Five AI Infra Frontiers Bessemer Expects for 2026
Bessemer’s 2026 AI infra roadmap points to memory, continual learning, RL, inference, and world models as the next big build areas.
AI infrastructure is changing fast. In its 2024 roadmap, Bessemer Venture Partners backed names like Anthropic, Fal AI, Cursor, and Vapi. For 2026, the firm says the next wave is about getting AI out of demo mode and into systems that remember, learn, act, and run in the real world.
The shift is easy to miss if you only watch model benchmarks. The first generation of AI infra was built for bigger models, more data, and better training runs. The next generation is about what happens after a model ships: how it keeps context, how it improves from use, how it handles decisions with delayed feedback, how it runs cheaply at scale, and how it interacts with physical or simulated environments.
Bessemer’s thesis is simple and pretty convincing: the center of gravity is moving from model building to model operation. That means the most interesting startups may look less like classic ML tooling and more like memory systems, eval platforms, reinforcement learning stacks, inference optimization layers, and world-model infrastructure.
1. The new AI stack needs memory, not just models
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The first frontier Bessemer calls out is what it labels “harness” infrastructure. The idea is straightforward: as AI systems become compound systems, the hard part is no longer getting a model to answer a prompt. The hard part is making sure the model has the right context, the right memory, and the right guardrails to answer like a useful employee instead of a confident autocomplete engine.
That matters because enterprise AI still fails in familiar ways. A model may answer with the right tone and the wrong facts. It may drift away from the original request. It may produce something plausible enough that nobody flags the error. Bessemer says an estimated 78% of AI failures are invisible, and that is the kind of number that should make any product team nervous.
Traditional monitoring tools catch latency spikes and error codes. They do not catch a chatbot that quietly misunderstands a customer or an internal agent that confidently invents a policy. That is why memory, retrieval, context management, and semantic evaluation are becoming their own categories instead of side features.
- 78% of AI failures are described as invisible by Bessemer’s analysis
- 93% of those failure patterns persist even with stronger models
- Production AI now needs cross-session memory, not just single-turn retrieval
- Semantic evals are replacing simple thumbs-up and thumbs-down signals
This is also where the tooling market gets interesting. Teams are moving from hand-rolled vector databases and one-off retrieval logic toward dedicated infrastructure for long-term memory, observability, and judge-based evaluation. That is a much better fit for real products than the old “just add RAG” playbook.
2. Continual learning is the answer to frozen weights
Bessemer’s second frontier is continual learning systems. Current foundation models are frozen after training, which means they can adapt in context, but they do not truly learn from use. That creates a hard ceiling for long-lived products. If a customer uses the same agent for months, the system should get better at that customer’s workflows. Today, most models only fake that improvement through longer prompts and more stored context.
The problem is cost as much as capability. Context windows keep growing, KV caches get expensive, and “remember everything” turns into a budget problem fast. Continual learning tries to solve this by letting models update over time without forgetting earlier skills.
Bessemer points to a range of approaches, from research-heavy architecture bets to more practical production techniques. Some teams are trying to make learning happen during inference itself. Others are compressing long contexts into reusable memory structures. The common thread is that learning no longer ends when training ends.
“Finally, AI is able to do productive work, and therefore the inflection point of inference has arrived.” — Jensen Huang, NVIDIA GTC 2026 keynote
That quote matters here because continual learning only becomes valuable if systems are already doing real work in production. Once AI is inside workflows, the pressure to improve from experience gets intense. A static model that never adapts starts to look dated very quickly.
Bessemer also notes that continual learning will need new governance tools. Rollbacks, lineage tracking, isolated experiments, and proper benchmarks all become mandatory if models are allowed to update themselves. Without those controls, “learning” can turn into silent regression.
3. Reinforcement learning is moving from research to product
The third frontier is reinforcement learning platforms. This is where the article gets especially practical. Human-labeled datasets helped the first wave of AI systems learn patterns, but they do a poor job teaching agents how to make multi-step decisions with delayed consequences. If the task is booking travel, resolving a support issue, or running a workflow across multiple tools, static labels are a weak substitute for experience.
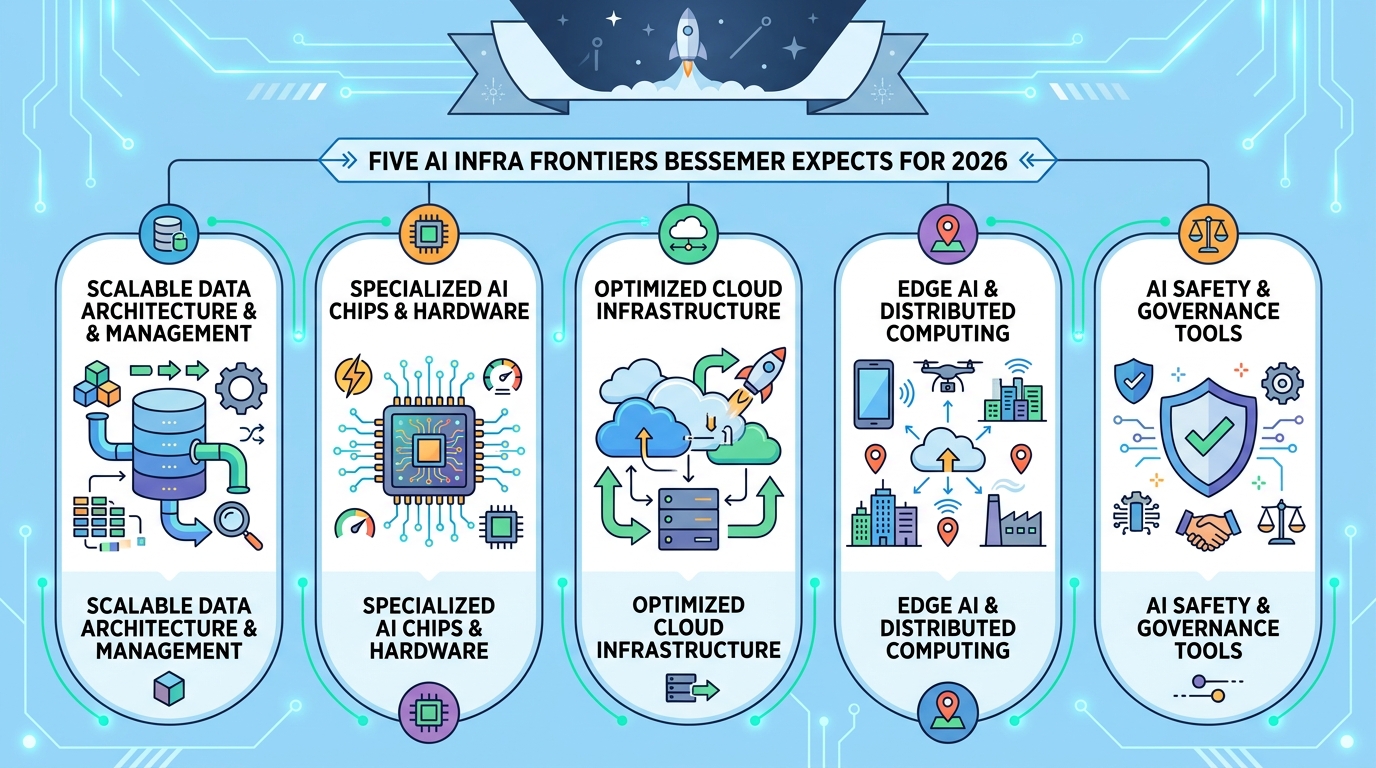
That is why Bessemer sees RL as a core infrastructure layer for the next phase of AI. The firm points to a stack that includes environment building, experience curation, RL-as-a-service, and platform infrastructure. The common goal is to let models learn by interacting with systems, not just reading examples.
Compared with supervised learning, RL infrastructure has a much messier feel. You need environments that behave like the real world, reward functions that do not break under pressure, and tooling that can handle long trajectories. That makes the market attractive for startups with deep systems chops and a tolerance for ambiguity.
- Human-labeled data still matters, but it is not enough for agentic systems
- RL teaches through interaction, not static examples
- Infrastructure now spans environments, rewards, and trajectory tooling
- Production RL needs safer experimentation than real-world trial and error
This is also where some of the most interesting companies may emerge. The market is not just looking for better datasets. It is looking for ways to simulate experience, score outcomes, and improve decision-making without shipping broken behavior to customers.
4. Inference is becoming the bill that matters
Bessemer’s fourth frontier is the inference inflection point. For a while, AI infrastructure spending was dominated by training. That made sense when the industry was obsessed with building the biggest model possible. But the economics are changing. As AI agents move from prototypes to production, inference workloads are eating a larger share of compute and budget.
This is a big deal because inference is where users feel the product. It determines latency, throughput, and cost per task. A company can have a brilliant model and still lose money if every request is too expensive to serve. That is why the new wave of infra is about reducing recomputation, improving routing, and making serving smarter across different hardware setups.
Bessemer names vendors such as Baseten, Fireworks AI, and Together AI as earlier movers in this space, while newer players like TensorMesh, RadixArk, and Inferact are pushing deeper into optimization. The point is not that one serving stack wins forever. The point is that inference is now a first-class product problem.
- Inference now rivals training in compute demand for many AI products
- Lower latency directly improves user experience and unit economics
- Routing, caching, and scheduling matter more than raw model size
- Edge and on-device inference are becoming more important as AI spreads
For developers, this means one thing: model quality alone is no longer enough. If your app burns cash every time it answers a question, the product math breaks. Inference tooling is now where a lot of the real engineering value sits.
5. World models push AI into physical and simulated space
The fifth frontier is world models, which is where the roadmap gets more ambitious. If the earlier sections are about making AI better at software work, world models are about helping AI understand environments, physics, and action over time. That matters for robotics, simulation, autonomous systems, and any product where the model has to reason about how the world changes after it acts.
This is a different kind of infrastructure problem. You are no longer just asking whether a model can answer correctly. You are asking whether it can predict outcomes, adapt to feedback, and operate in settings where mistakes have real consequences. That requires better simulators, better training loops, and better ways to connect perception with planning.
Bessemer’s broader thesis is that AI infra is moving from “brains” to “experience.” The first phase gave us models that could talk. The next phase is about models that can remember what happened, learn from it, and act with fewer hand-built constraints.
For builders, the takeaway is blunt: the best opportunities may sit one layer below the flashy app demos. If you are building memory, evals, RL environments, serving systems, or simulation tooling, you are probably closer to where the next durable infrastructure companies will come from. If you want a useful comparison point, our own coverage of the shift from model-first stacks to production-first tooling is in OraCore’s Software 3.0 roadmap.
The next 12 to 18 months should tell us whether these five frontiers turn into real platform categories or stay as smart venture theses. My bet is that memory and inference will produce the earliest breakout winners, because both already have pain, budgets, and buyers. The bigger question is whether continual learning and RL can move from research excitement to repeatable enterprise value before the market gets crowded.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production