agents-radar tracks AI signals from 10 sources
This GitHub Actions project pulls AI signals from 10 sources daily, publishes bilingual digests, and exposes them through MCP.

agents-radar is one of those projects that makes you think, “why am I still checking ten tabs by hand?” It runs every morning at 08:00 CST, pulls signals from 10 sources, and publishes bilingual Chinese and English digests with GitHub Actions.
The repo has 617 stars and 70 forks, which is a healthy signal for a utility project that is more about workflow discipline than flashy UI. It is written in TypeScript, publishes daily issue-based reports, and also generates weekly and monthly rollups automatically.
What agents-radar actually collects
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core idea is simple: gather AI activity from places developers already watch, normalize it, and turn it into a readable digest. That includes repositories, papers, trending posts, product launches, and community discussion across a mix of code, research, and news surfaces.

What makes this useful is the breadth. Instead of relying on one feed, the project samples from GitHub, Hacker News, ArXiv, Product Hunt, Hugging Face, Dev.to, and Lobste.rs, then adds signals from Anthropic and OpenAI article updates. That gives the digest a better shot at catching what is moving across the AI ecosystem, not just what is loud on one platform.
- GitHub data covers issues, pull requests, and releases from 17+ tracked AI repos.
- Hacker News coverage uses six parallel queries and ranks the top 30 stories from the last 24 hours.
- ArXiv pulls the latest papers from cs.AI, cs.CL, and cs.LG within a 48-hour window.
- Hugging Face tracks 30 trending models sorted by weekly likes.
- Product Hunt captures yesterday’s top AI products by votes.
- Dev.to and Lobste.rs add developer commentary that often gets missed in product-centric feeds.
Bilingual digests with GitHub Actions
The automation story is the part I like most. The project uses GitHub Actions to run on a fixed schedule, then publishes the results as GitHub Issues and committed Markdown files. That means the archive is both readable and versioned, which is exactly what you want from a daily intelligence log.
It also generates weekly and monthly rollups, so the project is doing more than dumping daily noise into a repo. It is creating a time series you can skim, search, and compare over longer stretches. For anyone tracking the AI tool chain, that matters more than another feed with a pretty homepage.
“The best way to predict the future is to invent it.” — Alan Kay
That quote fits the repo’s design choice better than a generic “stay informed” slogan. agents-radar is not waiting for a dashboard vendor to package the ecosystem for you; it builds the digest from public sources and ships it on a schedule you can inspect.
The bilingual output is also a smart move. A lot of AI reporting tools pretend the audience is one language, one region, and one reading habit. This project treats English and Chinese as first-class outputs, which makes the archive useful for a wider set of developers, researchers, and operators.
How the source mix changes the signal
The source list is not random. It mixes fast-moving social signals with slower, more durable ones. That helps the digest catch both “what people are talking about today” and “what may matter next month.”
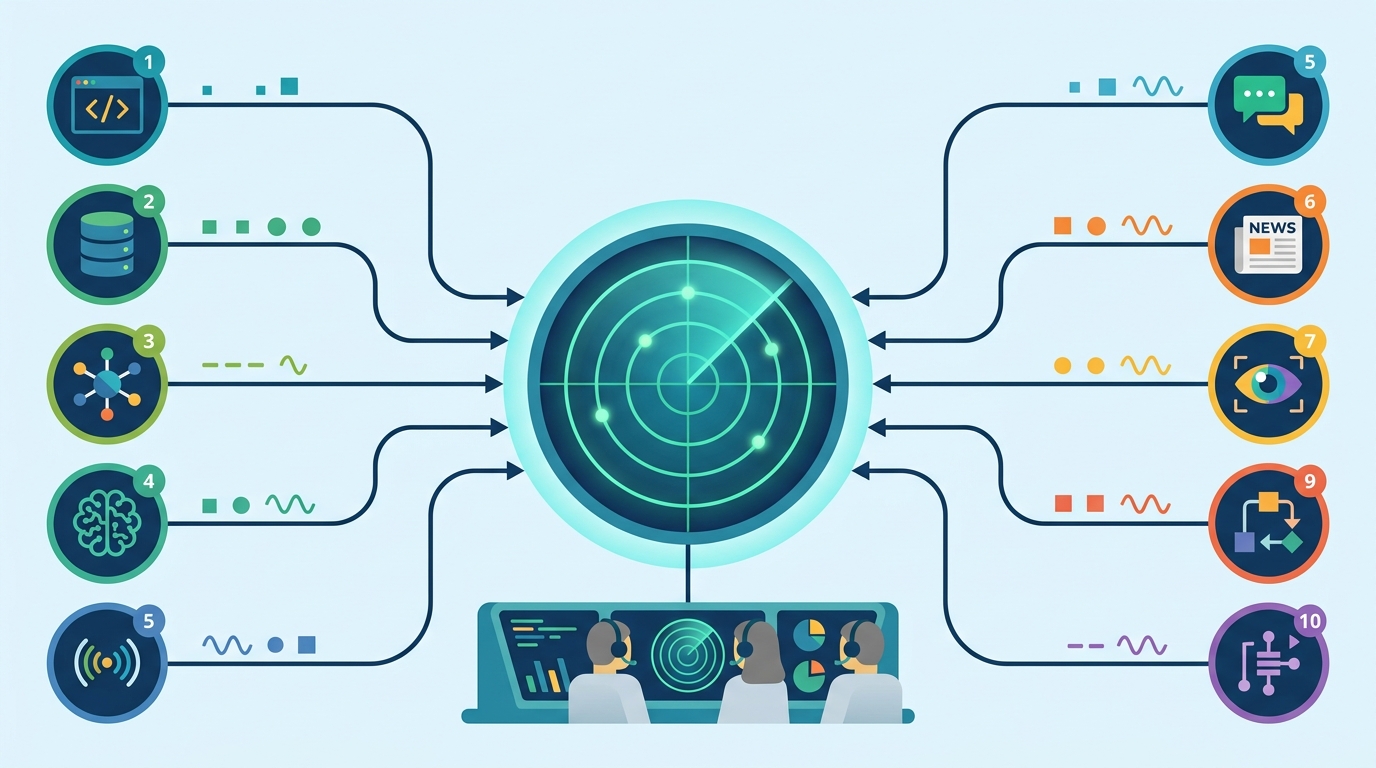
Here is the practical comparison: HN gives you speed, ArXiv gives you research depth, Hugging Face gives you model momentum, and GitHub gives you implementation activity. Product Hunt adds launch energy, while Dev.to and Lobste.rs add practitioner discussion. In other words, the project is trying to reduce the blind spots that come from using a single feed as your compass.
- Algolia HN Search API powers six parallel queries: AI, LLM, Claude, OpenAI, Anthropic, and machine learning.
- ArXiv API is queried for papers posted in the last 48 hours, which keeps the research feed tight.
- Hugging Face Hub API surfaces 30 trending models, ranked by weekly likes rather than raw popularity alone.
- Forem API and Lobste.rs JSON API add community-written analysis and niche technical discussion.
- Anthropic and OpenAI are monitored through sitemap last-modified diffs, which is a clever low-overhead way to detect new pages.
MCP makes the archive usable in chat tools
The other standout piece is the hosted Model Context Protocol server at agents-radar-mcp.duanyytop.workers.dev. That turns the digest archive into something a client can query directly, instead of forcing you to click through pages or search manually.
The available tools are practical: list_reports, get_latest, get_report, and search. If you use Claude Desktop or an MCP-compatible client like OpenClaw, you can ask for the latest AI CLI tools, search for a specific repo mention, or pull a report by date.
That matters because it changes the archive from “content you read” into “data you query.” For teams watching AI tooling, that is a meaningful difference. A digest is nice; a digest that can answer questions inside your assistant is much better.
Self-hosting is also available from the mcp/ directory, which is the right move for a project like this. If the hosted endpoint ever changes, or if a team wants local control, the same idea can be deployed privately with Wrangler.
Why this project matters now
AI news has become too fragmented for casual monitoring. One day the signal is a new CLI tool, the next day it is a model release, and by Friday the interesting thing is a paper that quietly picked up traction on ArXiv. agents-radar tries to keep all of that in one place without pretending every signal has the same weight.
My read: the most useful part of this repo is not the digest itself, but the architecture behind it. Scheduled collection, bilingual publishing, historical archives, and MCP access create a system that can keep up with a fast-moving field without turning into another noisy feed.
For developers building internal radar tools, this repo is a strong reference. The next sensible step is to add team-specific filters, because once you can query the archive through MCP, the obvious question becomes: which AI signals matter for your stack, your market, and your release cycle?
If this project keeps its current pace, I expect more teams to copy the pattern: public-source aggregation, language-aware reporting, and assistant-friendly access to the archive. The question is no longer whether AI monitoring should be automated. The real question is which sources you trust enough to let into the loop.
// Related Articles
- [TOOLS]
Aliyun Bailian Token Plan turns credits into agents
- [TOOLS]
One API gateway turns six AI APIs into one
- [TOOLS]
OpenAI FDEs turn broken agents into shipped systems
- [TOOLS]
Anthropic’s daily brief turns news into a workflow
- [TOOLS]
Claude Reflect turns usage into retention
- [TOOLS]
Midjourney turns prompt ideas into art