Why AI coding agents need an architecture compiler
Atomadic Forge proves AI code needs structural enforcement, not just tests and linting.
Atomadic Forge turns AI-generated code into a scored, enforceable architecture.
Atomadic Forge is right: AI coding agents need an architecture compiler, not another prettier linter. The problem is not that agents fail to write working code. The problem is that they write code that runs while quietly breaking the shape of the system, and that shape is what keeps a repository maintainable after the demo is over. Thomas Colvin’s tool treats architecture as something you can certify, enforce, and measure, and that is the correct response to code sprawl driven by agents.
That claim is not hand-wavy. In the documented test, Forge moved a repository from a structural score of 47 to 91, cut violations from 34 to 3, and auto-fixed 31 issues in place. It also ships with 944 tests and a SHA-256 receipt for structural integrity. That is the right kind of proof for this problem: not “the tool feels smart,” but “the system can detect, change, and verify the structure of the codebase.”
AI code sprawl is an architecture problem, not a syntax problem
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Linting and type checking catch local mistakes. They do not stop a utility module from importing a feature module, or a CLI entry point from absorbing business logic, or two services from forming a circular dependency. Those are architectural failures, and they are exactly the kind that AI agents create at speed. When an agent can generate hundreds of lines in a single pass, the bottleneck is no longer correctness at the statement level. It is structural drift across the repository.
Forge’s five-tier composition law is the strongest part of the idea because it gives that drift a hard boundary. Its tiers only import upward: a0 holds constants and pure data, a1 holds pure functions, a2 holds stateful classes and clients, a3 assembles features, and a4 handles orchestration and entry points. That is not academic decoration. It is a concrete rule that turns architecture into an enforceable contract, which is exactly what AI-generated code has been missing.
Scoring architecture changes how teams manage AI output
The 0-100 certification score changes the conversation from opinion to evidence. A team does not need to argue whether the repository “feels clean”; it can inspect a score, review the violations, and track whether enforcement improved the structure. In the example cited, the score climbed from 47 to 91 after enforcement. That is a meaningful jump because it shows the tool is not just flagging problems, it is actively reducing them.
The SHA-256 receipt matters for the same reason. Once architecture becomes something you can certify, you can gate merges, compare snapshots, and prove that a codebase met a structural standard at a point in time. That is especially useful in AI-assisted workflows, where code may be generated by different agents, in different editors, and under different prompts. A receipt gives teams an auditable artifact instead of a vague promise that “the architecture is fine.”
Agent-native enforcement beats post hoc cleanup
Forge works as an MCP server inside tools like Cursor and Claude Code, which is the correct place for this kind of enforcement. If the architecture check happens after the code lands, the repo already carries the cost of bad structure. If the check happens inside the agent’s workflow, the agent can be constrained before it writes the wrong dependency pattern in the first place. That is the difference between cleanup and control.
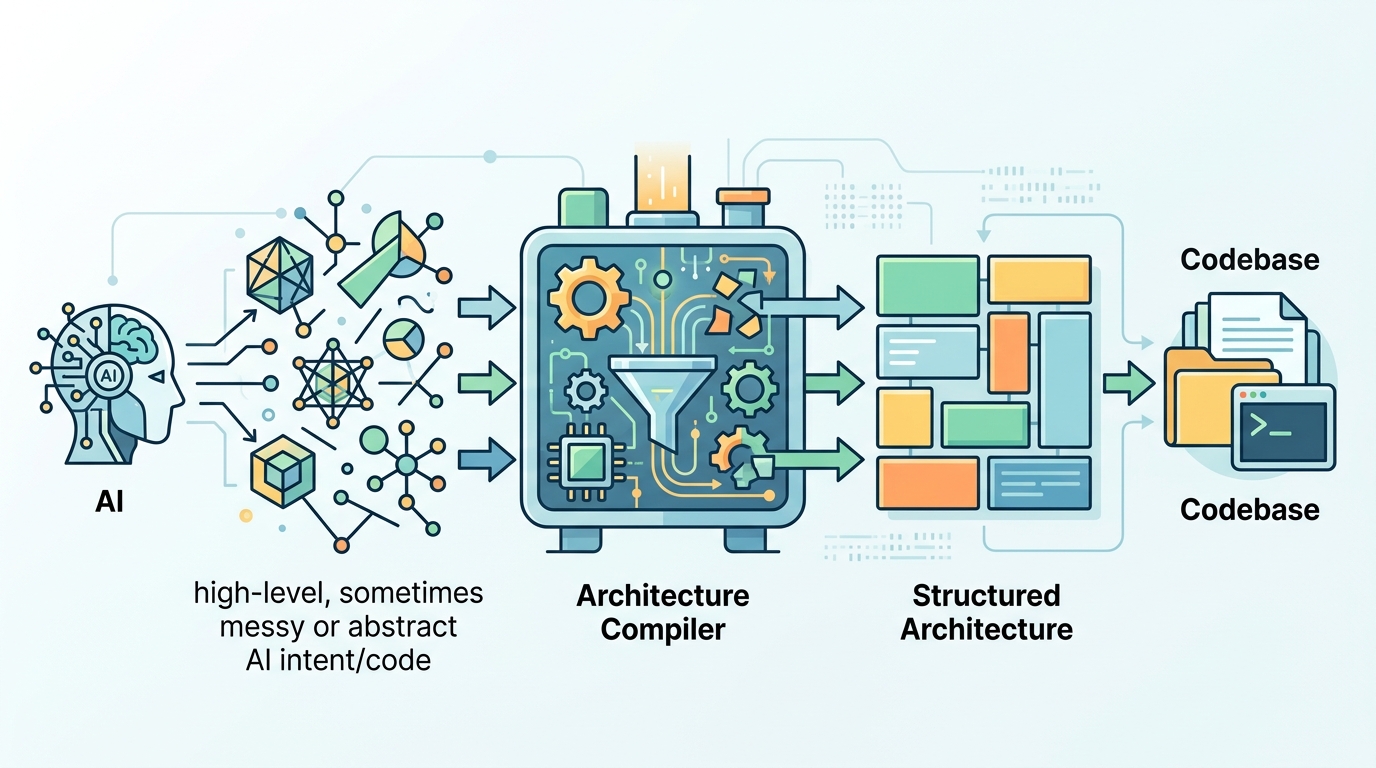
The practical examples make the case plainly. A documented issue like “utils.py -> feature_pipeline.py” is not a style nit; it is a violation of dependency direction that will compound over time. Likewise, 340 lines of business logic in an orchestration layer is not a harmless exception. It is the beginning of a tangled codebase where future changes become riskier because the system no longer has clear boundaries. Forge’s value is that it catches those exact failures while the agent is still in the loop.
The counter-argument
The strongest objection is that architecture cannot be reduced to a compiler rule. Real systems have edge cases, legacy constraints, and domain-specific exceptions. A rigid five-tier law can become dogma, and dogma can be worse than mess. Teams also risk overfitting to the tool’s model of “good architecture” and ignoring the actual needs of product velocity or domain complexity. In that view, the best architecture tool is the one that stays out of the way.
That objection is valid in one narrow sense: no tool should pretend it can define perfect architecture for every codebase. But it does not defeat Forge. It just defines the boundary of its usefulness. Forge is not promising architectural truth for every system; it is enforcing a clear dependency discipline where AI agents are most likely to create structural debt. That is a real and urgent problem, and the repo examples show the debt is not theoretical. The tool earns its place by catching the failures that humans miss after the code already works.
What to do with this
If you are an engineer, stop treating AI-generated code as if tests alone are enough. Add architectural checks to the same workflow where code is created, and make dependency direction, layer boundaries, and cycle detection part of your definition of done. If you are a PM or founder, ask for a structural score, not just passing CI. Working code is the floor; maintainable code is the product. Teams that ignore architecture in AI-heavy development will ship faster and pay for it later in refactors, outages, and stalled velocity.
// Related Articles
- [TOOLS]
Aliyun Bailian Token Plan turns credits into agents
- [TOOLS]
One API gateway turns six AI APIs into one
- [TOOLS]
OpenAI FDEs turn broken agents into shipped systems
- [TOOLS]
Anthropic’s daily brief turns news into a workflow
- [TOOLS]
Claude Reflect turns usage into retention
- [TOOLS]
Midjourney turns prompt ideas into art