Why routing is the real bottleneck in model serving
Routing, not model execution, is the main constraint in modern model serving.
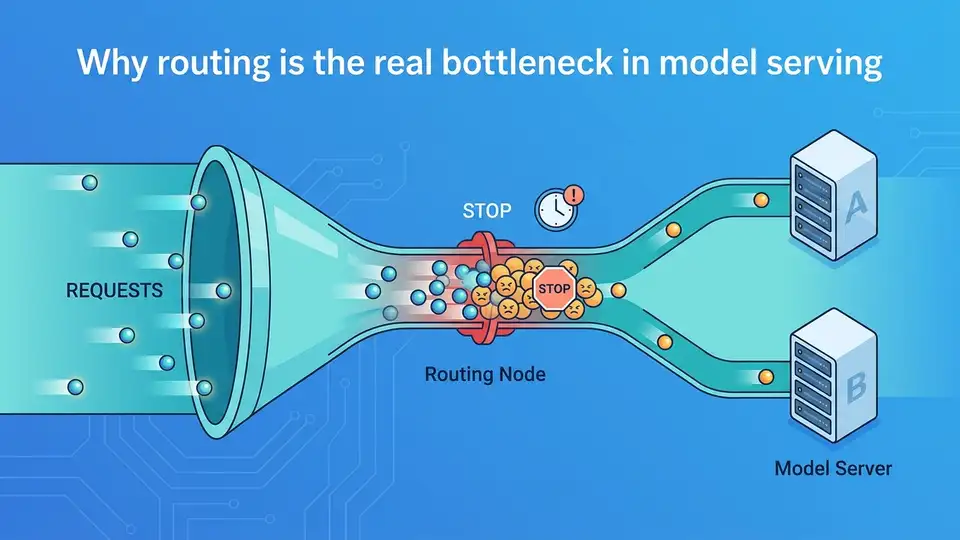
Routing, not model execution, is the main constraint in modern model serving.
I think the biggest mistake in model serving today is treating routing as a plumbing detail. It is not. At scale, the decision of where a request goes determines latency, utilization, cost, and even whether a system stays stable under load. Netflix’s focus on routing in model serving is the right one because the serving stack is no longer just about running a model fast; it is about choosing the right model, the right replica, and the right path for every request.
Routing now shapes the economics of serving
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The first reason routing matters is simple: every wasted request is a direct tax on inference cost. If a system sends traffic to a cold replica, a saturated GPU, or a model version that is not the best fit, the serving layer burns money before the model even starts doing useful work. In high-volume environments, small routing inefficiencies multiply into real infrastructure spend.
Netflix is a good example of why this is no longer theoretical. A company serving personalized experiences at massive scale cannot afford a naive round-robin approach and call it a day. Routing has to account for model availability, traffic patterns, and operational constraints, because the wrong destination can create tail latency and uneven utilization across the fleet. That is an economics problem, not just an architecture choice.
Routing is now part of model quality
The second reason is that routing affects output quality, not just performance. In modern serving systems, the router often decides which specialized model handles a request, which version is promoted, or whether a fallback path should take over. That means routing policy becomes part of the product surface. If the router is weak, the user experiences a weaker system even when the underlying models are strong.
We already see this pattern in systems that use ensembles, canaries, or per-segment model selection. A recommendation model for one audience segment can be excellent and wrong for another. A routing layer that understands request context can preserve relevance, while a simplistic dispatcher can flatten those differences and degrade results. In other words, routing is not separate from model intelligence. It is one of the mechanisms that lets intelligence show up in production.
The old serving mindset is too narrow
The third reason I reject the old mindset is that many teams still design serving around a single model endpoint and then bolt on scaling later. That approach fails once the stack includes multiple models, heterogeneous hardware, traffic shaping, and fast rollouts. The serving problem is no longer “how do I expose inference?” It is “how do I continuously place work across a changing fleet?”
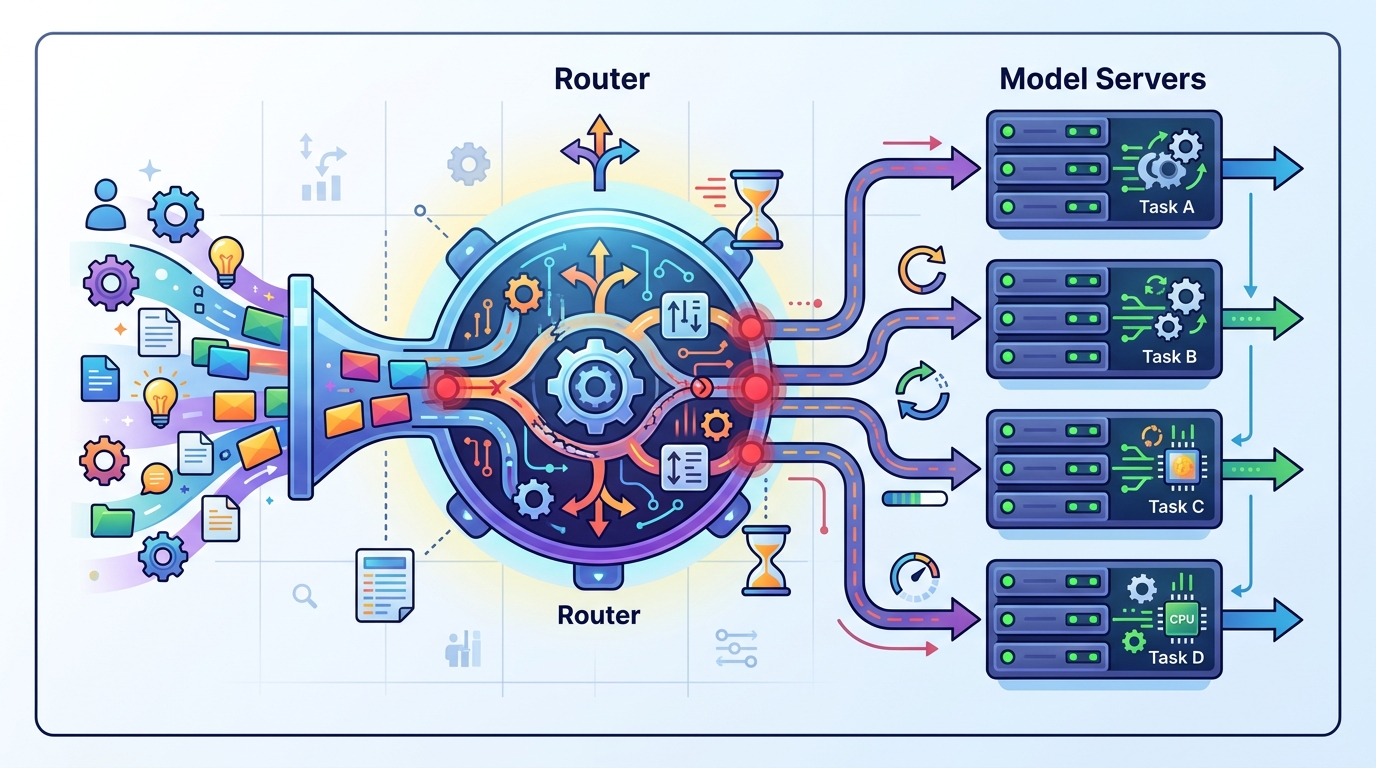
That shift is exactly why a series on routing is useful. It signals that the hard part is not the inference call itself but the control plane around it. Once a company has enough traffic, the router becomes the system that keeps experiments isolated, failures contained, and expensive capacity actually used. Teams that ignore that reality end up building brittle serving stacks that look simple on paper and collapse under operational pressure.
The counter-argument
The strongest objection is that routing can become over-engineered. Many teams do not need sophisticated placement logic, dynamic policies, or multi-stage decisioning. A small product with one model, one hardware tier, and modest traffic can get by with a straightforward load balancer and a single deployment target. In that context, spending too much time on routing is wasted effort.
That objection is valid at small scale. If your serving footprint is tiny, the router should stay boring. But that is not an argument against routing as a discipline. It is an argument against premature complexity. The moment a team introduces multiple models, rollout strategies, or hardware constraints, routing stops being optional and starts being the mechanism that protects reliability and cost. The mistake is not building routing too early. The mistake is pretending you will not need it later.
What to do with this
If you are an engineer or platform owner, treat routing as a first-class subsystem and give it the same scrutiny you give model training and deployment. Measure tail latency, replica saturation, fallback rates, and per-route cost. Design for policy changes, not just static load balancing. If you are a PM or founder, push your team to define routing requirements alongside model requirements, because the serving strategy you choose will shape both user experience and cloud spend. Build the control plane before the scale forces you to.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production