Why Xiaomi’s MiMo-V2.5-Pro Changes Coding Agents More Than Chatbots
MiMo-V2.5-Pro matters because it is built for long, tool-heavy coding work, not chat.

MiMo-V2.5-Pro is Xiaomi’s open-weight model for long, tool-heavy coding jobs.
Xiaomi’s MiMo-V2.5-Pro is not just another benchmark flex; it is a signal that the next fight in AI is about endurance, not chatter. The model is designed for tasks that run for hours and require thousands of tool calls, and Xiaomi says it built a full compiler in 4.3 hours, reached 100 percent test coverage after 672 tool calls, and landed near Claude Opus 4.6 on coding scores while using 40 to 60 percent fewer tokens than rivals.
First, the market now rewards models that can stay on task
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The compiler example is the clearest proof. A system that starts with 59 percent coverage, refactors itself into a regression, detects the mistake, and recovers to 233 out of 233 hidden tests is doing real engineering work, not autocomplete theater. That matters because code generation is no longer judged by whether a model can write a function; it is judged by whether it can sustain a plan across multiple failure points.

The same pattern shows up in Xiaomi’s second example: a desktop video editor with about 8,000 lines of code, built unsupervised for 11.5 hours with roughly 1,870 tool calls. That is the shape of the new category. The winning model is the one that can hold state, revisit decisions, and keep moving when the task stretches beyond a single prompt window.
Second, token efficiency is becoming a competitive weapon
Xiaomi says MiMo-V2.5-Pro uses 40 to 60 percent fewer tokens than Claude Opus 4.6 and Gemini 3.1 Pro. That is not a cosmetic gain. In long-running agent workflows, token burn is cost, latency, and failure surface all at once. A model that can do the same work with fewer tokens is easier to run repeatedly, easier to scale, and more attractive for product teams that need margins, not just leaderboard glory.
The context window numbers reinforce the point. The main version handles up to one million tokens, while the base model without retraining reaches 256,000. Xiaomi also says a blend of local and global attention cuts memory use by almost seven times, and parallel token prediction triples output speed. Those are the kinds of gains that matter when a model is expected to sit inside an agent loop for hours rather than answer one-off questions.
Third, Xiaomi is betting on open weights as a distribution strategy
MiMo-V2.5-Pro ships as an open-weight model, and Xiaomi released multiple related models at once, including MiMo-V2.5, MiMo-V2.5-TTS, and MiMo-V2.5-ASR. That matters because the company is not trying to win only in hosted chat. It is trying to seed a stack that developers can inspect, adapt, and deploy inside their own workflows, especially where long context, tool use, speech, and multimodal input all meet.
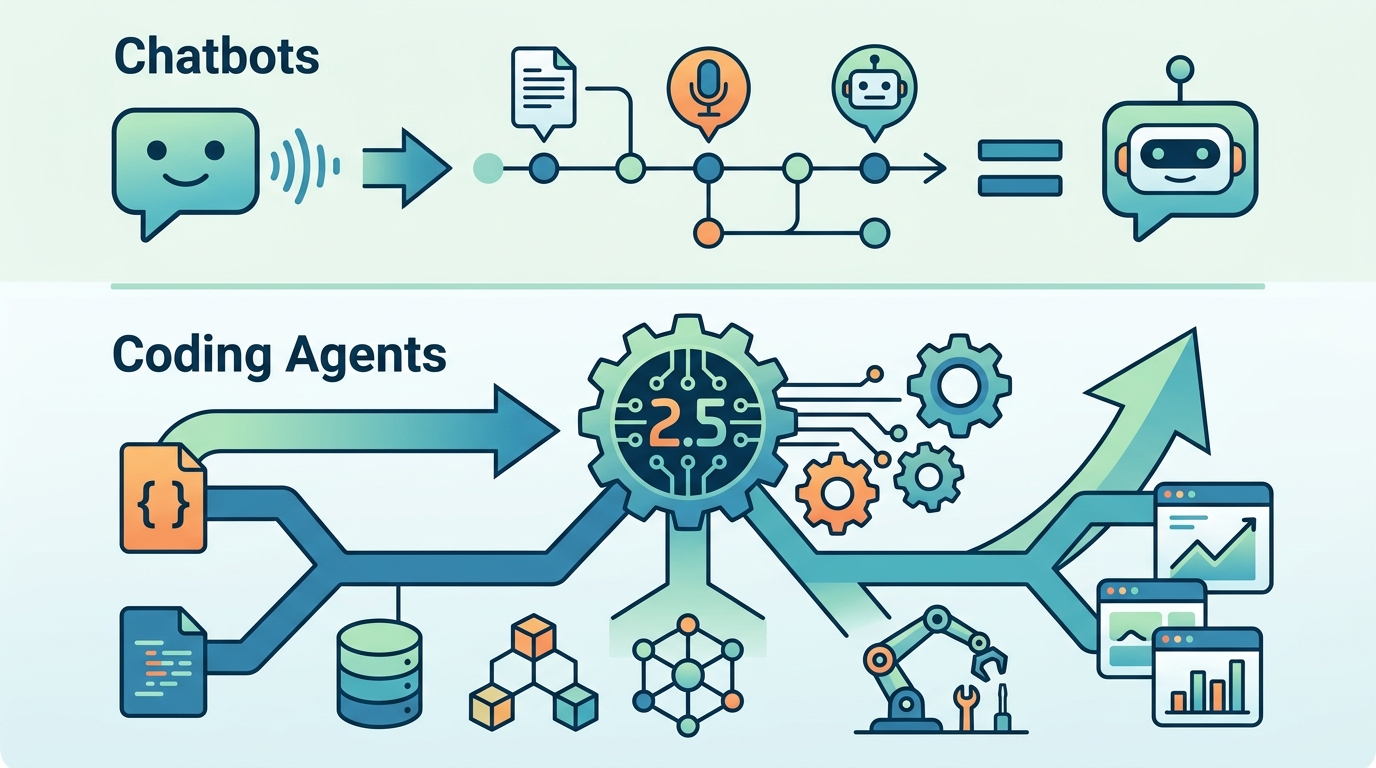
The broader release tells the same story. Xiaomi says MiMo-V2.5 also handles text, images, video, and audio with one million token context, while the ASR model supports Chinese, English, dialects, and mid-sentence switches. This is a platform move, not a single-model stunt. Xiaomi is building a family that can support agentic products, and open weights are the fastest way to get adoption in that market.
The counter-argument
The strongest objection is simple: benchmark wins do not equal product reality. A model can ace a compiler task in internal tests and still struggle with messy repositories, flaky APIs, bad specs, and human reviewers who change their minds. Long-context performance also remains fragile. Xiaomi’s own history matters here, because the earlier MiMo-V2-Pro reportedly scored zero on OpenAI’s GraphWalks benchmark at one million tokens, which is a reminder that long-range reasoning can collapse even when headline numbers look strong.
There is also a broader skepticism around open-weight releases from large hardware companies. They can look impressive on paper while still being hard to serve, hard to fine-tune, or hard to integrate into a real engineering stack. The fact that Xiaomi highlights internal tests, token savings, and staged post-training does not erase the gap between a controlled demo and a production codebase with legacy dependencies and human constraints.
That critique is valid, but it does not overturn the main conclusion. The point of MiMo-V2.5-Pro is not that it has solved software engineering; it is that the benchmark target has changed. A model that can manage multi-hour tasks, preserve context, and recover from its own mistakes is already more useful for agentic coding than a model that only shines in short prompts. Even if some demos are curated, the direction is real and the numbers Xiaomi published are strong enough to matter.
What to do with this
If you are an engineer or PM, treat MiMo-V2.5-Pro as a sign to redesign workflows around long-horizon execution: break work into observable stages, log tool calls, measure token burn, and build recovery steps for when the model regresses mid-task. If you are a founder, stop shopping for the smartest chat model and start testing which model can sit inside a loop for hours without blowing up cost, latency, or state. The winners in this phase are not the best conversationalists; they are the best operators.
// Related Articles
- [MODEL]
GPT-5.6 turns OpenAI into a model menu
- [MODEL]
Seedream 5.0 Pro Is the Right Choice for Editable AI Images
- [MODEL]
Midjourney v8.2 release is close
- [MODEL]
Rust KRAID enters Mesa for Arm Mali GPUs
- [MODEL]
OpenAI Opens GPT-5.6 and Launches Live Voice AI
- [MODEL]
Mistral is right to push Leanstral into proof engineering