Why Rust Workers need panic unwind, not just abort recovery
Rust Workers are reliable only when wasm-bindgen supports panic unwinding and abort recovery.

Rust Workers need panic unwinding and abort recovery to stay reliable after failures.
Rust Workers should not treat a panic as a routine crash; they should treat it as a state corruption bug unless the runtime can unwind or reset cleanly.
Cloudflare’s own account makes the failure mode plain: an unhandled Rust abort in a Worker could poison an instance, affect sibling requests, and even keep breaking new requests. That is not a rare edge case, it is a platform reliability problem. The old answer was to detect failure and reinitialize the whole application, which worked for stateless handlers but still left stateful workloads exposed to data loss and cascading errors.
First argument: panic=unwind is the real fix for stateful Rust on Wasm
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
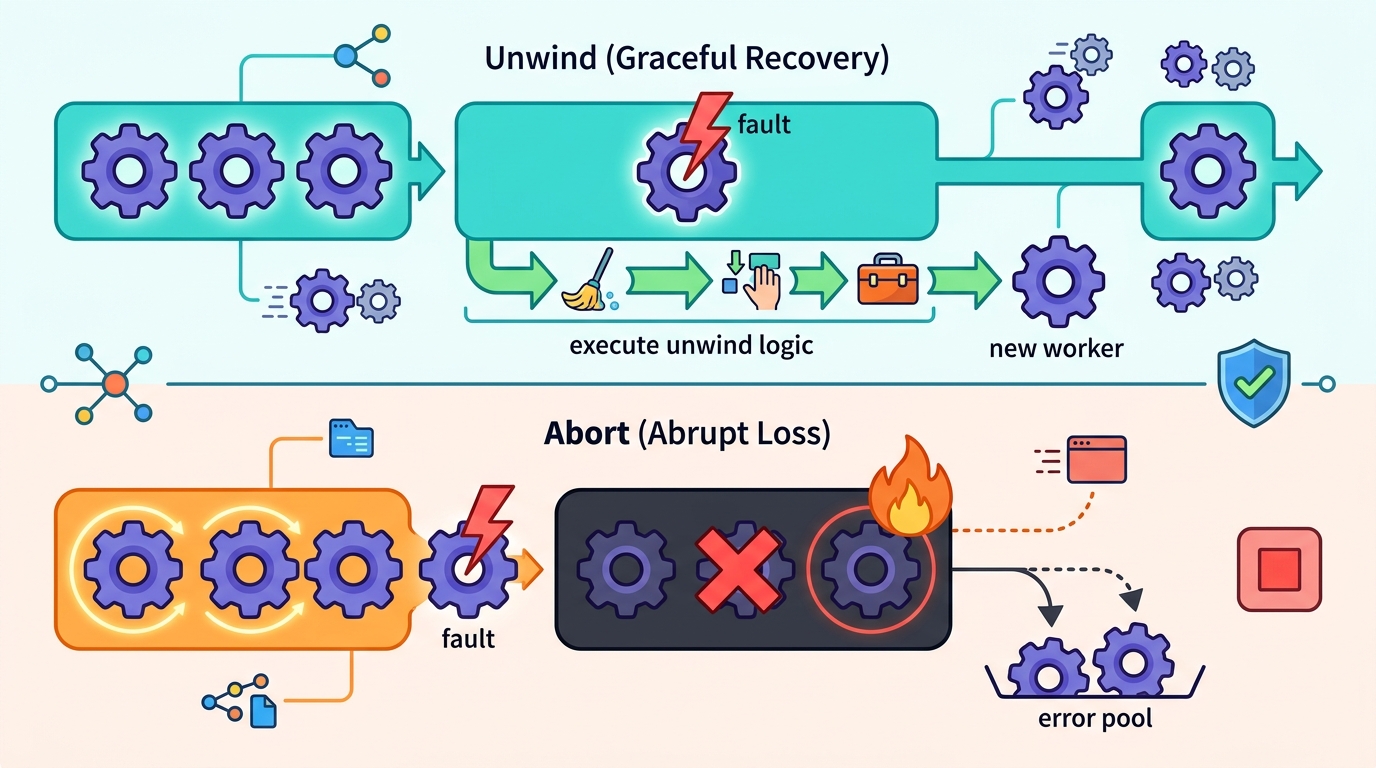
The first reason this matters is simple: reinitialization is not recovery when your program keeps meaningful in-memory state. Durable Objects and similar workloads depend on instance state surviving individual request failures. If one request panics and the runtime tears down the whole instance, every other concurrent request loses the state it was relying on.

The Cloudflare team points to the WebAssembly Exception Handling proposal, which gained wide engine support in 2023, as the key unlock. With panic=unwind, destructors run, catch_unwind works as expected, and the Rust-JavaScript boundary can convert failures into PanicError exceptions instead of leaving the instance in an undefined state. That is the difference between a service that degrades gracefully and one that silently poisons itself.
Second argument: abort recovery is still necessary, because unwind is not enough
Even with unwinding, aborts still exist, and out-of-memory is the obvious example. An abort cannot unwind, so it cannot preserve the current execution state. That means the platform still needs a hard recovery path that can detect the abort, stop invalid execution from spreading, and make sure future operations start from a valid baseline.
Cloudflare’s solution is not cosmetic. It adds abort hooks, reentrancy guards, and exception tagging so the runtime can tell a genuine abort from a foreign exception crossing the boundary. That distinction matters because WebAssembly and JavaScript can interleave deeply, with JS re-entering Wasm at arbitrary depths. Without explicit recovery semantics, one bad stack frame can contaminate unrelated work in the same instance.
The counter-argument
The strongest objection is that all of this complexity belongs in application code, not in the toolchain. A developer can already wrap risky operations, restart workers, or design stateless handlers. From that perspective, adding unwind support, exception tags, and reset-state hooks looks like an elaborate answer to a problem that disciplined architecture should avoid in the first place.
There is also a real portability concern. WebAssembly exception handling has had multiple variants, Rust still defaults to legacy behavior in some targets, and support across runtimes has not always moved in lockstep. If the ecosystem is fragmented, shipping around panic recovery can look like betting reliability on a moving standards target.
That objection fails on the core issue: the runtime is already shared state, so application-level discipline cannot fully contain a poisoned instance. When a platform allows concurrent tasks, nested JS-to-Wasm reentry, and long-lived in-memory state, failure semantics belong in the toolchain and the runtime. Cloudflare is right to push this upstream because the alternative is pretending that “restart on failure” is an acceptable answer for stateful systems. It is not.
What to do with this
If you are an engineer building on Rust Wasm, stop assuming panic=abort is a safe default. Use unwind where state matters, make exported boundaries explicit, and treat abort recovery as a last line of defense, not a feature you can skip. If you are a PM or founder, ask whether your Wasm stack can survive one bad request without losing unrelated work. If the answer is no, reliability is not solved yet, no matter how fast the happy path looks.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production