Why container design patterns matter more than orchestration
Container design patterns are the real unit of distributed-systems thinking, not orchestration alone.
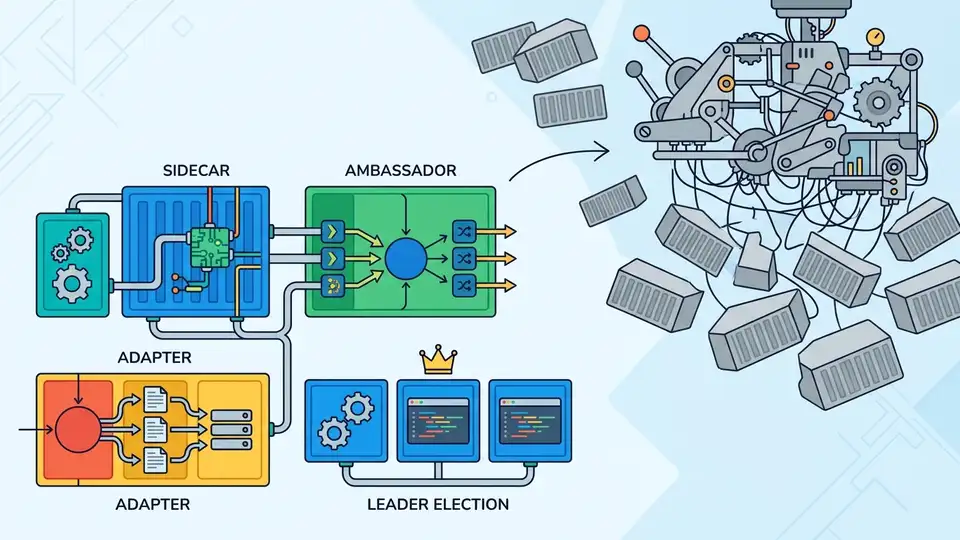
Container design patterns are the real unit of distributed-systems thinking, not orchestration alone.
Container orchestration is not the main story anymore; the real advantage comes from treating containers as composable building blocks for distributed systems.
That shift matters because the industry has already stopped using containers only as a packaging format. Teams now use them for sidecars, init containers, job runners, service meshes, and multi-container pods that coordinate work on the same machine. At larger scale, the same mindset shows up in sharded services, batch pipelines, and failover topologies that span many nodes. The pattern is clear: once containers become coordination units, the design problem changes from “how do I run this image?” to “how do I make these processes cooperate reliably?”
First argument: containers only become valuable when they are designed as a local coordination layer
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
On a single machine, the best container patterns solve tight, practical problems: bootstrapping, sharing state, isolating concerns, and splitting responsibilities without forcing everything into one process. An init container that prepares config before the app starts is not a deployment trick; it is a coordination pattern that keeps startup logic out of the main service.
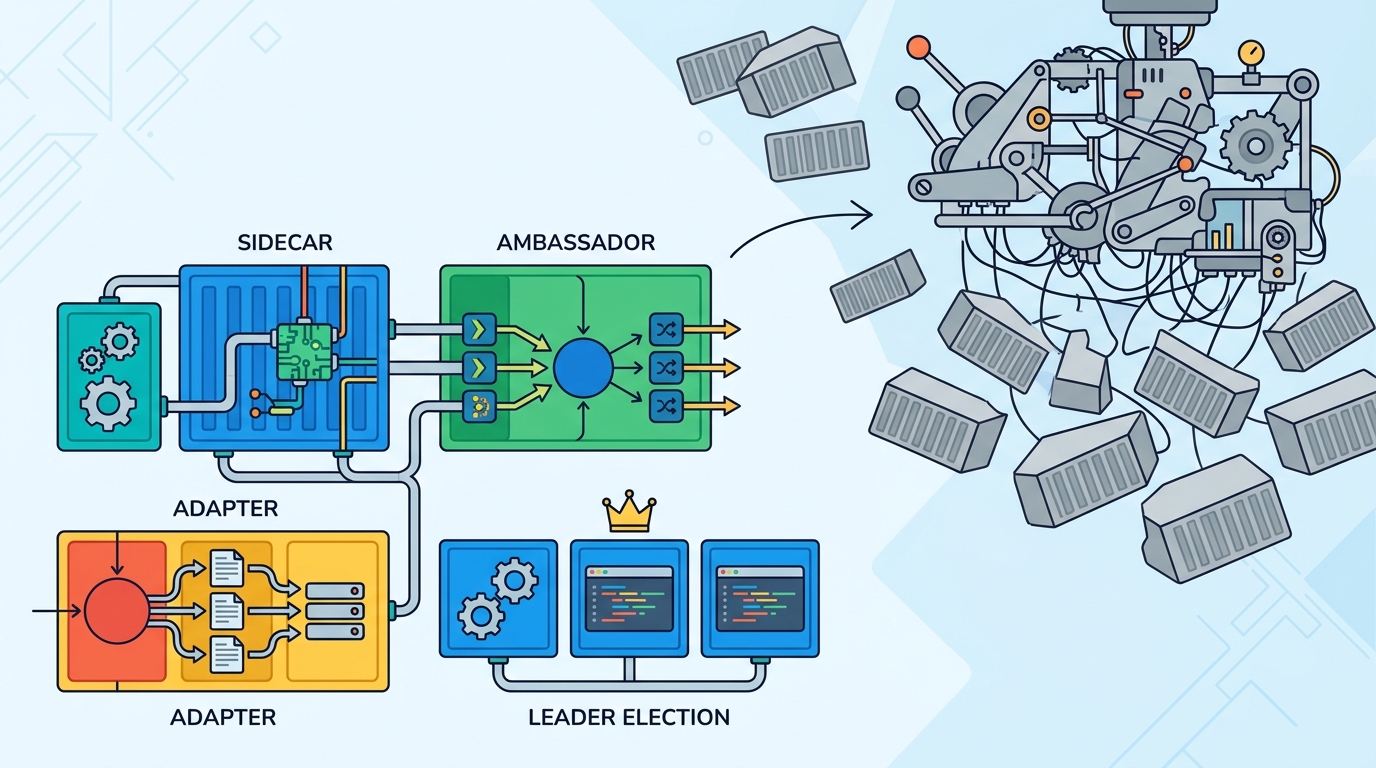
Sidecars make the same point even more clearly. Logging agents, proxies, and metrics exporters often live beside the application container because they need the same lifecycle and network namespace, but not the same codebase. That separation is more than convenience. It lets engineers change observability, security, or traffic handling without touching business logic, which is exactly what a useful design pattern should do.
Second argument: distributed systems fail when teams ignore the coordination boundary
The second class of patterns matters because distributed work is not just “more containers.” It is a different coordination problem. A batch job that runs across multiple nodes, a service that shards data, or a worker fleet that retries failed tasks all need explicit rules for partitioning, ownership, and recovery. Without those rules, containers become a pile of isolated units that look portable but behave unpredictably under load.
Consider Kubernetes Jobs and CronJobs. They are widely used because they encode recurring distributed behavior into a repeatable abstraction: run this work once, finish it, retry it, and stop. That sounds simple, but it replaces a lot of fragile custom scripting. The same idea scales into leader election, rolling updates, and replica coordination. The winning pattern is not the container itself; it is the coordination contract wrapped around it.
The counter-argument
The strongest objection is that this language overstates the importance of patterns and underplays the platform. Kubernetes, service meshes, and managed runtimes already hide most of the hard parts. If the platform owns scheduling, health checks, networking, and retries, why elevate design patterns at all? A team can just adopt standard primitives and move on.
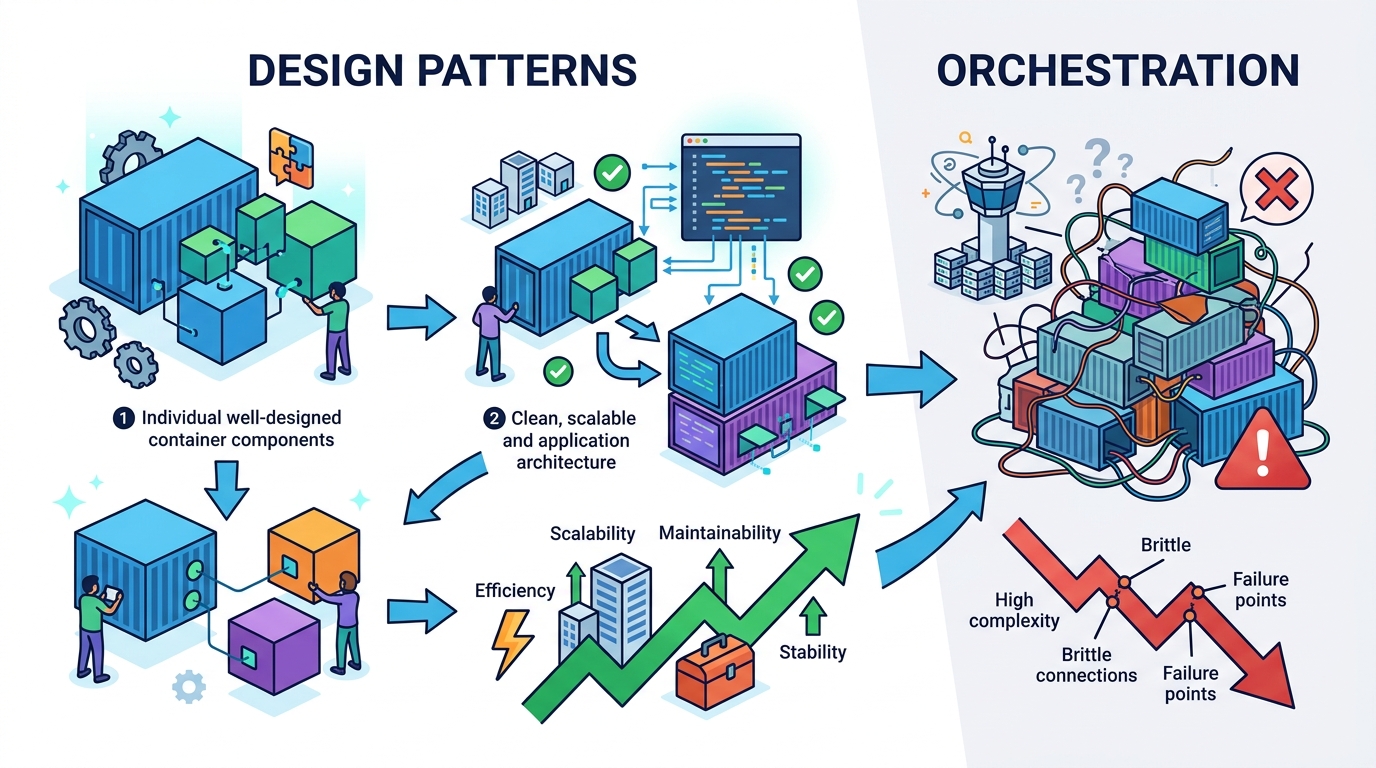
There is truth in that view. Platform defaults do remove a lot of accidental complexity, and many teams should use them instead of inventing their own abstractions. But that does not erase the need for patterns. It only means the patterns move up a level, from infrastructure mechanics to system design. The platform tells you how containers start and talk; it does not tell you when to split a service, when to colocate helpers, or how to model failure domains. That is still the engineer’s job.
What to do with this
If you build distributed systems, stop asking whether a container is “just packaging.” Treat every container boundary as an architectural decision. Use single-machine patterns to separate startup, proxying, logging, and app logic. Use multi-machine patterns to make ownership, retries, sharding, and failover explicit. If you are a founder or PM, push your team to describe these boundaries in product terms: what must be isolated, what must scale together, and what must recover independently. That discipline produces systems that are easier to operate, easier to evolve, and harder to break.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production