模型扩散生成,今天我们看到的“点几下就出图”,其实是几代研究和产品路线叠加后的结果。
Midjourney为什么先赢在Discord
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Midjourney 早期没有把精力放在独立客户端上,而是直接押注 Discord。这个决定降低了使用门槛,也把生成过程变成了社交内容本身。用户发一句提示词,几秒后就能得到四张图,再继续放大、重绘、变体,整个过程天然适合围观和转发。

对生成式产品来说,分发方式往往和模型能力一样重要。Midjourney 的做法把“使用”变成了“展示”,把“结果”变成了“话题”。这也是它比很多同类工具更快出圈的原因之一。
它的审美策略也很明确。Midjourney 不太执着于照片级真实感,而是持续强化一种更容易被普通用户接受的视觉风格:高对比、强光影、细节饱满、构图完整。对设计师来说,这意味着它更像一个灵感机器;对普通用户来说,它更像一个“自动出片”的工具。
- 入口在 Discord,降低了安装和学习成本
- 默认生成结果更偏艺术化,而非纯写实
- 公开频道让每次生成都带有社交传播属性
- V-series 强化了统一审美,形成明显品牌辨识度
从规则绘图到扩散模型
视觉生成不是最近几年才出现的想法。早在 20 世纪中期,研究者就已经在尝试用程序生成图形,只是那时的方法更接近“手工写规则”。计算机能画线、画几何图案、做简单变形,但离今天这种“理解提示词并生成完整图像”还很远。
真正把这条路线推向实用的是深度学习。2014 年,Ian Goodfellow 提出了 GAN,生成图像第一次有了更强的逼真感。随后,扩散模型开始接管高质量生成任务,OpenAI 的 DALL·E 2、Stability AI 的 Stable Diffusion,把“文字到图像”的能力真正带到了大众手里。
Midjourney 的差异不在于它发明了生成图像这件事,而在于它把模型输出包装成了一种稳定的审美体验。很多模型能生成“正确”的图,但 Midjourney 更擅长生成“愿意发出去”的图。
“The future of AI is not about replacing humans, it’s about amplifying human creativity.” — David Holz
这句话常被拿来解释 Midjourney 的产品哲学。它并没有把自己定义成一个替代设计师的工具,而是把重点放在创意放大上。这个方向也解释了为什么它会优先优化风格、构图和整体观感,而不是一味追求像素级还原。
四个关键节点看视觉生成的演进
如果把视觉生成史压缩成几个节点,会更容易看清 Midjourney 为什么会在这个时间点爆发。每一代技术都在解决前一代的短板,而用户能感知到的,往往是结果而不是算法细节。
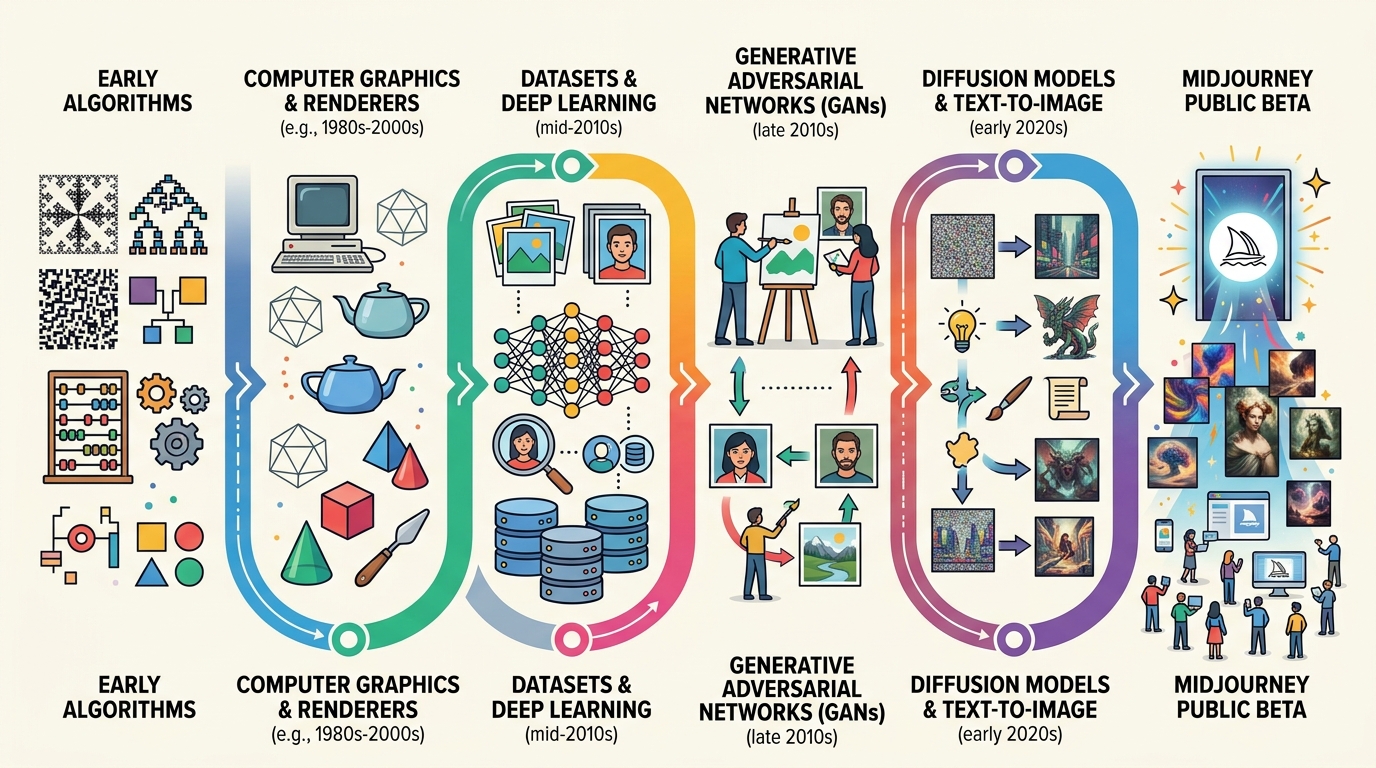
先看几个具体数字。GAN 论文发表于 2014 年;DALL·E 2 在 2022 年把文字生成图像带到更高分辨率;Stable Diffusion 同年开源后迅速扩散到本地部署和第三方应用;Midjourney 通过 Discord 先做社区,再做产品。
- 2014:GAN 让生成图像第一次具备较强真实感
- 2022:DALL·E 2 把文本到图像的质量推到新高度
- 2022:Stable Diffusion 开源后迅速进入开发者和创作者工作流
- Midjourney:用 Discord 社区把生成过程变成传播内容
这条链条说明一件事:视觉生成的竞争早已不只是“谁的模型更强”,而是“谁能把模型变成用户每天都会打开的产品”。Midjourney 在这一点上做得很早,也做得很准。
OpenAI为何关停Sora的讨论
标题里提到“OpenAI 为何关停 Sora”,但更准确地说,Sora 讨论的是视频生成的边界,而不是单纯的产品成败。OpenAI 公开展示 Sora 时,重点放在长时序一致性、复杂场景和镜头运动上。它让外界第一次清楚看到,视频生成已经从“短片段演示”走向“可叙事的镜头语言”。
但视频比图片难得多。图片只需要在一个瞬间成立,视频则要在时间轴上保持人物、物体、光线和运动逻辑一致。生成一张漂亮的图像已经不容易,生成十几秒还不崩的画面,更像是在和物理规律、记忆一致性、镜头调度同时较劲。
这也是 Midjourney 和 Sora 的分野。Midjourney 把注意力放在静态图像的审美稳定性上,Sora 则把问题推进到动态世界建模。一个解决“好看”,另一个解决“会动且说得通”。
从产品角度看,这两条路线都说明生成式 AI 已经过了单纯拼参数的阶段。接下来比的,是谁能把能力做成稳定的工作流,谁能让创作者愿意把日常任务交给它。
接下来谁会更吃香
接下来真正有竞争力的产品,未必是“最像”的那个,而是“最适合某种创作场景”的那个。Midjourney 已经证明,审美一致性和社区传播能让一个模型迅速破圈;Sora 则提醒大家,视频生成的门槛高得多,谁先解决长时序一致性,谁就更接近生产级应用。
对开发者和产品经理来说,这里有个很现实的判断标准:模型能力只是起点,入口设计、反馈速度、审美策略、版权边界、工作流整合,都会直接影响最终结果。单纯把 API 暴露出来,已经不够了。
如果你想判断下一波视觉生成产品谁会跑出来,可以盯住这些指标:
- 生成结果的稳定性,而不是单次演示的惊艳程度
- 社区传播效率,尤其是是否天然适合分享
- 是否能嵌进设计、广告、短视频和电商的日常流程
- 对风格控制和版权风险的处理方式
Midjourney 的故事说明,生成式 AI 的胜负手经常不在模型参数表里,而在用户第一眼看到的那张图里。下一阶段,谁能把“好看、可控、可复用”同时做好,谁就更可能拿到真正的生产力入口。问题已经不是图能不能生成,而是谁会把生成结果变成自己的工作标准。
// Related Articles
- [IND]
Circle’s Agent Stack targets machine-speed payments
- [IND]
IREN signs Nvidia AI infrastructure pact
- [IND]
Circle launches Agent Stack for AI payments
- [IND]
Why Nebius’s AI Pivot Is More Real Than Hype
- [IND]
Nvidia backs Corning factories with billions
- [IND]
Why Anthropic and the Gates Foundation should fund AI public goods