Why AI agents should maintain your wiki, not answer your questions
AI agents should maintain a living wiki instead of re-answering the same questions.

AI agents should maintain a living wiki instead of re-answering the same questions.
AI agents are at their best when they maintain a single source of truth, not when they keep re-deriving answers from scratch. That is the core bet behind Ar9av/obsidian-wiki: ingest once, extract concepts, resolve conflicts, and keep the knowledge base current instead of duplicating it across chats, prompts, and ad hoc retrieval. The repo turns Karpathy’s LLM Wiki idea into a practical system for Obsidian, and the design choice is right because it treats knowledge as something to curate, not something to endlessly query.
First argument: duplication is the real cost of AI knowledge work
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most AI workflows waste time by asking the same question in slightly different forms. The repository’s answer is blunt: if a concept page already exists, the agent updates it by merging new information, noting contradictions, and strengthening cross-references. That is a better use of model effort than spinning up a fresh RAG pass or generating another isolated summary that will be forgotten the next day.

The repo’s ingest pipeline makes this concrete. It handles markdown, PDFs, JSONL exports, plain text logs, transcripts, and images, then folds the result into a wiki with sources tracked in frontmatter. That matters because the problem is not lack of model intelligence; it is knowledge drift. Once a system can attribute claims and merge deltas, it stops behaving like a chatbot and starts behaving like an editor.
Second argument: the agent-as-maintainer model scales better than prompt gymnastics
What makes obsidian-wiki compelling is that it is not tied to one model or one interface. It is built as a set of markdown skills that Claude Code, Cursor, Windsurf, Codex, Gemini CLI, Kiro, and others can read. The setup script symlinks the canonical skill files into each agent’s expected location, which means the workflow survives tool changes instead of being trapped inside a vendor-specific plugin.
That portability is not a minor convenience; it is the difference between a durable system and a demo. A team can point different agents at the same vault, let each ingest new material, and keep the schema coherent as the knowledge base grows. The repo even tracks every source in a manifest and computes deltas on the next ingest, so the agent processes only what changed. That is the kind of operational discipline AI tooling usually lacks.
The counter-argument
The strongest objection is that a living wiki creates another maintenance burden. If the agent is merging pages, resolving contradictions, and managing schema, then the system itself becomes a source of complexity. Critics will also say that retrieval systems already solve the “ask the same thing twice” problem without forcing users to curate a markdown knowledge base.
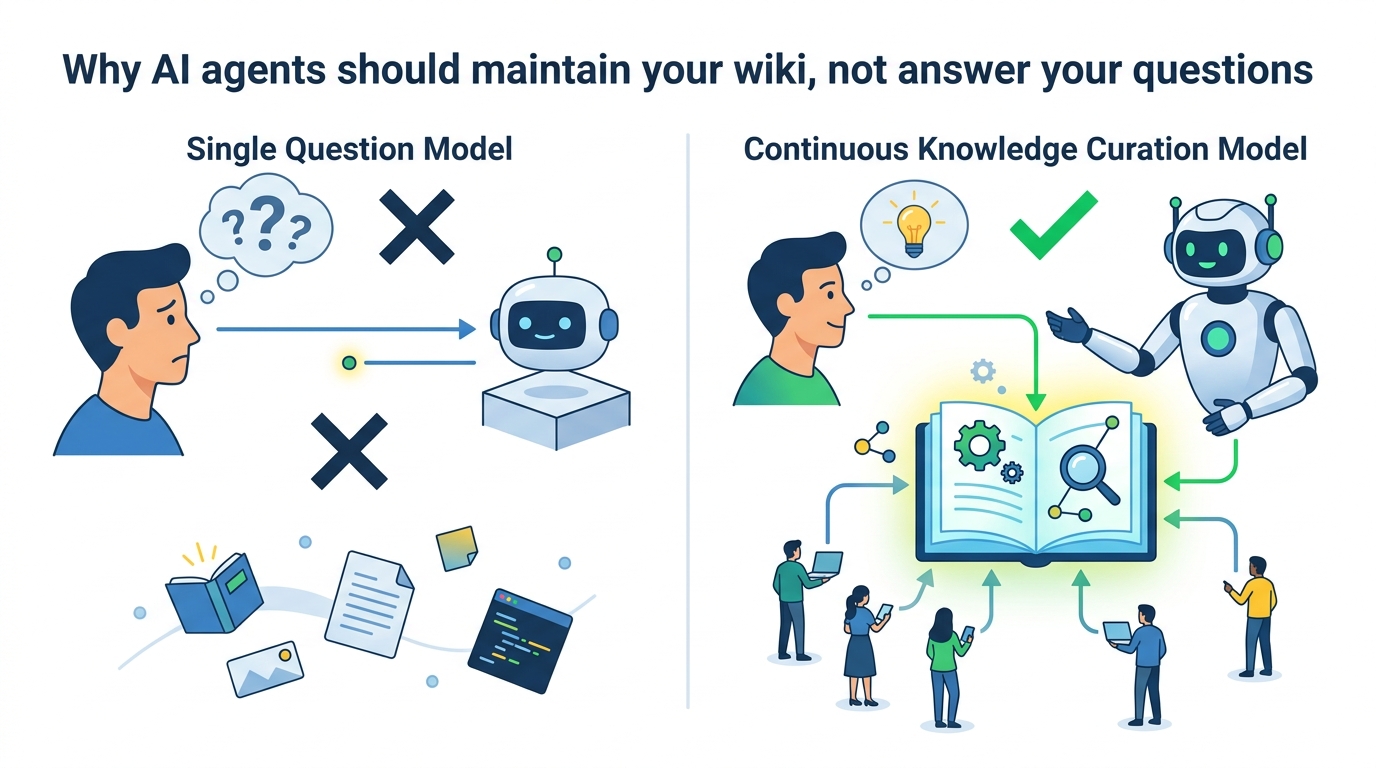
That critique is serious, but it misses the point of the repo’s design. This is not a replacement for search; it is a replacement for repeated synthesis. Retrieval can surface documents, but it does not normalize concepts, preserve cross-links, or reconcile conflicting claims into a stable structure. The maintenance cost is real, yet obsidian-wiki pays it once and turns it into compounding value. In knowledge work, that is the correct trade.
What to do with this
If you are an engineer, stop treating your notes as dead storage and start treating them as an agent-readable system of record. If you are a PM or founder, use this pattern for product decisions, research notes, customer interviews, and architecture choices so the organization stops re-litigating the same facts. The practical move is simple: choose one vault, define the ingest sources, enforce source attribution, and let the agent update pages instead of generating duplicates. The goal is not more AI output. The goal is a knowledge base that gets better every time the model touches it.
// Related Articles
- [AGENT]
Perplexity should build Teammate as a coding agent, not a copilot
- [AGENT]
HP adopts OpenAI Frontier across global operations
- [AGENT]
Build a production vector DB for RAG
- [AGENT]
Ornith-1 turns agent coding into a server
- [AGENT]
Crypto AI agents are useful, but only for narrow workflows
- [AGENT]
AI Agents in Crypto: 2026 Protocol Guide