Vector Databases: How AWS Explains Them
AWS explains how vector databases store embeddings, power similarity search, and support Bedrock apps with OpenSearch Service.
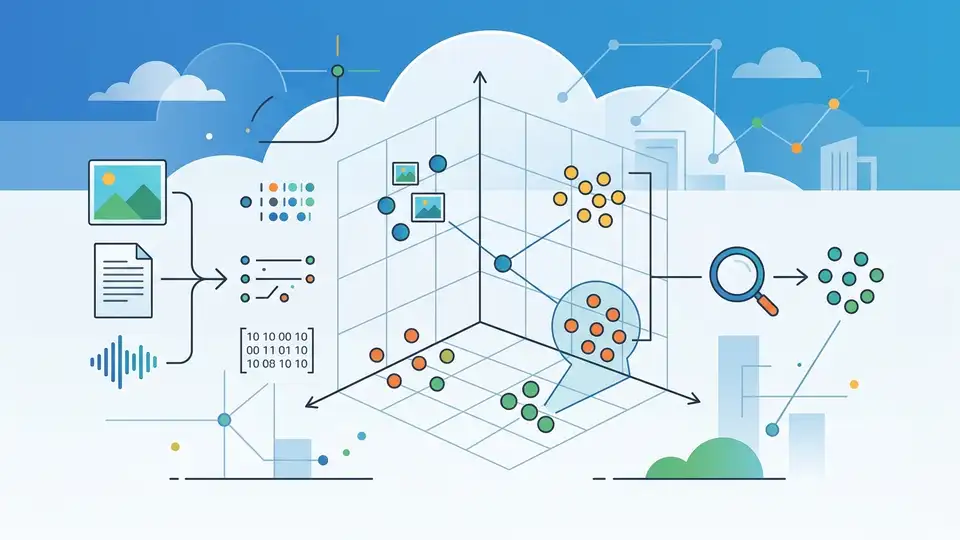
AWS says vector databases store embeddings so apps can find similar data fast.
Vector databases have moved from niche infrastructure to a core piece of modern AI apps. AWS says they store vectors as high-dimensional points, then use nearest-neighbor search to find items with similar meaning, not just matching words.
That matters because embeddings now sit behind image search, semantic search, recommendation systems, and chatbots that need external knowledge. If your app has text, images, audio, or documents, a vector database is often the part that makes those assets searchable in a useful way.
| Topic | AWS detail |
|---|---|
| Storage model | Vectors stored as high-dimensional points |
| Indexing methods | k-NN, HNSW, IVF |
| Bedrock recommendation | Amazon OpenSearch Service |
| MemoryDB claim | Millions of vectors, single-digit millisecond responses, tens of thousands of QPS, >99% recall |
What a vector database actually does
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
A vector database stores embeddings, which are numeric representations of content produced by machine learning models. Those embeddings encode meaning and context, so the database can compare items by distance in vector space rather than by exact keyword matches.
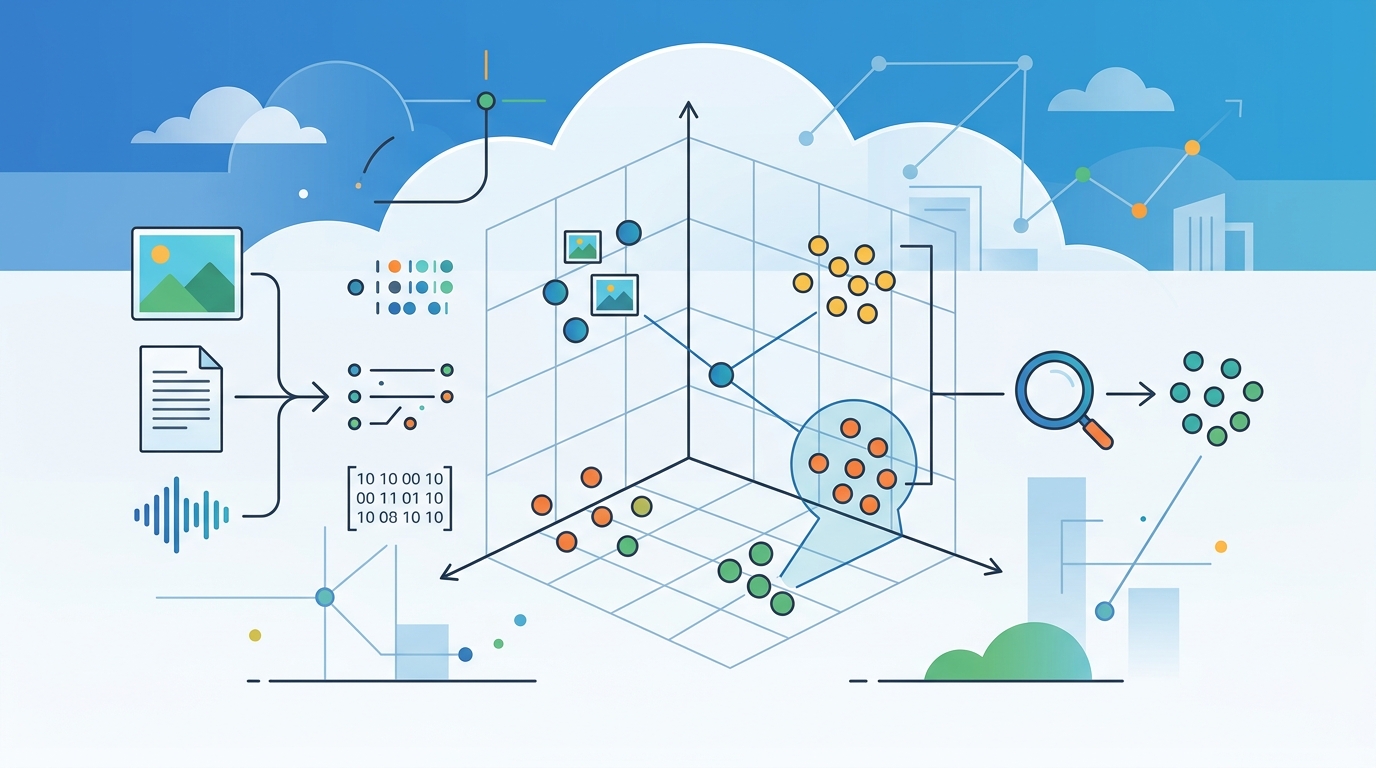
AWS describes the core job simply: store vectors, retrieve vectors, and find nearest neighbors quickly. Under the hood, vector databases rely on indexes such as k-nearest neighbor, Hierarchical Navigable Small World, and Inverted File Index to make similarity search fast enough for production use.
That matters because raw vector search is expensive if you do it naively. The database layer adds indexing, query planning, access control, fault tolerance, and data management, which turns a math trick into infrastructure teams can ship with.
- Vectors can represent text, images, audio, and scanned documents.
- Similarity search can power photo lookup and semantic search.
- Database features reduce the burden of building on top of plain k-NN indexes.
Why AWS thinks vector databases matter
The AWS article makes a practical argument: embeddings are useful only when developers can operationalize them. A vector database gives teams a place to index embeddings, query them, and combine them with metadata for hybrid search.
That hybrid approach is where the tech gets interesting. You can search by meaning and by keywords at the same time, then rank results with both vector similarity and term-based scoring such as BM25. For many products, that produces results users trust more than pure semantic search.
Vector databases also help with a problem that shows up in generative AI: hallucinations. AWS says an external knowledge base can support chatbots and improve trustworthiness, which is why retrieval-augmented systems have become so common in production AI stacks.
"OpenSearch Service offers a scalable and high-performance vector database enabling vector-driven search capabilities." — Amazon Web Services
That quote matters because it shows AWS is not treating vector search as a side feature. It is positioning OpenSearch as the default place to start when Amazon Bedrock needs retrieval over embeddings.
Where teams use vector search today
AWS breaks use cases into visual, semantic, multimodal, and conversational search. Those categories cover a lot of ground, from e-commerce product discovery to enterprise knowledge assistants.
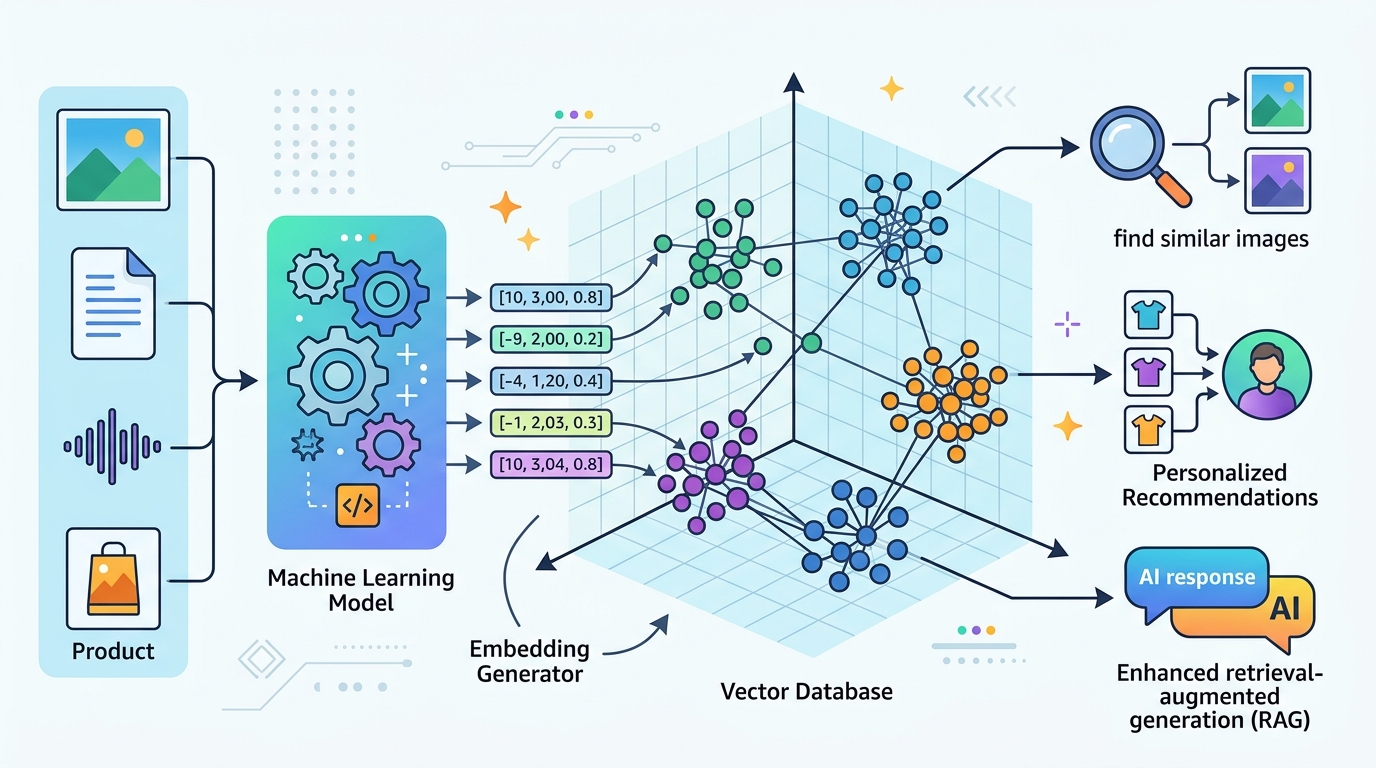
The workflow is fairly consistent. A model turns a corpus into embeddings, the app hydrates the database with those vectors, and later the app encodes a user query or image and asks for nearest neighbors. The database returns similar items, often with metadata filters layered on top.
For teams already running data systems, AWS points to several paths. Amazon OpenSearch Service is the Bedrock recommendation, while Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL-Compatible Edition support the pgvector extension. Amazon MemoryDB supports millions of vectors with single-digit millisecond query and update response times, and Amazon DocumentDB adds vector search with millisecond latency.
- OpenSearch Service: AWS’s recommended option for Bedrock vector workloads.
- PostgreSQL with pgvector: useful when embeddings live near relational data.
- MemoryDB and DocumentDB: options for low-latency search at scale.
What the numbers say about the tradeoffs
The real story is not that vector databases exist. It is that AWS is packaging several different storage choices around the same retrieval problem, each with different latency and operational goals.
Here is the comparison that matters: OpenSearch Service is the general-purpose recommendation for Bedrock; MemoryDB targets very fast reads and updates with tens of thousands of queries per second; DocumentDB is aimed at teams that want vector search inside a document database; PostgreSQL with pgvector fits teams that already trust relational systems.
That spread tells you something about the market. Vector search is no longer a single-purpose add-on. It is becoming a feature that sits inside search engines, relational stores, document stores, and in-memory databases, depending on where the data already lives.
- OpenSearch Service: best fit for Bedrock-centric search and chatbot retrieval.
- MemoryDB: millions of vectors, single-digit millisecond responses, >99% recall.
- DocumentDB: vector search with millisecond response times for MongoDB-compatible workloads.
- pgvector: a practical choice when embeddings belong next to SQL data.
Why this matters for builders
If you are building AI features today, vector databases are less about theory and more about reducing friction. They let teams store embeddings, search by meaning, filter by metadata, and keep retrieval logic in a system that already handles access control and scaling.
The bigger takeaway is that vector search is becoming standard plumbing for AI apps. The next question for most teams is not whether to use embeddings, but where to keep them and how much operational complexity they want to own.
For many AWS users, the answer will be OpenSearch Service for Bedrock, or pgvector if the embeddings belong in PostgreSQL. If your data already sits in Amazon S3, Aurora, or MemoryDB, the right choice is often the one that keeps retrieval close to the data you already manage.
My bet: the next wave of AI products will treat vector search the way web apps treat SQL today, as a default building block rather than a special feature.
// Related Articles
- [TOOLS]
Aliyun Bailian Token Plan turns credits into agents
- [TOOLS]
One API gateway turns six AI APIs into one
- [TOOLS]
OpenAI FDEs turn broken agents into shipped systems
- [TOOLS]
Anthropic’s daily brief turns news into a workflow
- [TOOLS]
Claude Reflect turns usage into retention
- [TOOLS]
Midjourney turns prompt ideas into art