為什麼 Pinecone 的編譯式向量工件才是 AI agents 的正解
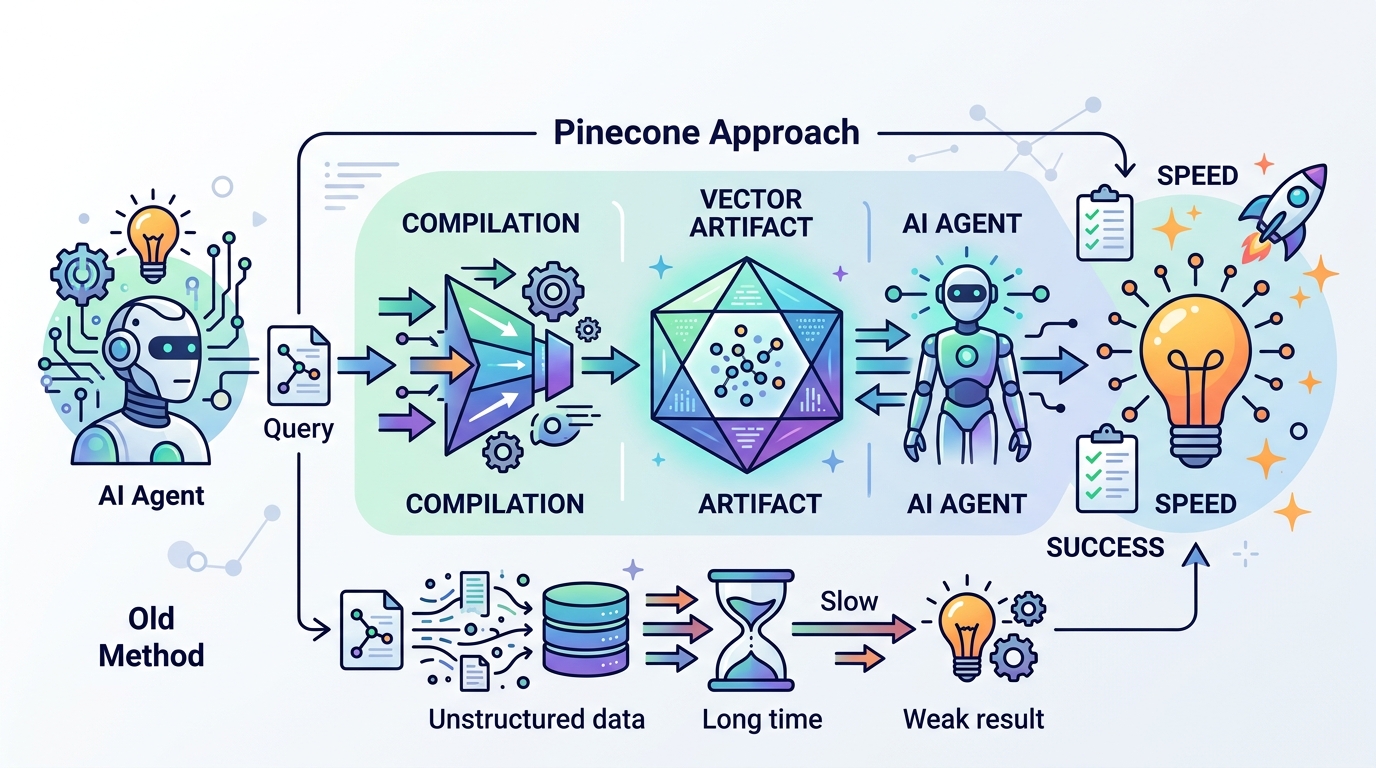
Pinecone 的方向是對的:AI agents 需要先編譯好的知識工件,而不是每次即時翻找原始向量。
Pinecone 的方向是對的:AI agents 需要先編譯好的知識工件,而不是每次即時翻找原始向量。
Pinecone 這次不是在做噱頭,而是在回應一個已經很明顯的生產痛點:原始向量檢索太慢、太貴,也太不穩定。當系統每次呼叫都要重新搜尋上下文,延遲會抖動,token 成本會膨脹,所謂 agentic workflow 很快就退化成昂貴的 brute-force search。把知識先編譯成可重用的工件,才是下一層 AI 基礎設施該走的路。
第一個論點:先編譯,比每次重找便宜得多
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Pinecone 自己給出的數字已經說明問題。它指出,當 agents 直接操作原始向量資料時,任務完成率只落在 50% 到 60%;而編譯後的工件最高可把 token 用量降低 90%。這不是微調,而是架構層級的差異。對一個每天跑上萬次請求的系統來說,這代表的不是省一點錢,而是能不能上線、能不能擴張的差別。
軟體工程早就證明過同一件事:編譯器之所以存在,就是因為「一次做完」比「每次執行都重做」更有效率。Pinecone 的 Context Compiler 把這個邏輯搬到知識檢索上,將任務相關上下文、來源、RBAC、版本與 PII 標記一起封裝。對企業場景而言,這種做法比單純把文件丟進向量庫更合理,因為企業要的不只是快,還要可稽核、可控管、可重現。
第二個論點:agents 需要的是專門化知識,不是通用向量雜燴
Pinecone 反對「一個檢索層服務所有 agent」的想法,這點也站得住腳。銷售 agent 需要的是 Gong 會議紀錄與 Slack 對話,財務 agent 關心的是帳單週期與用量門檻,行銷 agent 看的是活動觸點與 PQL 訊號。這些情境不是同一種資料混一混就能解決的,因為每個團隊的決策框架本來就不同。
真正的 agent 失敗,往往不是資料不存在,而是資料沒有結構。一般向量搜尋最多只能撈回「看起來相關」的文件,卻不能保證這些內容符合當下決策所需的證據標準。Pinecone 的 KnowQL primitives,像 intent、provenance、confidence、budget,提供的是一個更像契約的介面:什麼算相關、可信度要多高、預算用到哪裡為止,都先定義清楚。這比「先搜再說」更適合會代表人類行動的 agents。
反方可能怎麼說
最強的反對意見是,Pinecone 其實是在替一個專有抽象層找市場,而這個問題終究會被更強的 foundation models、更好的 embeddings,或更大的 context window 吃掉。批評者也會說,先編譯工件會讓系統變得僵硬,維護成本上升,資料一旦過期就會變成負擔。這些質疑不是空穴來風,因為如果編譯層沒有持續更新,它確實會失效。
但這個反對意見只能推翻「偷懶的實作」,推不翻 Pinecone 的核心判斷。企業 AI 的瓶頸從來不只是在模型能不能回答,而是在成本、治理與重複執行的穩定性。當同一批知識要被多個 agent 在不同權限、不同任務、不同時點反覆使用時,原始向量搜尋就是太慢、太貴、太不可控。編譯式工件不是權宜之計,而是生產環境裡更符合現實的檢索架構。
你能做什麼
如果你是工程師、PM 或創辦人,別再把 retrieval 當成每次都即時搜尋的單一問題。把「探索」和「執行」拆開,先預編譯 agents 反覆需要的上下文,附上來源、權限與版本資訊,再用延遲、token 花費與任務完成率來衡量成效,而不是只看 recall。只要你的產品面向企業,Pinecone 這條路就是對的:先把知識編譯好,再讓 agents 消費結構化工件,而不是每次都重新付費重建上下文。