大型語言模型是什麼,怎麼運作
大型語言模型把海量文字學成可預測 Token 的系統,能寫作、摘要、翻譯,也會胡說八道。
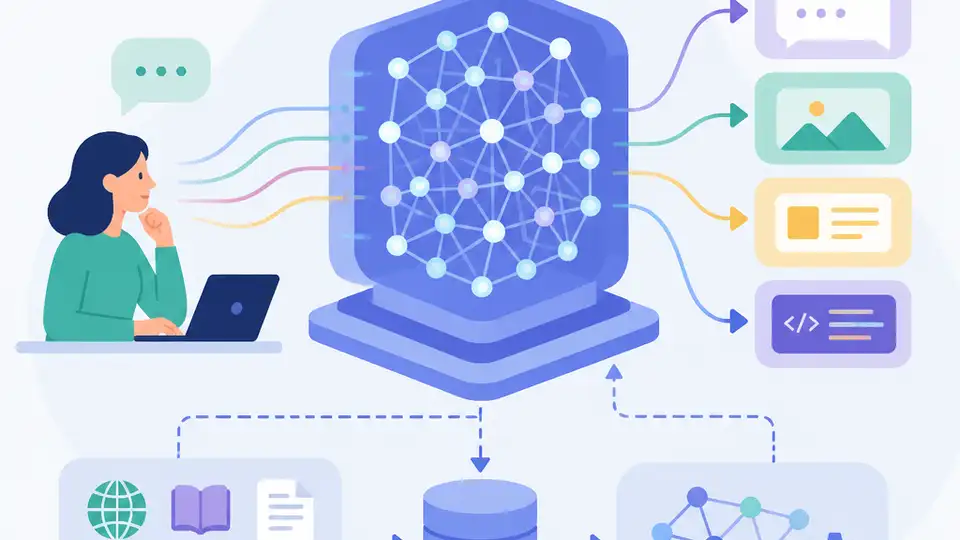
大型語言模型是用海量文字訓練的神經網路,靠預測下一個 Token 來產生、整理和理解語言。
說真的,這東西已經不是玩具了。GPT-4 和 GPT-4o 把一般人對聊天機器人的期待拉高很多。它們不只會聊天,還能摘要文件、翻譯、寫程式,甚至像軟體助理一樣工作。
資料上也很直接。Transformer 架構在 2017 年出現。GPT-3 在 2020 年讓大規模 prompting 變常態。ChatGPT 在 2022 年把 LLM 送進消費市場。這條線很清楚,模型不是只在論文裡跑,而是直接進產品。
| 事件 | 數字 | 意義 |
|---|---|---|
| Transformer 論文 | 2017 | 成為主流 LLM 的核心架構 |
| GPT-3 | 2020 | 讓大模型提示工程變成日常工作 |
| ChatGPT | 2022 | 把 LLM 變成大眾產品 |
| DeepSeek R1 | 6710 億參數 | 讓開源推理模型更受關注 |
從預測文字,變成可用工具
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
講白了,LLM 本質上是神經網路。它先吃進大量文字資料,再學會預測下一個 Token。這個任務看起來很小,但規模拉大後,模型就能寫段落、補句子、改寫內容,還能做翻譯和摘要。

這也是很多人第一次用就會嚇到的原因。你以為它只是 autocomplete,結果它能接住一整段技術說明。當參數、訓練資料、算力都堆上去後,輸出就不再像簡單接龍,而像一個通用文字引擎。
不過,能力高不等於可靠。訓練資料如果有偏誤、過時內容,或錯誤資訊,模型常常會原封不動吐出來。它講得很順,不代表它講得對。這點在客服、法務、醫療、財務場景都很致命。
- 它先學文字,再學指令。
- 它用 Token、embedding、attention 來處理資料。
- 它能生成、摘要、翻譯、分類文字。
- 它也會 hallucinate,尤其碰到訓練外的事實。
為什麼 Transformer 會贏
真正改變局面的,是 Attention Is All You Need。這篇 2017 年的論文提出 Transformer。以前的語言模型多半靠 RNN 或傳統統計方法。前者難平行化,後者上限也低。
Transformer 厲害在兩件事。第一,它很適合平行運算,訓練效率高很多。第二,它能處理長距離關聯。句子前面提到的人名,後面還記得住。程式碼區塊裡前後變數,也比較不容易亂掉。
這就是為什麼 2024 年的大型模型,主流還是 Transformer。雖然研究圈一直在看 state space models 這類替代方案,但主戰場還是 Transformer。原因很現實,訓練穩、效果好、工具鏈成熟。
“Attention Is All You Need”
Vaswani et al., 2017
這句其實很直白。模型不是像人一樣逐字閱讀。它是在算哪些字彼此相關,然後決定下一步要吐什麼。說穿了,就是一個很會抓上下文關係的數學機器。
Prompting 讓模型變得可控
LLM 會爆紅,還有一個原因。它們開始聽得懂指令了。你不用重新訓練模型,只要寫清楚需求,就能讓它改寫、整理、分類,甚至照格式輸出。這讓一般開發者也能玩得動。
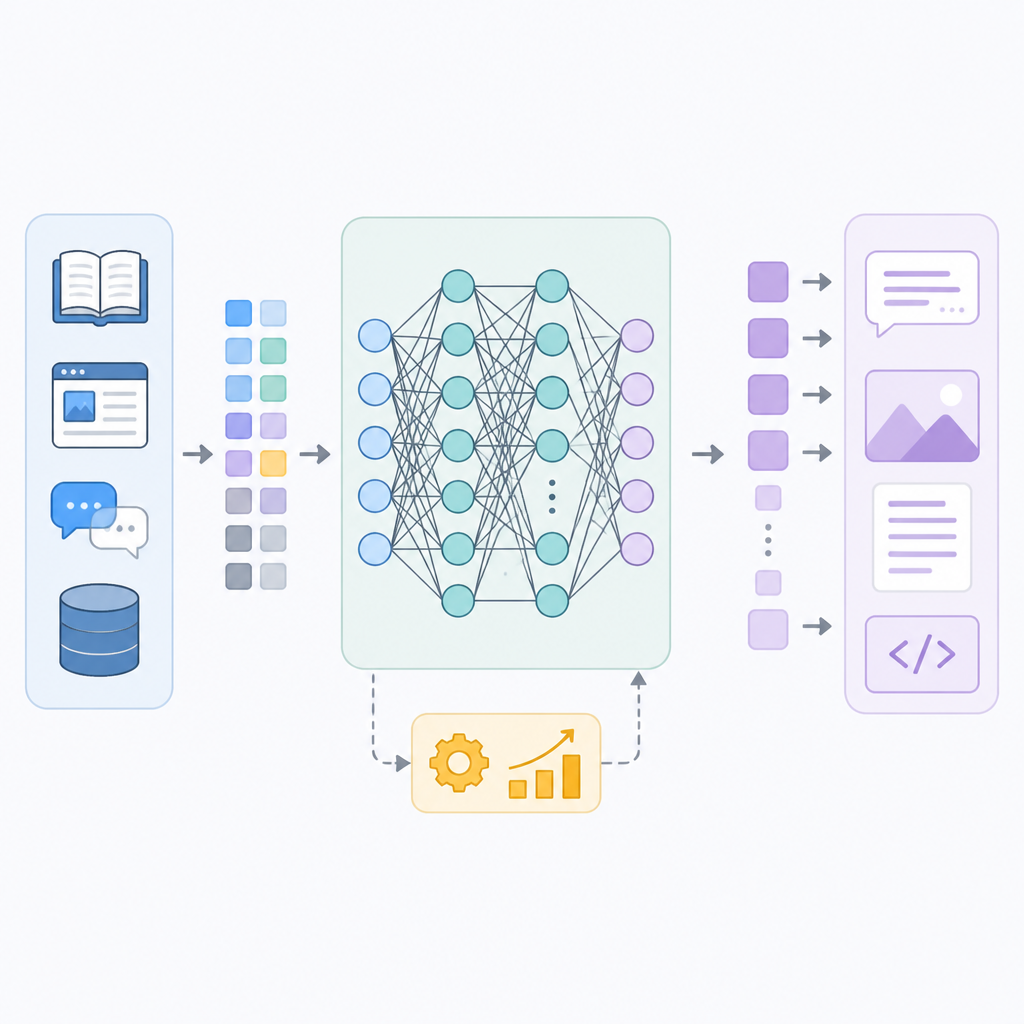
這件事後來變成 prompt engineering。你給它一個草稿,再叫它改成條列。你再叫它縮短成 100 字。你再叫它換成台灣口吻。這種互動很土炮,但很有效。再往下走,就接到 retrieval-augmented generation 和 tool use。
2022 年的 chain-of-thought prompting 又把這件事往前推。它鼓勵模型先拆步驟,再給答案。OpenAI o1 在 2024 年走了類似方向,先做較長的內部推理,再回傳結果。這不代表它變神了,只是它比較慢,也比較會想一步。
- Hugging Face 讓開源模型更容易流通。
- LLaMA 讓開源權重更受關注。
- Mistral AI 把高效率模型做得更有競爭力。
- DeepSeek 在 2025 年推出 R1,參數規模達 6710 億。
對產品團隊來說,這裡的重點很現實。Prompt 不只是技巧。它已經是介面設計的一部分。你怎麼下指令,會直接影響產品體驗。
競品、成本與能力怎麼比
如果你只看聊天效果,很容易失焦。真正該看的是成本、速度、上下文長度、以及是否能接工具。不同模型各有強項。有人強在寫作,有人強在推理,有人強在便宜,有人強在可部署性。
以公開市場來看,OpenAI、Anthropic、Google、Meta、Mistral、DeepSeek 都在搶同一批開發者。差別不是誰聲量最大,而是誰能把 API、價格、延遲、上下文窗做得順。對台灣團隊來說,這比行銷詞重要多了。
你也會發現一個趨勢。模型越大,不一定越適合直接上線。很多產品其實用中型模型就夠,剩下的交給檢索、規則、快取和後處理。這樣成本更穩,也比較不會被 hallucination 拖下水。
- OpenAI 強在通用能力與產品化。
- Anthropic 常被拿來比安全與長文處理。
- Gemini 主打多模態與 Google 生態整合。
- Meta AI 和 Mistral AI 則讓開源與自架部署更有選擇。
還有一個很實際的數字差異。DeepSeek 的 R1 走的是高參數推理路線。OpenAI 的 GPT-4o 則強調即時互動。前者比較像重推理,後者比較像即時助理。產品要選哪個,得看場景,不是看誰名字比較響。
LLM 真的會出錯,而且錯得很像真的
這是最麻煩的地方。LLM 不是資料庫。它不是把答案存好再查出來。它是在生成看起來合理的文字。所以它很會編,也很會補洞。你問它一個它不確定的問題,它可能直接講得像專家。
這種錯法很危險。因為語氣太穩了。使用者不容易看出哪裡有問題。對企業來說,這代表不能只看 demo。你要看錯誤率、拒答率、引用來源、和是否被 prompt injection 影響。
所以現在比較成熟的系統,都不會只靠模型本身。它們會加搜尋、驗證、權限控管、以及 guardrails。模型負責草稿,其他系統負責查核。這才比較像能上線的軟體。
另外,訓練和推理也很吃資源。模型越大,伺服器成本越高。這也是為什麼很多公司開始重視蒸餾、量化、快取,還有更小但更專用的模型。大家嘴上都在談 AI,最後還是回到帳單。
這波變化其實是軟體介面改寫
LLM 最有意思的地方,不是它會聊天。是它讓語言變成可程式化介面。以前你要學 API、欄位、格式。現在你可以直接用自然語言描述需求。這對搜尋、客服、知識庫、寫程式工具,影響都很大。
這也解釋了為什麼很多產品開始加 AI 助理。不是因為大家都愛聊天,而是因為它能縮短操作路徑。你少點幾個按鈕,少找幾層選單,工作就快一點。當然,前提是模型不要亂掰。
我覺得接下來最重要的,不是更會講故事的模型,而是更會收斂風險的系統。誰能把答案驗證、引用來源、權限、成本控制做好,誰就比較有機會把 LLM 變成真正可用的產品層。
如果你現在要做一個 LLM 產品,我的建議很簡單。先選一個夠穩的模型,再把檢索、規則、日誌、人工覆核補齊。不要一開始就想靠模型單挑全世界。那通常只會先燒錢,再補 bug。