為什麼 Databricks Model Serving 是生產推論的正確預設
Databricks Model Serving 應該成為生產推論的預設選項,因為它把部署、治理與擴展整合在同一個平台,降低多模型團隊的營運成本。
Databricks Model Serving 應該是生產推論的預設選項,因為它把部署、治理與擴展整合在同一個平台。
我支持把 Databricks Model Serving 當作生產推論的預設選項,因為真正的成本不在第一個 endpoint,而在後續長出來的基礎設施、權限、監控與維運分歧。它同時支援自建 MLflow 模型、foundation model 與外部 LLM,還提供單一 REST API、單一介面、serverless autoscaling 與內建治理。對要把模型真正送進產品的團隊來說,這不是「方便」而已,而是少走一整套平台重建的路。
第一個論點:一個平台勝過拼湊式模型堆疊
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Model Serving 最強的價值是整合。Databricks 讓團隊用同一個 serving layer 管理自建模型、託管 foundation model 和外部模型,等於把三套營運模式收斂成一套。你可以先把 MLflow 模型註冊到 Unity Catalog,再用 REST endpoint 對外提供服務,之後也能把 GPT-4 這類外部模型納入同一套治理面。少的是工具數量,多的是穩定性。
這在從 PoC 走向 production 時最明顯。概念驗證可以接受腳本、臨時 wrapper、單點部署;生產系統不行。當產品、分析、ML 團隊都要共用模型能力時,統一 serving layer 會直接降低整合成本。Databricks 連 AI Functions 和 ai-query 的 batch inference 都能從 SQL 直接做,對已經把資料管線放在 warehouse 的公司來說,這代表資料、模型、應用之間少了一段手工搬運。
第二個論點:治理不是附加功能,而是產品本體
Model Serving 之所以值得當預設,不是因為它只會 host 模型,而是它把治理放到第一層。Serving UI 集中管理權限、用量限制與監控,連外部託管的 endpoint 也能納入同一個控制面。對企業來說,這很重要,因為最常見的失敗不是模型不準,而是權限散落、政策不一致、部門各自接 API。Databricks 透過 AI Gateway 把這些東西收斂到單一 control plane,降低治理碎片化。
安全性也不是口號,而是能落地的操作條件。請求會被隔離、驗證與授權,資料靜態加密採 AES-256,傳輸中加密採 TLS 1.2+;付費帳號的輸入與輸出不會被拿去訓練 Databricks 服務。這些不是加分題,而是企業能不能放行內部模型服務的基本門檻。再加上 serverless egress control 的網路政策,安全團隊才有真正能執行的槓桿,而不是紙上規範。
第三個論點:生產推論要擴展,更要穩定
autoscaling 和低延遲只有在真實負載下穩定才有意義,而這正是 Model Serving 的定位。Databricks 公開說明其服務可支援超過 25K QPS,且 overhead latency 低於 50 ms。不是每個團隊都需要這個數字,但平台設計本身已經朝高可用 production 走,而不是只滿足 demo。serverless compute 也讓流量變化不必再卡在基礎設施排程上。
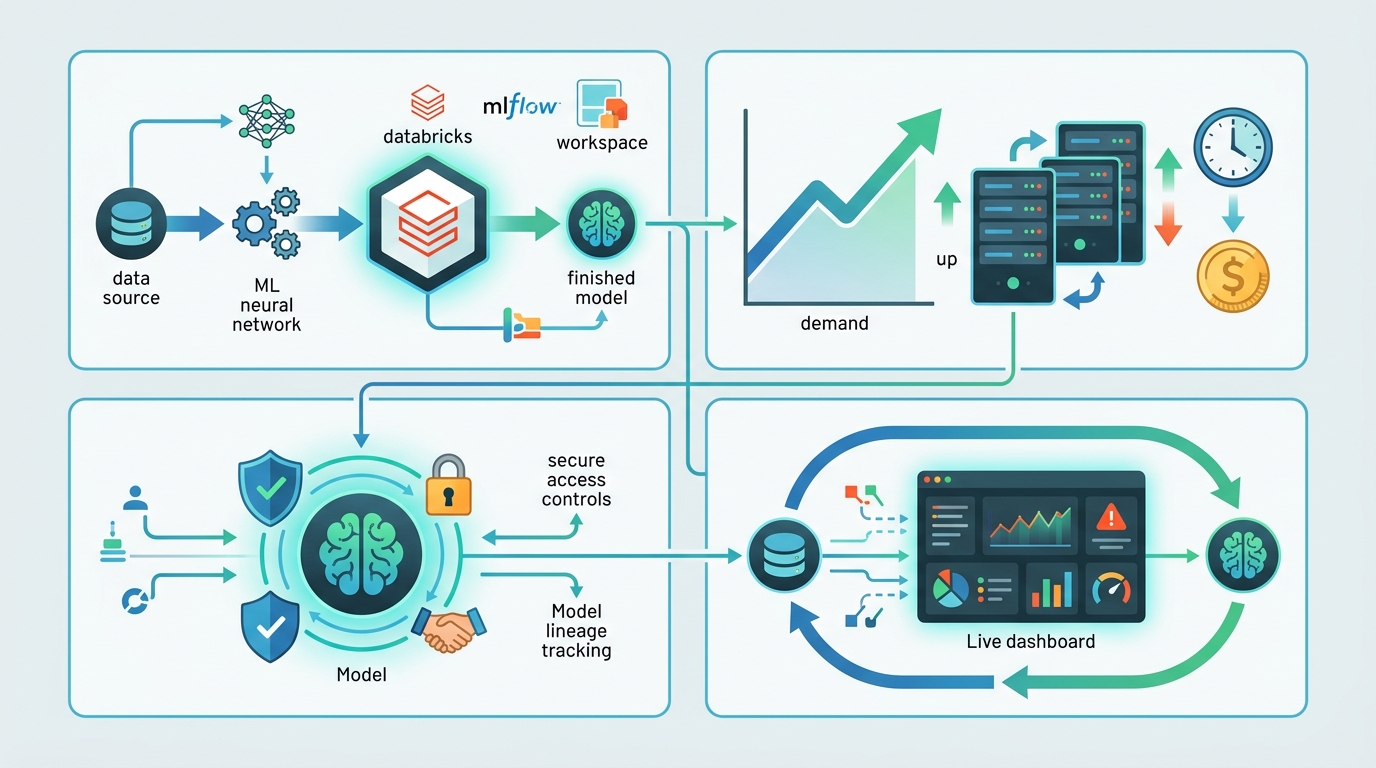
另一個很能看出成熟度的細節,是 Databricks 不會直接在原有 model image 上打補丁。新版本模型會建立帶有最新 patch 的新 image,但舊 image 會保留不動,避免影響線上部署。這個取捨是對的。生產推論不是桌面軟體更新,不能為了「永遠最新」去犧牲線上穩定。對 live endpoint 來說,避免中斷的價值遠高於強迫立即升版。
反方可能怎麼說
最強的反對意見是,Model Serving 把太多東西集中在同一個平台,容易讓團隊依賴單一供應商的抽象層、定價與限制。這個擔心合理。若公司只需要一個簡單 custom model API,較輕量的部署方式確實可能更便宜、更容易理解。另一個風險是,managed serving 可能讓團隊推得太快,卻還沒準備好對應的治理流程,尤其當內部模型和外部 LLM 開始混用時。
也有人會說,managed serving 只是把複雜度藏起來,不是真的消除它。autoscaling、throughput tuning、model versioning、region constraint、endpoint limit 這些問題都還在。如果團隊要的是對 runtime、networking、image lifecycle 的絕對控制,自己維護 serving stack 會更合適。從這個角度看,Databricks 不是所有部署問題的答案,它是處理「多模型、多團隊、強治理」這類問題的強答案。
但這個反方論點沒有推翻它,只是劃出邊界。當問題是組織規模,而不是玩具級簡單部署時,Model Serving 就是正確預設。只要公司需要一個政策面來管多種模型、一個可擴展的 endpoint 模型、以及一個能看見存取與成本的地方,managed approach 就會贏。供應商綁定是真實代價,但把 hosting、auth、scaling、monitoring 拆成多套工具的營運債也同樣真實,而且在 production 裡增長更快。
你能做什麼
如果你是工程師,當團隊需要快速上線、受管存取、以及支援多種模型型態時,把 Model Serving 當成生產推論的基準方案。如果你是 PM,從第一天就把權限、用量限制、成本可視化與版本管理納入 serving 策略,不要等上線後再補。如果你是創辦人,請優先設計你在十個模型、三個團隊下要怎麼營運,而不是只看第一個 demo 的成本。真正的問題不是能不能自己 host 模型,而是你願不願意自己承擔安全地大規模營運它的全部責任。