Why RAG Beats Prompting for Private Data
RAG is the right architecture for answering questions over private, changing data.
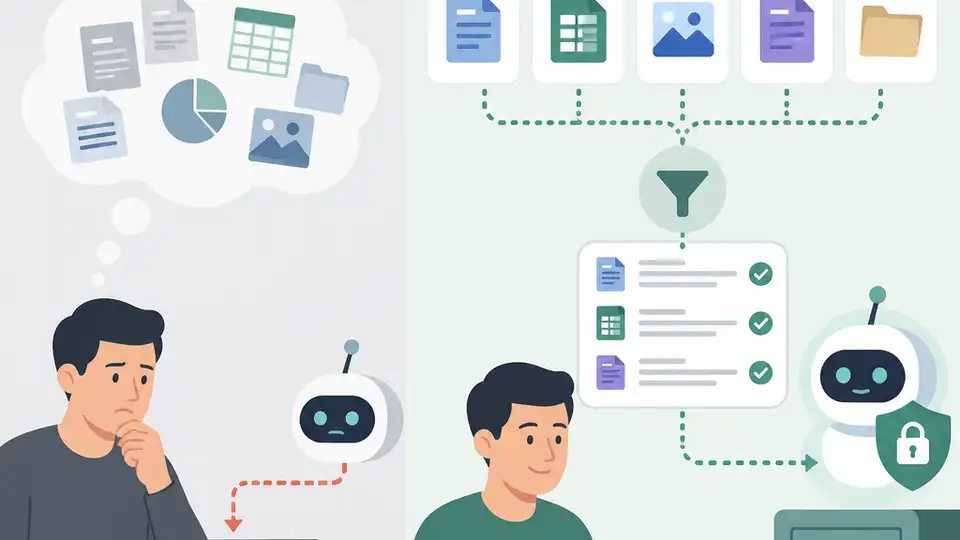
RAG is the right architecture for answering questions over private, changing data.
RAG is not a nice-to-have add-on for chatbots; it is the correct way to make LLMs useful on private data, changing policies, and fresh documents.
RAG fixes the core failure mode of LLMs
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The basic problem is not that LLMs are bad at language. They are bad at knowing what they were never trained on. The article’s examples are the right ones: company wikis, Slack history, Jira tickets, and yesterday’s events are outside the model’s memory. A prompt-only approach forces the model to guess, and guessing is exactly how hallucinations happen. RAG changes the task from recall to retrieval, which is the only sane way to answer questions over data that lives outside the model.
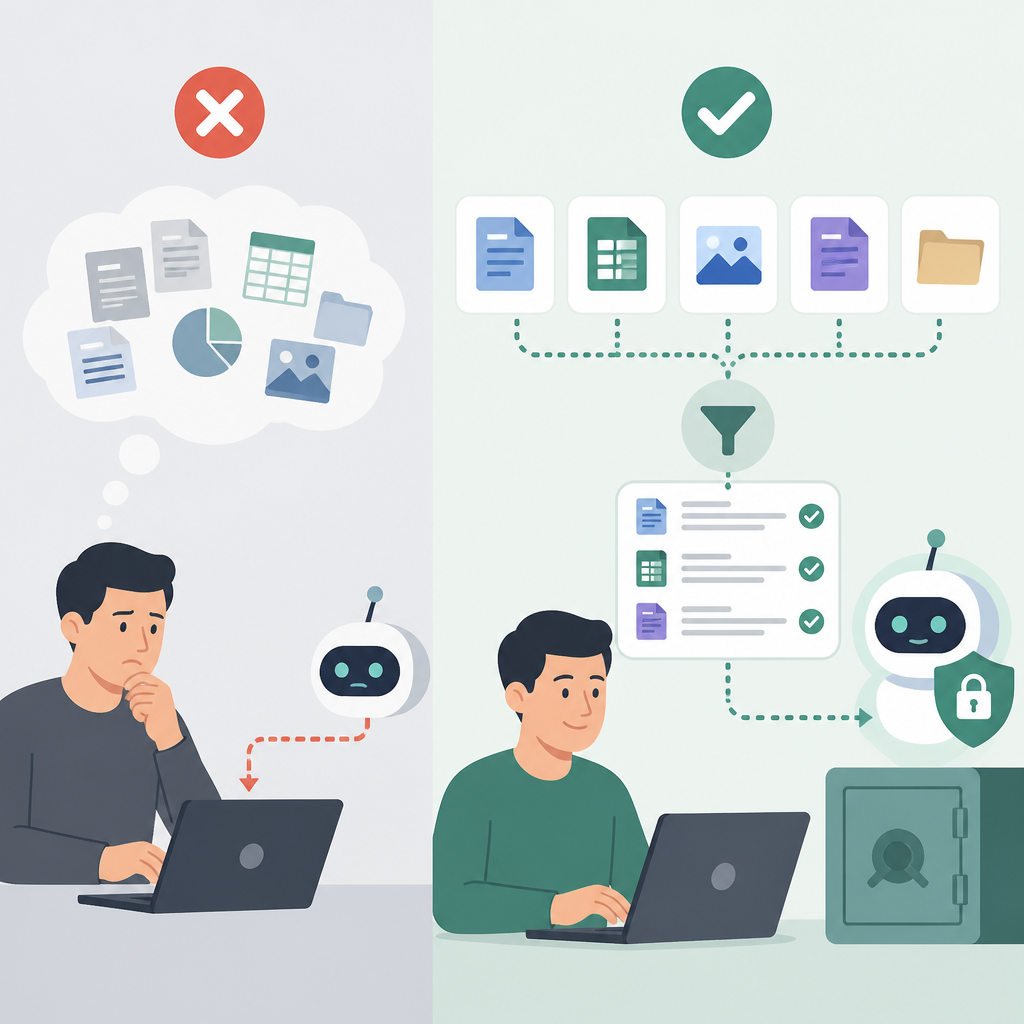
The open-book analogy is not just pedagogical; it reflects the architecture. Instead of stuffing the entire corpus into the prompt, RAG finds the relevant chunks and gives them to the model at answer time. That matters because context windows are finite and expensive. A 500-page handbook cannot be pasted into a prompt and expected to behave like a searchable knowledge system. RAG makes the model read the right page, not the whole library.
The pipeline is simpler than people think
RAG sounds fancy because the vocabulary sounds fancy. In practice, the pipeline is straightforward: load documents, split them into chunks, turn those chunks into embeddings, store them in a vector database, then retrieve the closest matches when a user asks a question. Each step has a clear job. Chunking prevents giant blobs of text from overwhelming the model. Embeddings turn meaning into numbers. Vector search finds semantically similar content instead of keyword matches.
The article’s project stack makes the point well: Python, LangChain, Gemini, and ChromaDB are enough to build a working “chat with PDF” system. That is not an argument for that exact stack forever; it is proof that RAG is an application pattern, not a research mystery. A developer does not need to retrain a foundation model to make it useful on a handbook. They need a retrieval layer, a prompt template, and a generation step that is constrained by the retrieved context.
RAG is better than fine-tuning for live knowledge
Fine-tuning gets oversold whenever teams want their model to “know” internal information. That is the wrong tool. Fine-tuning is slow, costly, and brittle when the underlying facts change. If a policy changes on Monday, retraining just to reflect that update is wasteful. RAG avoids that trap because the knowledge lives in the document store, not in the model weights. Update the source document, re-index it, and the system reflects the new truth immediately.
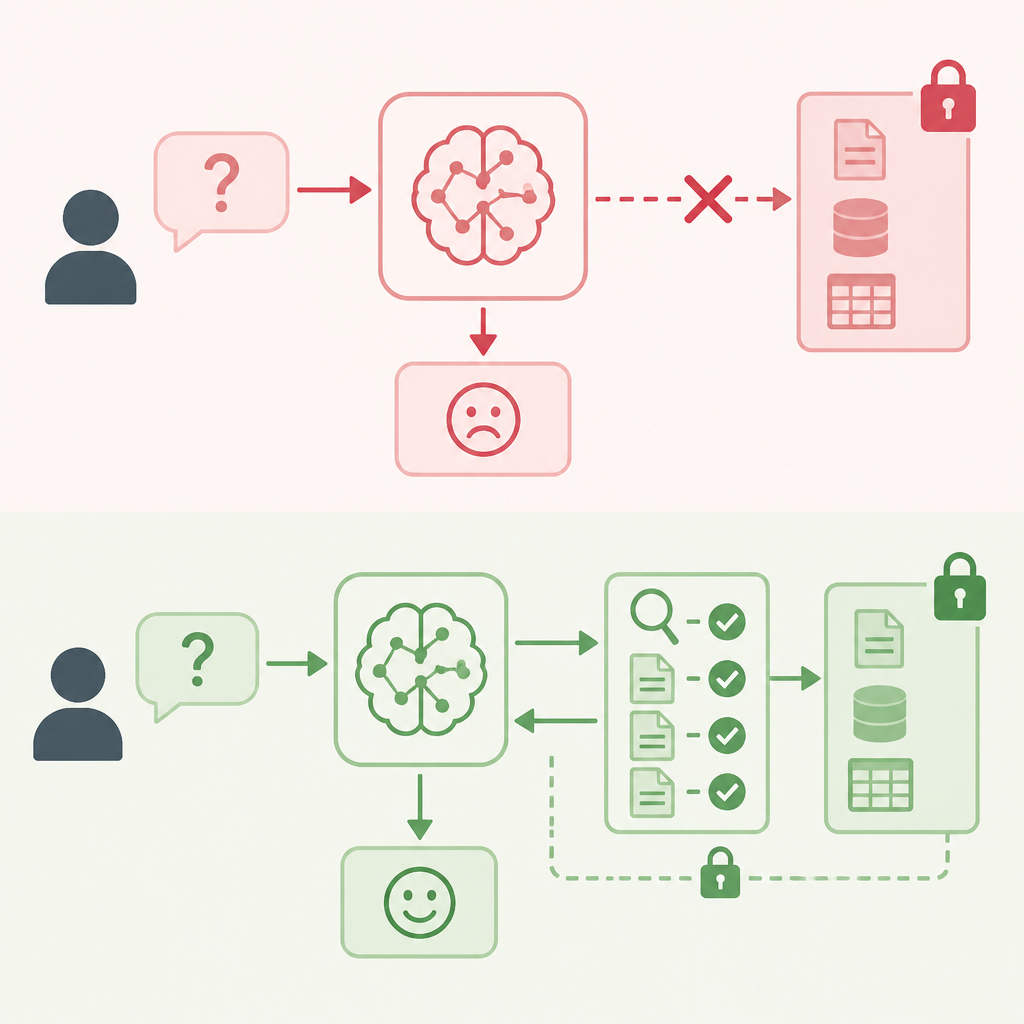
This is why RAG has become the default for support bots, document assistants, and internal search. It preserves the strengths of the LLM, fluent synthesis and natural language interaction, while outsourcing factual grounding to retrieval. The article’s emphasis on private data is the key point: most business value comes from answering questions against information that is specific, current, and controlled. RAG is built for that reality; fine-tuning is not.
The counter-argument
The strongest case against RAG is that retrieval can fail. If chunking is sloppy, embeddings are weak, or the vector search misses the right passage, the model will answer from incomplete context. Critics also note that RAG systems add moving parts: loaders, splitters, embedding models, databases, ranking logic, and prompt templates. A simple prompt can be easier to prototype than a full retrieval stack, especially for one-off tasks or tiny documents.
That criticism is valid at the prototype stage. If you have a short, stable document and a narrow use case, a direct prompt is faster to build. But that is not a reason to reject RAG; it is a reason to use the simplest tool that matches the scope. The moment your data is large, private, or changing, prompt-only systems collapse under their own limitations. RAG is not perfect, but it is the only architecture here that scales with real knowledge work.
What to do with this
If you are an engineer, stop trying to make the base model memorize your domain and start treating retrieval as a first-class product feature. Build a clean ingestion pipeline, choose chunk sizes deliberately, test retrieval quality before polishing the UI, and log failures so you can see which questions are missing context. If you are a PM or founder, define RAG use cases around documents that change often and answers that must be grounded in source material. That is where the ROI is real.
// Related Articles
- [TOOLS]
Nvidia and LG turn AI plans into a playbook
- [TOOLS]
Ollama is the best free AI path in 2026 for real work
- [TOOLS]
This MLOps list turns chaos into a stack
- [TOOLS]
BentoML turns model serving into Python APIs
- [TOOLS]
Magenta RealTime 2 lets you score in the DAW
- [TOOLS]
Open-source AI tools beat Claude’s paid tiers on value